文章目录
- 1.多级部署
- 2.实现请求计数器
- 3.负载均衡
- 3.1服务端负载均衡
- 3.2客户端负载均衡
- 3.3自定义负载均衡
- 3.4负载均衡策略
- 3.5 LoadBalance 原理
- 4.部署实现
大家好,我是晓星航。今天为大家带来的是 负载均衡 相关的讲解!😀
1.多级部署
复制一个子工程:
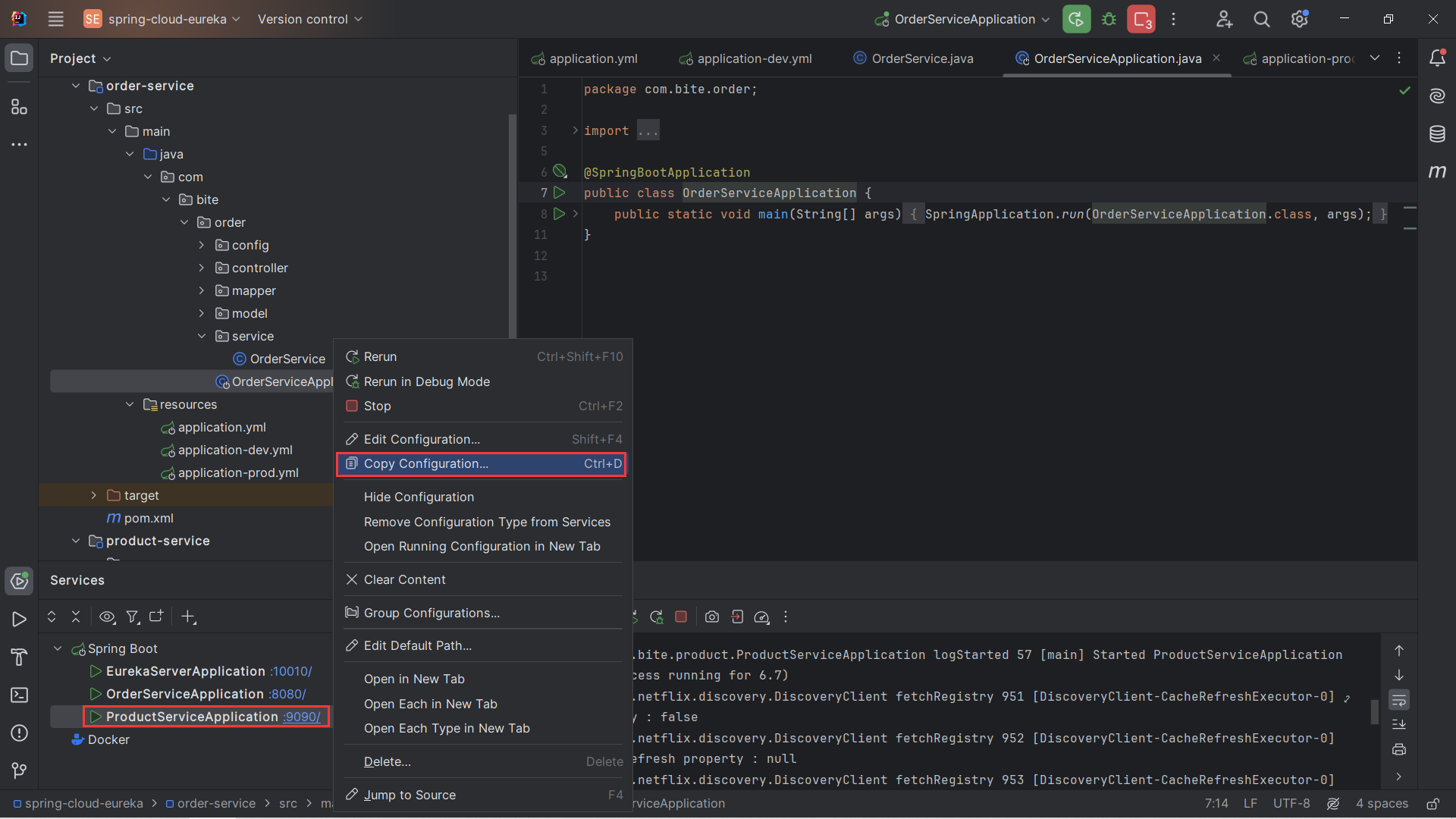
并将复制后的新项目修改命名,更改端口号

