目前已更新系列:
当前:Redis高级---面试总结之内存过期策略及其淘汰策略
并发编程之----线程池ThreadPoolExecutor,Excutors的使用及其工作原理
Redis高级----主从、哨兵、分片、脑裂原理-CSDN博客
计算机网络--面试知识总结一
计算机网络-----面试知识总结二
计算机网络--面试总结三(Http与Https)
计算机网络--面试总结四(HTTP、RPC、WebSocket、SSE)-CSDN博客
知识积累之ThreadLocal---InheritableThreadLocal总结
过期策略
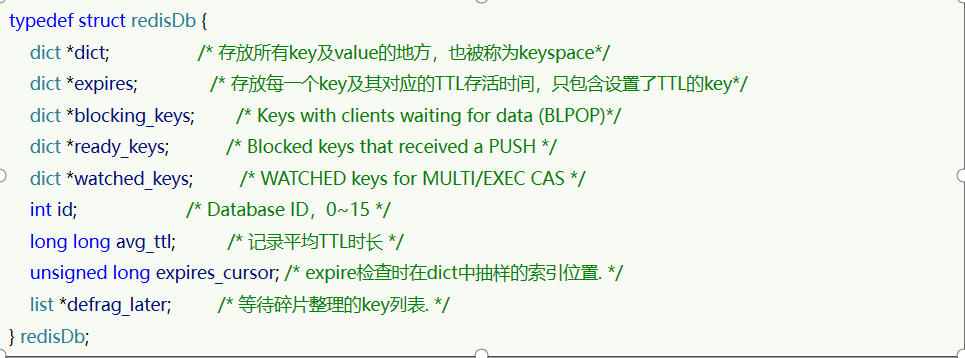
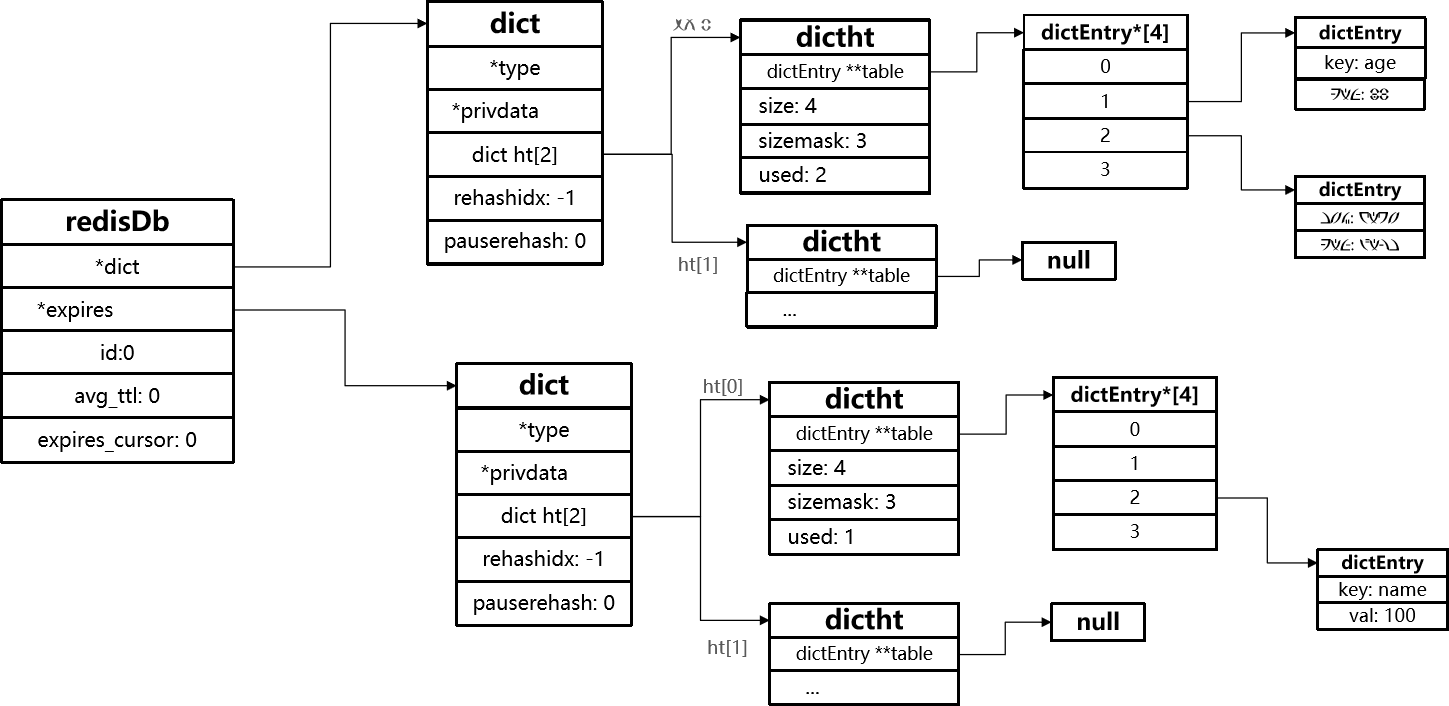
Redis中所有key-value的存储方式
Redis本身是一个典型的key-value内存存储数据库,因此所有的key、value都保存在之前学习过的Dict结构中。不过在其database结构体中,有两个Dict:一个用来记录key-value;另一个用来记录key-TTL。
- Redis怎么知道key是过期的
-
- 利用两个Dict分别记录key-value和key-ttl对
- 是不是TTL到期了就立刻删除了尼?
-
- 惰性删除
- 周期删除
两种对过期key的删除策略
惰性删除
- 概念:不是在TTL过期后就立刻删除,而是在访问一个key的时候,检查key的存活时间,如果已经过才执行删除
-
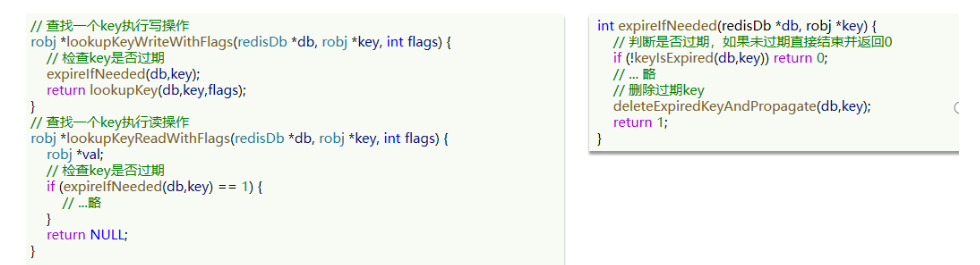
- 存在的问题,当key过期了之后,在后面很长一段时间内都没有对该key的操作,那么就不能进行惰性删除了,所以引入了一种周期删除的策略
周期性删除
- 通过一个定时任务,周期性的抽样部分过期的key,然后执行删除,随着时间的推移会去遍历数据库中不同的key直到把所有的key遍历过,因此就可以保证一个key只要是过期了的,那么早晚都会被检测到,就不会出现一个key长时间没访问导致没删除的现象,
