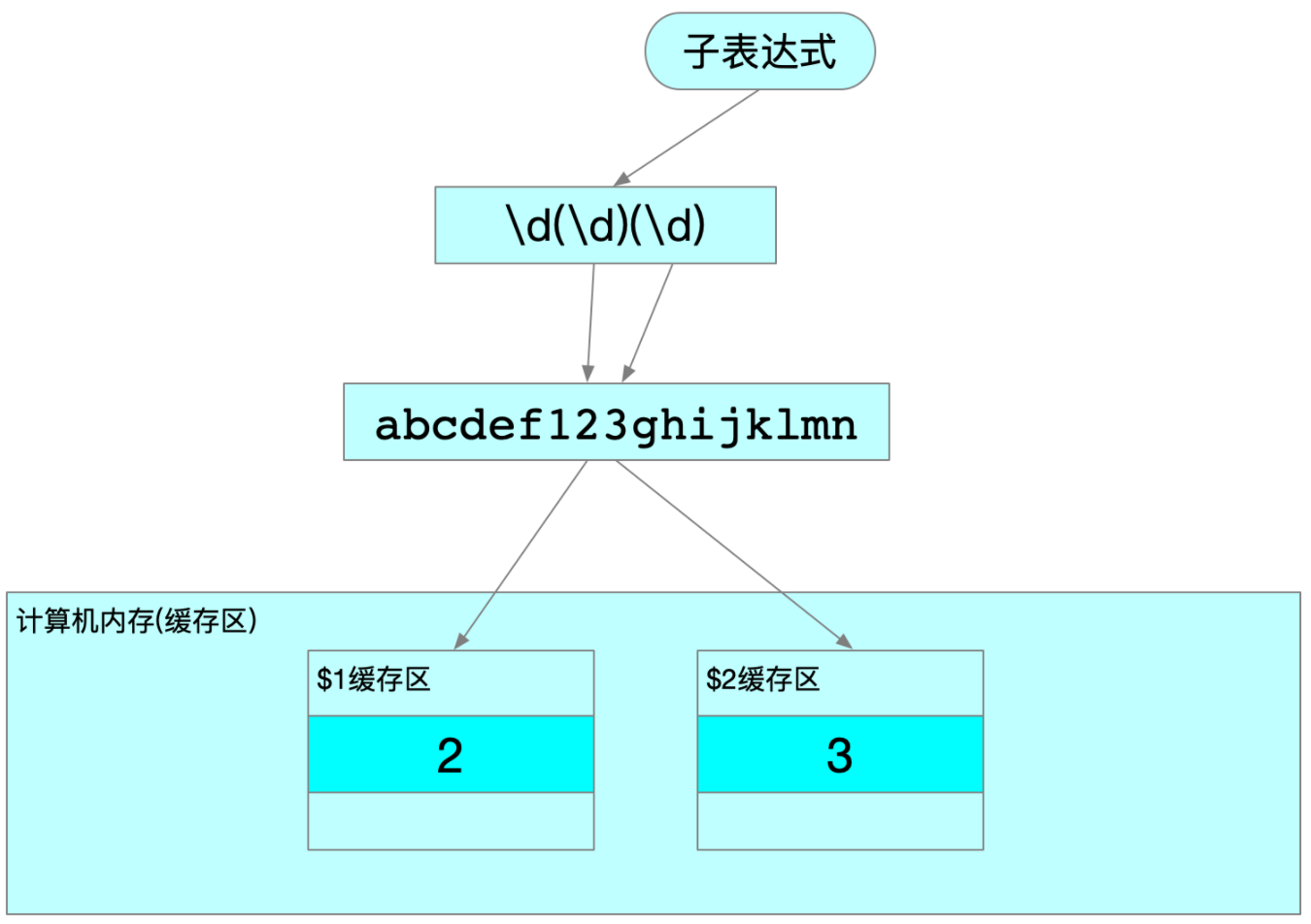
我 的 个 人 主 页:👉👉 失心疯的个人主页 👈👈
入 门 教 程 推 荐 :👉👉 Python零基础入门教程合集 👈👈
虚 拟 环 境 搭 建 :👉👉 Python项目虚拟环境(超详细讲解) 👈👈
PyQt5 系 列 教 程:👉👉 Python GUI(PyQt5)文章合集 👈👈
Oracle数据库教程:👉👉 Oracle数据库文章合集 👈👈
优 质 资 源 下 载 :👉👉 资源下载合集 👈👈
优 质 教 程 推 荐:👉👉 Python爬虫从入门到入狱系列 合集👈👈