先点击Modify options选项

选择Add VM options
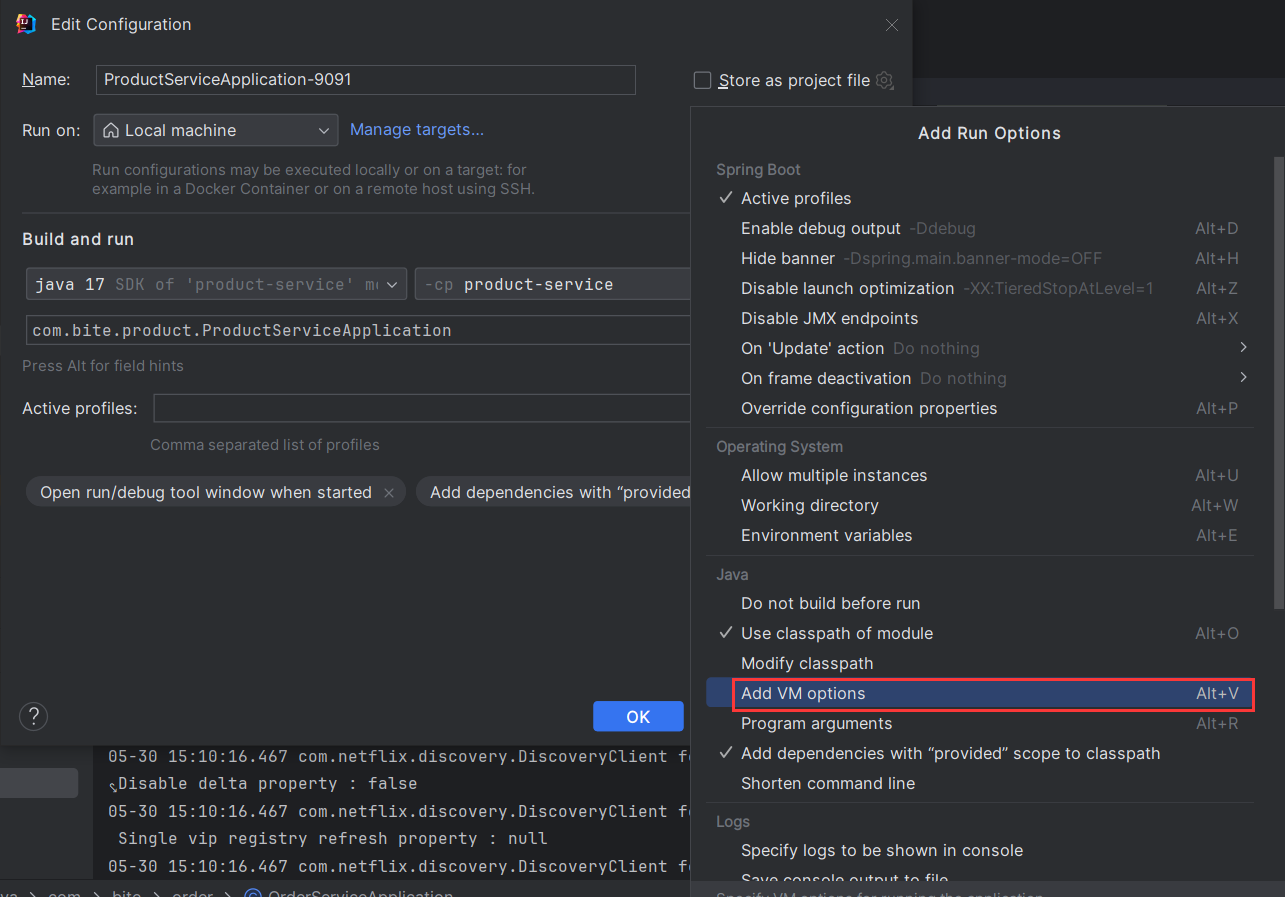
然后输入 -Dserver.port=9091 便可将端口号成功改为9091