- 执行周期有两种
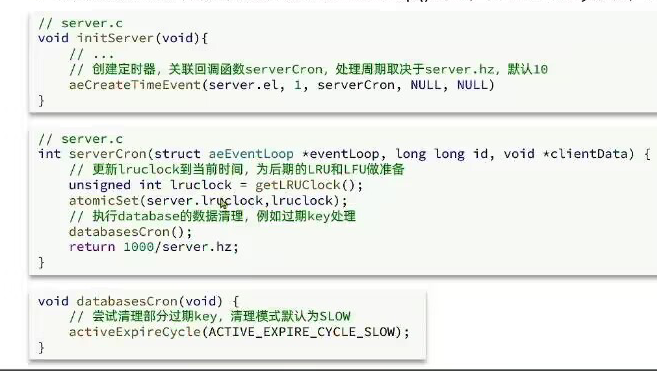
- Redis会设置一个定时任务sererCron()(在服务器初始化的时候被定义的),按照server.hz(默认是10)的频率来执行过期key的清理,模式为SLOW,低频,每次清理的多
-
- 刚开始默认初始化的时候会执行清理操作一次,以后每(1000/hz=100)100毫秒进行一次清理操作
- Redis的每个时间循环前会调用beforeSleep()函数,执行过期key清理,模式为FAST,高频清理的少
周期性删除的两种模式
SLOW模式规则:低频,清理高时长
- 执行频率受server.hz影响,默认为10,即每秒执行10次,每个执行周期100ms。
- 执行清理耗时不超过一次执行周期的25%.默认slow模式耗时不超过25ms
- 逐个遍历db,逐个遍历db中的bucket(哈希表数组的每一个下标,每一个下标上都一个一个链表),抽取20个key判断是否过期,然后将遍历到哪个buket放入到一个全局变量中,下一次就从该位置之后进行遍历处理
- 如果没达到时间上限(25ms)并且过期key比例大于10%,再进行一次抽样,否则结束
-
- 注意点:slow模式是最多25毫秒,因为当过期的key的比例小于全部key的10%那么就会提前结束
- 执行完后再清理时间到100ms的时间内就都不会再调用该模式
FAST模式规则(过期key比例小于10%不执行 ):高频,清理低时长
- 执行频率受beforeSleep()调用频率影响,但两次FAST模式间隔不低于2ms,不足2ms则直接跳过
- 执行清理耗时不超过1ms
- 逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
如果没达到时间上限(1ms)并且过期key比例大于10%,再进行一次抽样,否则结束
总结
Redis Key的TTL方式
- 在Redis中是通过一个Dict记录每个key的TTL时间