web请求全过程剖析
- web请求全过程剖析(重点)
- 前言
- 页面渲染过程
- 页面渲染过程
- 服务器端渲染数据
- 前端JS渲染
- 页面嵌套加载
- 浏览器工具的使用(重点)
- 初识Chrome
- 工具介绍
- 总结
web请求全过程剖析(重点)
前言
-
本小节给各位好好剖析一下web请求的全部过程,这样有助于后面我们遇到的各种各样的网站就有了入手的基本准则了.
-
那么到底我们浏览器在输入完网址到我们看到网页的整体内容,这个过程中究竟发生了些什么?
-
这里我们以百度为例
- 在访问百度的时候,浏览器会把这一次请求发送到百度的服务器(百度的一台电脑),由服务器接收到这个请求, 然后加载一些数据. 返回给浏览器, 再由浏览器进行显示
- 听起来好像是个废话…但是这里蕴含着一个极为重要的东西在里面
- 注意
- 百度的服务器返回给浏览器的不直接是页面, 而是页面源代码(由html, css, js组成)
- 由浏览器把页面源代码进行执行, 然后把执行之后的结果展示给用户
- 所以我们能看到在上一节的内容中,我们拿到的是百度的源代码(就是那堆看不懂的鬼东西)
- 具体过程如图.
-
接下来就是一个比较重要的事情了,所有的数据都在页面源代码里么? 非也~
-
这里要介绍一个新的概念:页面渲染过程

页面渲染过程
页面渲染过程
- 我们常见的页面渲染过程有两种
- 服务器端渲染数据:你需要的数据直接在页面源代码里能搜到
- 前端JS渲染数据:你需要的数据在页面源代码里搜不到
- 页面嵌套加载:页面通过iframe或者frameset嵌套结构加载进来
服务器端渲染数据
-
你需要的数据直接在页面源代码里能搜到(这个最容易理解, 也是最简单的)
-
就是我们在请求到服务器的时候,服务器直接把数据全部写入到html中,我们浏览器就能直接拿到带有数据的html内容.
-
比如
-
由于数据是直接写在html中的,所以我们能看到的数据都在页面源代码中能找的到的.这种网页一般都相对比较容易就能抓取到页面内容.

前端JS渲染
-
你需要的数据在页面源代码里搜不到
-
这种就稍显麻烦了,这种机制一般是第一次请求服务器返回一堆HTML框架结构
-
然后再次请求到真正保存数据的服务器,由这个服务器返回数据,最后在浏览器上对数据进行加载.
-
就像这样:
-
这样做的好处是服务器那边能缓解压力,而且分工明确,比较容易维护
-
典型的有这么一个网页
-
那数据是何时加载进来的呢?
-
其实就是在我们进行页面向下滚动的时候,jd就在偷偷的加载数据了,此时想要看到这个页面的加载全过程, 我们就需要借助浏览器的调试工具了(F12)
-
看到了吧, 页面上看到的内容其实是后加载进来的.
-
在这里我不是要跟各位讲jd有多牛B, 也不是说这两种方式有什么不同, 只是想告诉各位,:
- 有些时候, 我们的数据不一定都是直接来自于页面源代码.
- 如果你在页面源代码中找不到你要的数据时, 那很可能数据是存放在另一个请求里.