可以看到,此时我们就复制出了一个新的ProductServiceApplication工程,并且它的端口号为9091.
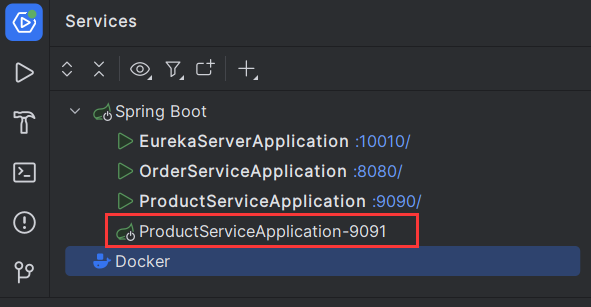
按照上述方法再配置一个9092端口的ProductServiceApplication工程,此时两个示例就已经配置完毕。

然后我们选中刚创建的两个新子工程并启动(Run),回到Eureka页面观察启动情况

我们刷新一下之后发现,此时我们9091和9092在Eureka中也成功启动了

2.实现请求计数器
初始化代码提出来单独写是因为,我们要保证结果每次都是一致的

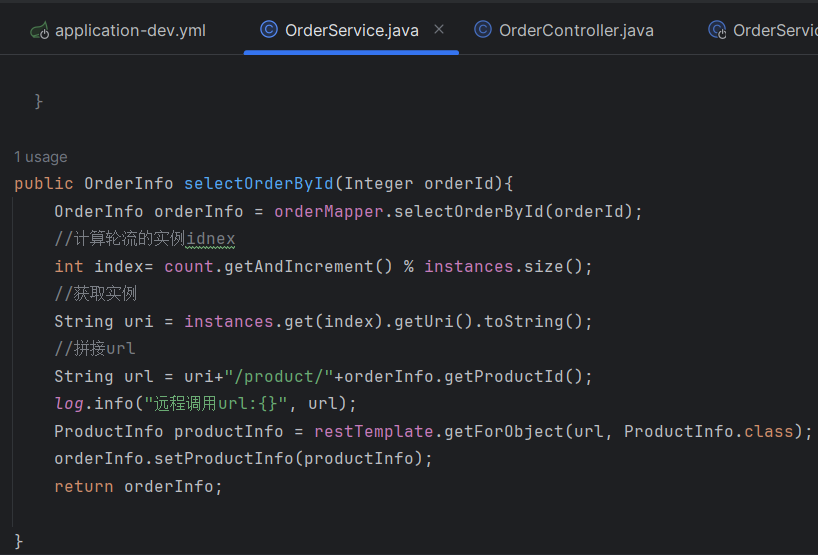

上述代码会导致我们服务器或者组件因为承受过多的请求和流量而出现过载现象,导致服务性能下降甚至崩溃。
3.负载均衡
为了解决流量过大导致单个服务器或者组件过载问题,因此我们学习负载均衡来解决上述问题
负载均衡(Load Balance,简称 LB),是高并发,高可用系统必不可少的关键组件
当服务流量增大时,通常会采用增加机器的方式进行扩容,负载均衡就是用来在多个机器或者其他资源中,**按照一定的规则(按照什么样的策略进行负载的分配)**合理分配负载.
一个团队最开始只有一个人,后来随着工作量的增加,公司又招聘了几个人,负载均衡就是:如何把工作量均衡的分配到这几个人身上,以提高整个团队的效率