过期key的删除策略
- 惰性删除
- 定期删除
为什么要使用惰性删除+周期性删除来实现过期策略尼
- 资源利用:惰性删除和周期性删除的结合使用,使得Redis能够更加合理地利用CPU和内存资源。在不需要立即释放内存时,可以避免不必要的删除操作;在需要释放内存时,则可以通过周期性删除来清理过期的键。
- 性能影响:与立即删除相比,惰性删除和周期性删除对Redis的性能影响更小。立即删除虽然可以立即释放内存,但会占用大量的CPU资源,影响缓存的响应时间和吞吐量。而惰性删除和周期性删除则可以在不影响缓存性能的前提下,逐步释放内存。
淘汰策略
8种淘汰策略
内存淘汰:当Redis内存使用达到设置的阈值,Redis主动挑部分key删除以释放更多内存的流程
Redis会在处理客服端命令的方法processCommand()中尝试做内存淘汰
Redis会在处理客服端命令的方法processCommand()中尝试做内存淘汰

Redis的8中淘汰策略来选择删除的key
可以通过配置文件来设置
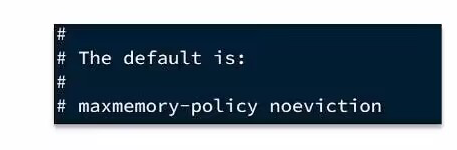
- noeviction:不淘汰任何key,但是内存满时不允许写于新的数据,默认就是这种策略
- volatile-ttl:对设置了TTL的key,比较key的剩余TT值,TTL越小越先被淘汰
- allkeys-random:对全体key,随即进行淘汰,也就是直接从db->dict中随机挑选
- volatile-random:对设置了TTL的key ,随机进行淘汰。也就是从db->expires中随机挑选。
- allkeys-lru: 对全体key,基于LRU算法进行淘汰
- volatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰
- allkeys-lfu: 对全体key,基于LFU算法进行淘汰
- volatile-lfu: 对设置了TTL的key,基于LFI算法进行淘汰