页面嵌套加载
- 有一些页面通过iframe或者frameset嵌套结构将其他网页加载进来
- 总结
- 你要的东西在页面源代码,直接拿
源代码提取数据即可 - 你要的东西,不在页面源代码, 需要想办法找到真正的加载数据的那个请求,然后提取数据
- 页面嵌套加载,找到iframe的src,把这个src当做一个新的url进行请求抓取
- 你要的东西在页面源代码,直接拿
浏览器工具的使用(重点)
初识Chrome
- Chrome是一款非常优秀的浏览器,不仅仅体现在用户使用上,对于我们开发人员而言也是非常非常好用
- 对于一名爬虫工程师而言,浏览器是最能直观的看到网页情况以及网页加载内容的地方
- 我们可以按下F12来查看一些普通用户很少能使用到的工具
- 如果开发者工具打开之后是中文,点击右上角齿轮图标,修改
语言选项为:英语(美国)- English (Us),然后重新打开开发者工具,就变成英文版了 - 其中, 最重要的
Elements、Console、Sources、Network. Elements是我们实时的网页内容情况,- 注意:到了后期,很多人非常容易混淆
Elements以及页面源代码之间的关系1. 页面源代码是执行js脚本以及用户操作之前的服务器返回给我们最原始的内容 2. Elements中看到的内容是js脚本以及用户操作之后的当时的页面显示效果 - 你可以理解为
- 一个是老师批改之前的卷子(页面源代码)
- 一个是老师批改之后的卷子(Elements)
- 虽然都是卷子,但是内容是不一样的,而我们目前能够拿到的都是页面源代码,也就是老师批改之前的样子,这一点要格外注意。

工具介绍
-
Elements
- 网页,鼠标右键 —— 查看网页源代码,查看的是网页源代码
- Elements显示的是经过浏览器本身执行过一些脚本之后的内容,并非页面源代码
- 通过网络请求,拿到一堆页面源代码 ——> 浏览器执行一些脚本 ——> elements
- 在浏览器运行脚本之后,很有可能会改变页面源代码的一些结构
- elements显示的是页面当前的状态
- elements 与 页面源代码 不是一码事
- 我们通过程序拿到的是“页面源代码”
- 要拿到elements内容,需要通过selenium或者自动化工具调用浏览器
- 在Elements中我们可以使用左上角的小箭头,快速定位到浏览器中每一块内容对应在Elements中当前html位置
-
elements主要用来查看页面的结构,但是仅仅只是做参考,并不能以这个为准!必须以页面源代码为准!
-
可以通过elements来删除页面加载出来的广告什么的
-
Console
- 是一个控制台,我们可以在这里输入一些js代码自动执行(js逆向的时候会用到这里)
- 可以用来查看程序员留下的一些打印内容, 以及日志内容。
-
Source
- 这里能看到该网页打开时加载的所有资源内容
- 包括页面源代码、脚本、样式、图片等等全部内容

