- 1. 前言
- 2. 模型参数量
文章内容主要摘自:https://zhuanlan.zhihu.com/p/624740065
1. 前言
最近,OpenAI推出的ChatGPT展现出了卓越的性能,引发了大语言模型(Large Language Model, LLM)的研究热潮。大规模语言模型的“大”体现在两个方面:模型参数规模大,训练数据规模大。以GPT3为例,GPT3的参数量为1750亿,训练数据量达到了570GB。进而,训练大规模语言模型面临两个主要挑战:显存效率和计算效率。
现在业界的大语言模型都是基于transformer模型的,模型结构主要有三大类:
- encoder-decoder(代表模型是T5)、
- encoder-only(代表模型是BERT,也叫Masked-Language Model,MLM)以及
- decoder-only,具体的,decoder-only结构又可以分为Causal LM(因果语言模型-自回归的预测,代表模型是GPT系列)和Prefix LM(代表模型是GLM,UniLM)。归因于GPT系列取得的巨大成功,大多数的主流大语言模型都采用Causal LM结构。
-

因此,针对decoder-only框架,为了更好地理解训练训练大语言模型的显存效率和计算效率,本文分析采用decoder-only框架来分析transformer模型的模型参数量、计算量、中间激活值、KV cache。
Transformer 原始架构和decoder-only架构的GPT对比:
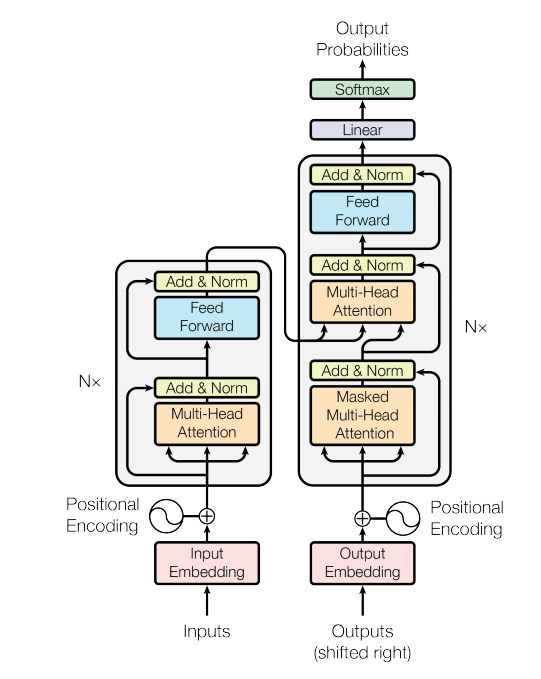
为了方便分析,先定义好一些数学符号。记transformer模型的层数为 l l l ,隐藏层维度为 h h h ,注意力头数为 a a a 。词表大小为 V V V ,训练数据的批次大小为 b b b ,序列长度为 s s s 。
2. 模型参数量
decoder-only架构的大模型有两部分组成,输入&输出的词嵌入层(大部分模型词嵌入层共享参数)以及堆叠 l l l层的transformer块。
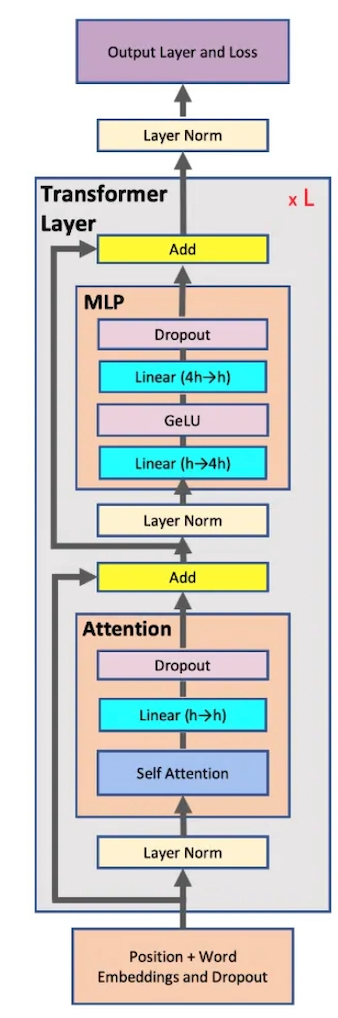
transformer块(上图2所示)由两部分组成:Attention和FFN(MLP),其中穿插了两层LN(Pre-Norm)。
- Attention模块模型参数包括将输入投影为 Q , K , V Q,K,V Q,K,V的权重矩阵 W Q , W K , W V W_Q,W_K,W_V WQ,WK,WV 和偏置,输出矩阵为 W O W_O WO 和偏置,四个权重矩阵的size为 h × h h\times h h×h,四个偏置的size为 h h h。忽略激活函数,此时Attention模块的参数量为 4 h 2 + 4 h 4h^2+4h 4h2+4h,参数量来源于线性层投影矩阵。
- FFN模块,由两个线性层组成,第一个线性层: $h \rightarrow 4h $ 权重矩阵和偏置分别为 h × 4 h , 4 h h \times 4h,4h h×4h,4h,第二个线性层: 4 h → h 4h \rightarrow h 4h→h 的权重矩阵和参数量为 4 h × h , h 4h \times h,h 4h×h,h。忽略激活函数,此时FFN模块的参数量为 8 h 2 + 5 h 8h^2+5h 8h2+5h。
- 两个LN层,包含了2个可训练模型参数:缩放参数 γ \gamma γ和平移参数 β \beta β ,形状都是 h h h 。2个layer normalization的参数量为 4 h 4h 4h 。
此外,还包括一个输入输出的词嵌入层,词嵌入层的参数量取决于输入字典的大小 V V V, 参数量为 V h Vh Vh
关于位置编码,如果采用可训练式的位置编码,会有一些可训练模型参数,数量比较少。如果采用相对位置编码,例如RoPE和ALiBi,则不包含可训练的模型参数。我们忽略这部分参数。
综上Transformer decoder模型的**参数量为 12 l h 2 + 13 l h + V h 12lh^2+13lh+Vh 12lh2+13lh+Vh**。当隐藏维度 h h h 较大时,可以忽略一次项,模型参数量近似为 12 l h 2 12lh2 12lh2 。










![[YM]课设-C#-WebApi-Vue-员工管理系统 (五)登录](https://i-blog.csdnimg.cn/direct/1fbf3b6b48934a5ca1d848cacedb6e4d.png)



![[Leetcode 216][Medium]组合总和 III--回溯](https://i-blog.csdnimg.cn/direct/8dada381aa1d456ba1a8aa9456a676bd.png)