3.1服务端负载均衡
在服务端进行负载均衡的算法分配
比较有名的服务端负载均衡器是Nginx。请求先到达Nginx负载均衡器,然后通过负载均衡算法,在多个服务器之间选择一个进行访问。

3.2客户端负载均衡
在客户端进行负载均衡的算法分配
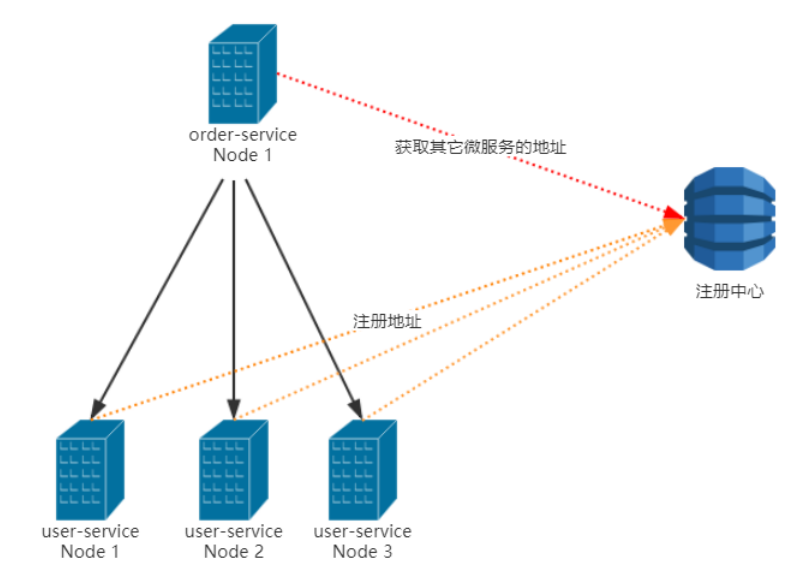
把负载均衡的功能以库的方式集成到客户端,而不再是由一台指定的负载均衡设备集中提供
比如Spring Cloud的Ribbon,请求发送到客户端,客户端从注册中心(比如Eureka)获取服务列表,在发送请求前通过负载均衡算法选择一个服务器,然后进行访问.
Ribbon是Spring Cloud早期的默认实现,由于不维护了,所以最新版本的Spring Cloud负载均衡集成的是Spring Cloud LoadBalancer(Spring Cloud官方维护)
3.3自定义负载均衡
SpringCloud LoadBalance
1.添加注解
2.修改远程调用代码,把IP和端口号改成应用名
自定义负载均衡策略



使用完负载均衡后,我们这里几个服务的流量分配明显变均匀了,不会有一个过多另一个过少的情况
3.4负载均衡策略
负载均衡策略是一种思想,无论是哪种负载均衡器,它们的负载均衡策略都是相似的.Spring Cloud ,LoadBalancer 仅支持两种负载均衡策略:轮询策略 和随机策略
1.轮询(Round Robin):轮询策略是指服务器轮流处理用户的请求,这是一种实现最简单,也最常用的策略.生活中也有类似的场景,比如学校轮流值日,或者轮流打扫卫生
2.随机选择(Random):随机选择策略是指随机选择一个后端服务器来处理新的请求.
3.5 LoadBalance 原理
源码学习:
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.springframework.cloud.client.loadbalancer;
import java.io.IOException;
import java.net.URI;
import org.springframework.http.HttpRequest;
import org.springframework.http.client.ClientHttpRequestExecution;
import org.springframework.http.client.ClientHttpRequestInterceptor;
import org.springframework.http.client.ClientHttpResponse;
import org.springframework.util.Assert;
public class LoadBalancerInterceptor implements ClientHttpRequestInterceptor {
private LoadBalancerClient loadBalancer;
private LoadBalancerRequestFactory requestFactory;
public LoadBalancerInterceptor(LoadBalancerClient loadBalancer, LoadBalancerRequestFactory requestFactory) {
this.loadBalancer = loadBalancer;
this.requestFactory = requestFactory;
}
public LoadBalancerInterceptor(LoadBalancerClient loadBalancer) {
this(loadBalancer, new LoadBalancerRequestFactory(loadBalancer));
}
public ClientHttpResponse intercept(final HttpRequest request, final byte[] body, final ClientHttpRequestExecution execution) throws IOException {
URI originalUri = request.getURI();
String serviceName = originalUri.getHost();
Assert.state(serviceName != null, "Request URI does not contain a valid hostname: " + originalUri);
return (ClientHttpResponse)this.loadBalancer.execute(serviceName, this.requestFactory.createRequest(request, body, execution));
}
}