- Source里面看到的页面源代码跟在网页鼠标右键查看源代码是同一个东西
-
Network
- 我们一般习惯称呼它为抓包工具。
- 在这里我们能看到当前网页加载的所有网路网络请求,以及请求的详细内容
- 这一点对我们爬虫来说至关重要
-
使用Network抓包,需要勾选Preserver log选项(保存日志)
* 避免有些网页进行跳转,跳转的时候会加载新页面,前面的原页面加载记录丢失- 左上角放大镜按钮可以搜索到包含指定关键字的文件
- 点击文件后,再通过Ctrl+F查找关键字,可以快速找到
- Network参数说明
Preserve log勾选项 # 是否保留页面跳转之前加载的数据 Disable cache勾选项 # 是否禁止使用缓存(作用不大) No throttling # 网络速度,模拟网络很差的情况加载页面数据 Disabled No throttling # 没有阻拦 Presets Fast 3G # 快一点的3G Slow 3G # 慢一点的3G Offline # 离线 Custom Add... Filter筛选 # 筛选url资源 ALL # 显示所有请求 Fetch/XHR # 显示AJAX请求(加载的纯数据) Doc # 文档。html代码/iframe加载的内容 CSS # 显示加载的CSS文件 JS # 显示加载的JS文件 Font # 显示加载的字体文件 Img # 显示加载的图片文件 Media # 显示加载的媒体文件 Manifest # WS # 显示加载的websocket(游戏) Wasm # 显示加载的wasm文件(汇编) Other # 显示加载的其他文件 - 文件相关参数
Headers # 头相关信息(请求头、响应头) Response # 响应信息(源代码),服务器返回的内容 Preview # 预览响应内容(主要是看json数据) # 如果是图片,会直接显示图片 # 如果是html代码,会执行html。但是无脚本和样式加载 # 如果是json数据,会把json数据格式化 Initiator # 启动器,AJAX调用函数过程 Timing # 记录请求时间节点 Cookies
-
当你要找的资源内容不在源代码中的时候,就需要通过Network抓包,然后查找到包含你要的资源内容的文件,再通过文件的Headers拿到具体的请求地址request url
-
AJAX(⾳译为:阿贾克斯)
- Asynchronous JavaScript and XML(异步的 JavaScript和 XML)
- 是指⼀种创建交互式⽹页应⽤的⽹页开发技术,也就是在⽆需重新加载整个⽹页的情况下,能够更新部分⽹页的技术。
- AJAX不是新的编程语⾔,⽽是⼀种使⽤现有标准的新⽅法,是⼀种⽤于创建快速动态⽹页的技术,通过在后台与服务器进⾏少量数据交换
- AJAX 可以使⽹页实现异步更新。这意味着可以在不重新加载整个⽹页的情况下,对⽹页的某部分进⾏更新
- 传统的⽹页(不使⽤ AJAX)如果需要更新内容或者⽤户注册信息、提交表单等,必需重新加载整个⽹页页⾯。
- 所以说 AJAX 是⼀种与服务器交换数据并更新部分⽹页的艺术,因此我们必须掌握 AJAX 这种技术






总结
- 获取数据步骤
- 情况1:页面源代码中包含数据
- 1、输入一个URL地址
- 2、浏览器会发送一个请求给服务器 -> 请求
- 3、服务器接收到请求之后,组织一下数据
- 4、把数据返回给浏览器 -> 响应
- 情况2:页面源代码中没有数据(需要抓包)
- 1、输入一个URL地址
- 2、浏览器会发送一个请求给服务器 -> 请求
- 3、服务器接收到请求之后,只返回一个基本的html结构(没有数据)
- 4、浏览器有可能再一次发送请求,服务器此时返回的就是数据了(需要通过抓包来获取这一次发送请求的url)
- 5、浏览器会将html和数据进行整合,整合成我们需要的样子(在Elements里面可以看到数据,页面源代码中并没有)
- 浏览器工具
Elements # 经过脚本渲染之后的页面源码,只能做参考,不能做获取数据的标准 Network # 抓包工具,网页源码中没有数据时需要用到 Console # 控制台,调试JS代码。后期JS逆向常用 Source # 页面加载的源码,包含JS、CSS、图片等。后期JS逆向常用 - 使用Network进行抓包时,切记勾选Preserve log选项(保存加载记录),否则出现新的请求,会丢失前面请求的所有数据包
- Network界面
- 左侧是请求所有加载的数据包
- 右侧是每一个数据包相关的信息
★ Header # 头信息(含请求头、响应头等信息) ★ Response # 响应数据。真正服务器返回的数据,页面源代码 Preview # 响应数据的预览界面 Initiator # 启动器。可以看到Ajax中函数的调用过程(JS逆向中使用) Timing # 记录请求时间节点 Cookies #