文末赠免费精品编程资料~~
大家好,今天给大家简单分享几个好用的Pandas数据处理函数。
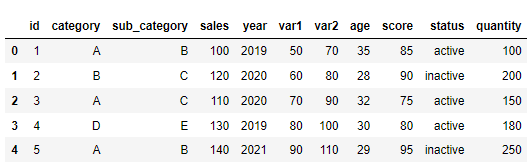
id,category,sub_category,sales,year,var1,var2,age,score,status,quantity
1,A,B,100,2019,50,70,35,85,active,100
2,B,C,120,2020,60,80,28,90,inactive,200
3,A,C,110,2020,70,90,32,75,active,150
4,D,E,130,2019,80,100,30,80,active,180
5,A,B,140,2021,90,110,29,95,inactive,250
以上模拟数据可以复制后使用pd.read_clipboard(sep=',')读取。
1. melt 和 pivot
melt 场景:假设原始数据集中var1和var2代表产品在不同季度的销售额,我们可以将这两列扁平化,方便后续针对季度进行分析或绘制折线图。
# 扁平化季度销售额数据
df_melted = pd.melt(df, id_vars=['id', 'category', 'sub_category', 'year'], value_vars=['var1', 'var2'], var_name='quarter', value_name='quarter_sales')
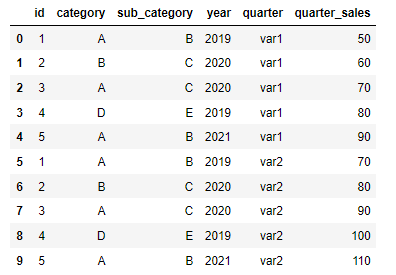
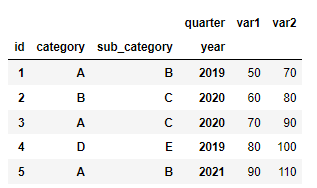
pivot 场景:完成分析或可视化后,可能需要将扁平化的数据恢复原样。
# 将扁平化的季度销售额数据恢复为宽格式
df_pivoted = df_melted.pivot(index=['id', 'category', 'sub_category', 'year'], columns='quarter', values='quarter_sales')
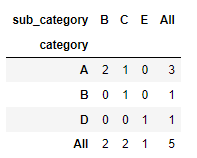
2. crosstab
crosstab 场景:若我们要分析不同类别产品在子类别中的分布情况,可以创建交叉表。
# 创建 category 和 sub_category 的交叉表并显示频数
cross_tab = pd.crosstab(df['category'], df['sub_category'], margins=True)
cross_tab
3. between
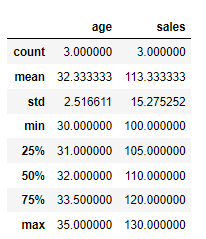
between 场景:在进行数据分析时,我们可能只关心某个年龄段的客户数据,比如筛选出20到40岁的活跃用户及其购买情况。
# 筛选出年龄在20至40岁并且状态为 active 的用户及其销售额
df_filtered = df[(df['age'].between(20, 40)) & (df['status'] == 'active')]
# 分析这部分用户的销售额分布
df_filtered[['age', 'sales']].describe()
4. clip
clip 场景:在对用户评分进行分析时,可能存在录入错误导致的过高或过低评分,我们可以对其进行合理限制。
# 限制 score 列的值在0到100之间
df['score'].clip(lower=0, upper=100, inplace=True)
# 验证处理效果并计算修正后的评分平均值
print("修正后的评分平均值:", df['score'].mean())
![]()
5. replace
replace 场景:在进行用户状态分类时,可能会统一更改某些状态标签以便于后续分析,例如将'inactive'改为'not_active'。
# 将用户状态'inactive'替换为'not_active'
df['status'].replace(to_replace='inactive', value='not_active', inplace=True)
# 分别计算新旧标签下用户的状态分布
df['status'].value_counts()
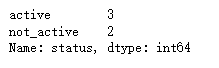
文末福利
如果你对Python感兴趣的话,可以试试我整理的这一份全套的Python学习资料,【点击这里】免费领取!
包括:Python激活码+安装包、Python
web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习
⑤ 历年互联网企业Python面试真题,复习时非常方便









![Cadence高速板设计技巧(全志H3)[三]](https://i-blog.csdnimg.cn/direct/5aedfdaa2a6b4324b549b49cbb36c55f.png)