记忆技巧:
以allkeys开头的表示就是对全体key进行操作,就是直接从db->dict总进行操作
以volatile开头的就是对储存过期时间的dict中去找,也就是从db->expires中
LRU(Least Recently Used):最少最近使用。用当前时间减去最后一次访问时间,则个值越大则淘汰优先级越高
LFU(Least Frequently Used):最少频率使用。统计每个Key的访问频率,值越小淘汰优先级越高
LRU、LFU在Redis种的处理及其具体算法
那么Redis怎么去记录每一个key上一次访问的时间,和怎么去记录每一个key的访问频率
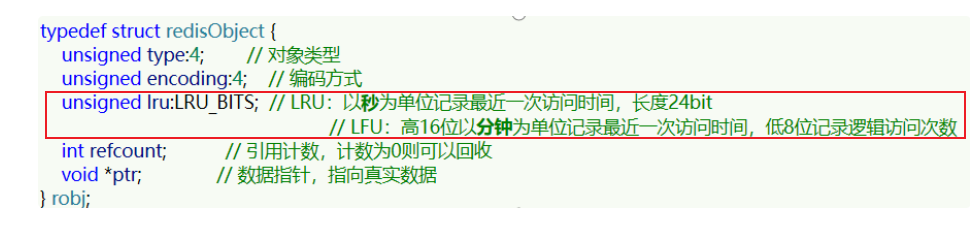
通过上面lru关键字可看出来,使用LFU是高16位是以分钟位单位记录最近一次访问时间,低8位记录逻辑访问次数
这样设计的原因是,如果全部是用来作为统计次数,那么假设这种场景,刚开始时某一个key访问次数很高,然后之后的时间都不会进行访问,那么就会造成这种现象,该Key的统计次数很高,不会作为淘汰对象,这样就使得该使用不到的key一直放在内存中,所以这里采用了时间+统计次数的方式来计算
时间是用来使统计次数衰减的,后8位是用来进行逻辑计数的,因为8位最多范围为(0~255)很显然不够,所以设置了一下算法:
LFU的访问次数之所以叫做逻辑访问次数,是因为并不是每次key被访问都计数,而是通过概率计算算出来的逻辑访问次数,算法如下:
- 生成0~1之间的随机数R
- 计算P=1/ (旧次数 * lfu_log_factor + 1),记录为P,lfu_log_factor默认为10
- 如果 R < P ,则计数器 + 1,且最大不超过255
- 访问次数会随时间衰减,距离上一次访问时间每隔 lfu_decay_time 分钟,计数器 -1
其中衰减周期lfu_decay_time和计算因子lfu_log_factor都是可以通过配置文件设置的