按住Ctrl键进入execute方法查看原理
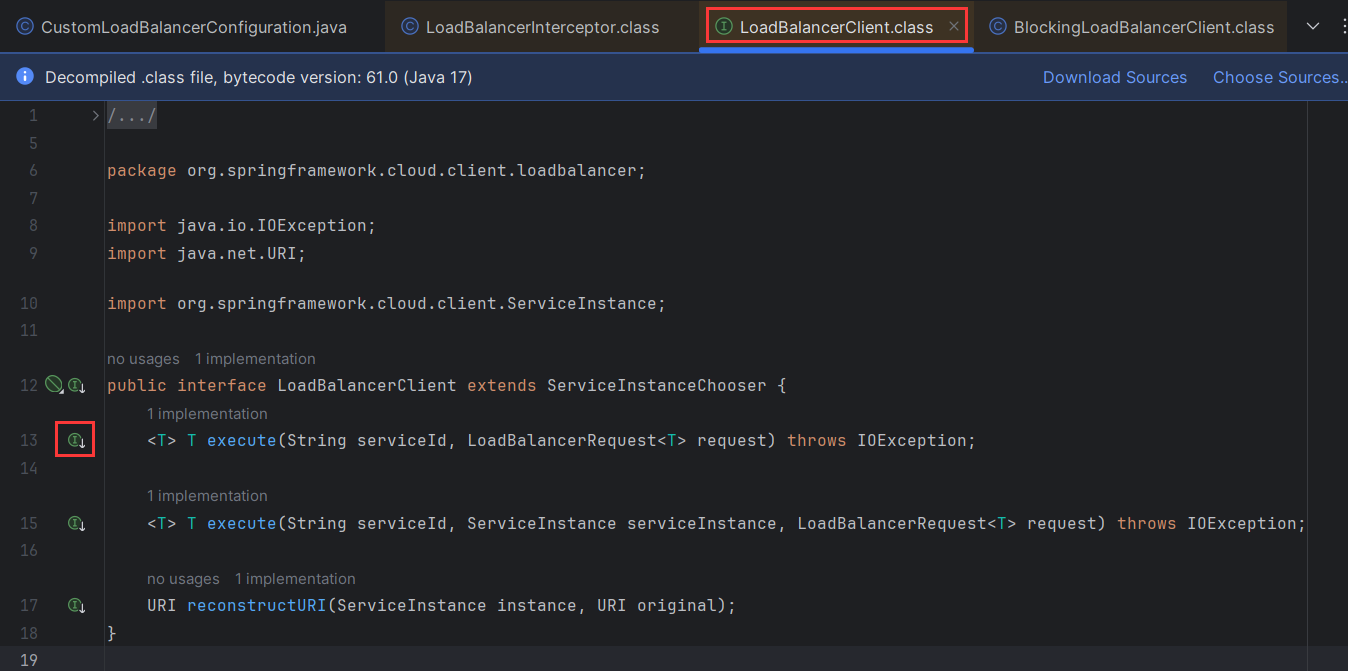
然后点一下绿色的I下标,我们可以进入里面查看具体的实现