通过该算法可以看到刚开始时就次数较小那么P=1/ (旧次数 * lfu_log_factor + 1)时p就较大,那么R < P 的概率就较大,此时计数器+1操作概率就较大
淘汰策略整体流程
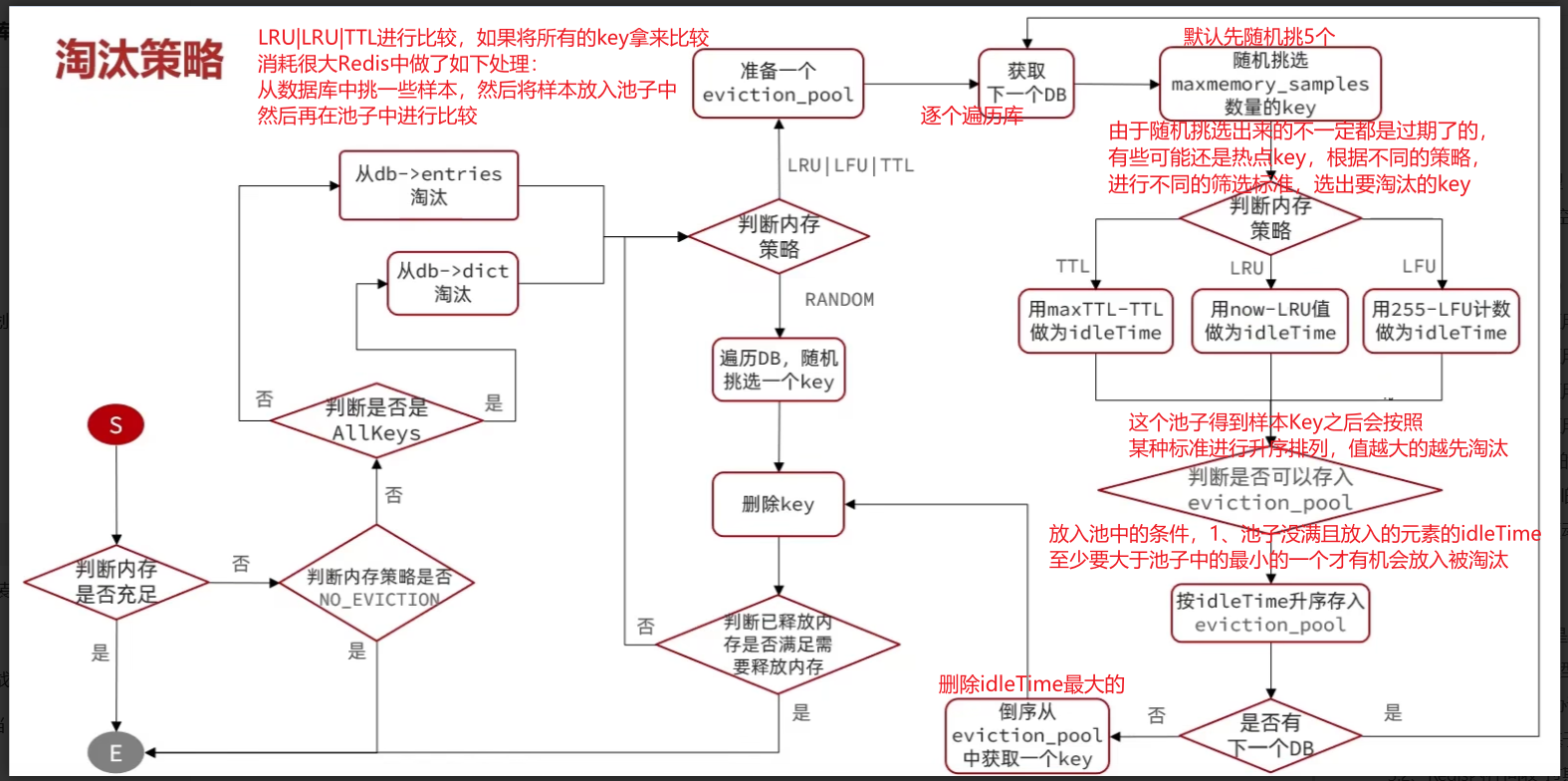
注意:一开始随机挑选的5隔样本点,不管的的dileTime是否足够的(越大就说明越应该被淘汰),因为后面再次遍历,然后重复操作选取样本点的时候,进行内存判断策略后得到的dileTilme,放入池子中的条件为,池子未满,且池中最小的dileTime小于你要添加到池中的diletime这样替换下来,那么池子中总会保持diletime很大,即应该被淘汰。
总结:
Redis是可以设置内存上线的,Redis中为了防止内存达到上限有两种不同策略
- 内存过期:内存过期后有两种删除策略,但是内存过期删除机制,只能删除过期了的数据,如果key都没过期且Redis中内存到达了上限,那么就交给内存淘汰机制来解决
-
- 惰性删除:即当你访问时先检查一下有没有过期,过期了就删除
- 周期删除:定期的任务,每隔一段时间就去删除一些过期的key
- 内存淘汰
-
- 有8中内存淘汰机制
- 一个是no..:即只要内存不足就直接报错,默认
- 两个随机的
- 两个LFU
- 连个LRU
- 一个TTL
整体总结:
Redis中通过过期策略+内存淘汰策略来进行Redis的内存回收策略
其实可以理解为通过过期策略来主动清理内存,通过内存淘汰策略来进行兜底措施,即当通过策略清理后内存还是不够,那么就使用淘汰策略来进行强制性的操作
至于为什么过期策略是使用惰性删除+周期性删除来进行而不是直接key过期了就直接删除,我的理解就是是为了平衡cpu的使用,采用惰性删除+周期性这总,key过期了,我们不着急去删除,因为直接删除会使得CPU在删除上消耗过大,会影响此时redis的访问性能,而采用后面这种方式,相当于是将找一个合适的时机进行内存的清理,并且,清理的频率这些还是可以自己配置的,同时在redis4.0后还支持一步删除所以采用惰性删除+周期性删除来完成