点进choose中查看choose的实现

4.部署实现
使用idea的maven进行服务打包,把我们需要部署的三个文件都package打包一下


然后将我们提前准备好的数据库建库插入数据代码在我们的云服务器上运行一遍,提前将数据输入进去
-- 订单服务
-- 建库
create database if not exists cloud_order charset utf8mb4;
use cloud_order;
-- 订单表
DROP TABLE IF EXISTS order_detail;
CREATE TABLE order_detail (
`id` INT NOT NULL AUTO_INCREMENT COMMENT '订单id',
`user_id` BIGINT ( 20 ) NOT NULL COMMENT '用户ID',
`product_id` BIGINT ( 20 ) NULL COMMENT '产品id',
`num` INT ( 10 ) NULL DEFAULT 0 COMMENT '下单数量',
`price` BIGINT ( 20 ) NOT NULL COMMENT '实付款',
`delete_flag` TINYINT ( 4 ) NULL DEFAULT 0,
`create_time` DATETIME DEFAULT now(),
`update_time` DATETIME DEFAULT now(),
PRIMARY KEY ( id )) ENGINE = INNODB DEFAULT CHARACTER
SET = utf8mb4 COMMENT = '订单表';
-- 数据初始化
insert into order_detail (user_id,product_id,num,price)
values
(2001, 1001,1,99), (2002, 1002,1,30), (2001, 1003,1,40),
(2003, 1004,3,58), (2004, 1005,7,85), (2005, 1006,7,94);
-- 产品服务
create database if not exists cloud_product charset utf8mb4;
-- 产品表
use cloud_product;
DROP TABLE IF EXISTS product_detail;
CREATE TABLE product_detail (
`id` INT NOT NULL AUTO_INCREMENT COMMENT '产品id',
`product_name` varchar ( 128 ) NULL COMMENT '产品名称',
`product_price` BIGINT ( 20 ) NOT NULL COMMENT '产品价格',
`state` TINYINT ( 4 ) NULL DEFAULT 0 COMMENT '产品状态 0-有效 1-下架',
`create_time` DATETIME DEFAULT now(),
`update_time` DATETIME DEFAULT now(),
PRIMARY KEY ( id )) ENGINE = INNODB DEFAULT CHARACTER
SET = utf8mb4 COMMENT = '产品表';
-- 数据初始化
insert into product_detail (id, product_name,product_price,state)
values
(1001,"T恤", 101, 0), (1002, "短袖",30, 0), (1003, "短裤",44, 0),
(1004, "卫衣",58, 0), (1005, "马甲",98, 0),(1006,"羽绒服", 101, 0),
(1007, "冲锋衣",30, 0), (1008, "袜子",44, 0), (1009, "鞋子",58, 0),
(10010, "毛衣",98, 0);
然后打开我们刚才打包好的路径,然后将打包完毕的三个文件采用拖动的方式上传到我们的云服务器中(注意这里我们提前新建好一个文件spring_cloud并进入,将所有订单服务所需的jar包都传入这里,方便我们后期查找)
上传完毕后,我们采用后台启动的方式 ,并输出日志到logs/order.log
创建logs文件夹 --> mkdir logs/
启动三个服务:
nohup java -jar eureka-server.jar >logs/eureka.log &
nohup java -jar order-server.jar >logs/order.log &
nohup java -jar product-server.jar >logs/product-9090.log &
再多启动两台product-service实例:
#启动实例,指定端口号为9091
nohup java -jar product-server.jar --server.port=9091>logs/product-9091.log &
#启动实例,指定端口号为9092
nohup java -jar product-server.jar --server.port=9092>logs/product-9092.log &
此时我们启动了1个eureka服务中心,启动了1个订单服务,启动了3个商品服务
如果此时我们访问不了我们的网页,我们要去云服务器上开放端口号,直接将我们使用的端口号改为允许通过即可
product-server.jar --server.port=9091>logs/product-9091.log &
#启动实例,指定端口号为9092
感谢各位读者的阅读,本文章有任何错误都可以在评论区发表你们的意见,我会对文章进行改正的。如果本文章对你有帮助请动一动你们敏捷的小手点一点赞,你的每一次鼓励都是作者创作的动力哦!😘