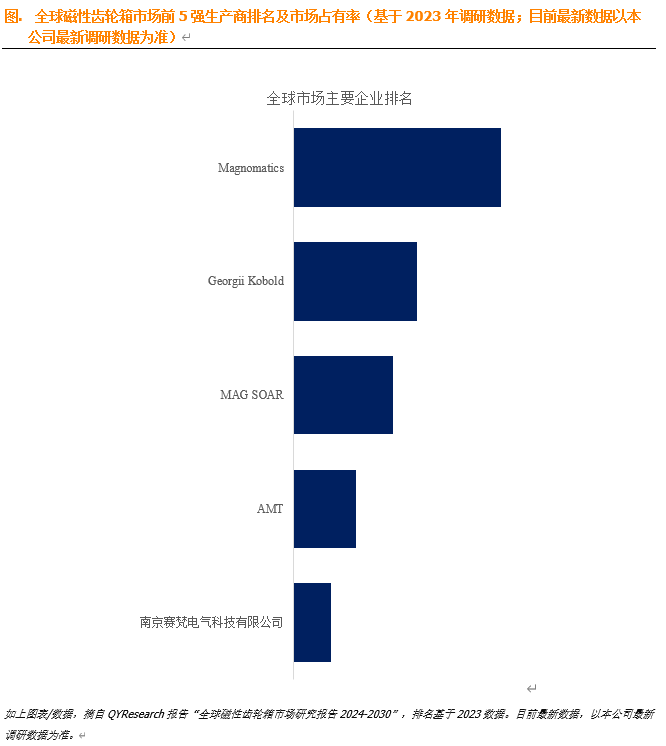
机器学习中的增量学习(Incremental Learning,IL)策略是什么?
在当今快速发展的数据驱动世界中,传统的静态机器学习模型逐渐显露出局限性。随着数据量的增长和分布的变化,模型需要不断更新,以保持其预测能力和适应性。然而,频繁的重新训练不仅耗费大量资源,还会导致模型丧失对旧数据的记忆,这被称为“灾难性遗忘”(Catastrophic Forgetting)现象。为解决这一问题,增量学习(Incremental Learning, IL)策略应运而生。本文将全面探讨增量学习的概念、核心策略、典型应用场景、挑战以及未来的发展方向。
什么是增量学习?
增量学习(Incremental Learning, IL)是一种使机器学习模型能够在持续获取新数据的同时,保留已学知识的策略。它不仅有助于模型在动态环境中保持性能稳定,还能显著减少重新训练所需的时间和计算资源。这种方法特别适合那些需要长期维护和更新的系统,如在线服务、自动驾驶系统和个性化推荐系统。
增量学习的核心策略
-
基于正则化的方法:
在学习新任务时,通过正则化项限制模型对新数据的适应性,保护已学知识。弹性权重巩固(Elastic Weight Consolidation, EWC)就是典型的正则化方法,通过如下公式将模型参数与先前任务相关联,降低重要参数的变化幅度:
L = L new + ∑ i λ 2 F i ( θ i − θ i ∗ ) 2 \mathcal{L} = \mathcal{L}_{\text{new}} + \sum_i \frac{\lambda}{2} F_i (\theta_i - \theta_i^{*})^2 L=Lnew+i∑2λFi(θi−θi∗)2
其中, L new \mathcal{L}_{\text{new}} Lnew 是新任务的损失函数, θ i \theta_i θi 是模型参数, θ i ∗ \theta_i^{*} θi∗ 是旧任务的最优参数, F i F_i Fi 是费舍尔信息矩阵, λ \lambda λ 是正则化强度。其他类似的正则化技术如Synaptic Intelligence (SI) 和 Memory Aware Synapses (MAS) 也各有其独特的参数评估和保护机制。 -
基于回放的方法:
通过将部分旧数据样本保存在记忆库中,定期与新数据一起回放训练。回放的策略多种多样,如贪婪回放、选择性回放等。选择性回放可以通过对旧数据的代表性样本进行选择来减少存储需求,或者通过生成模型(如GANs)合成回放数据。尽管回放策略有效,但其存储需求和样本选择策略仍是一个挑战。 -
基于知识蒸馏的方法:
通过利用旧模型的输出作为新模型的软标签,使新模型的预测尽量接近旧模型的输出,减少遗忘发生。知识蒸馏的核心在于如下公式,其中 $ \text{KL} $ 是KL散度, p old ( x ) p_{\text{old}}(x) pold(x) 和 p new ( x ) p_{\text{new}}(x) pnew(x) 分别为旧模型和新模型的输出分布, α \alpha α 为平衡系数:
L = α ⋅ KL ( p old ( x ) ∥ p new ( x ) ) + ( 1 − α ) ⋅ L new \mathcal{L} = \alpha \cdot \text{KL}(p_{\text{old}}(x) \parallel p_{\text{new}}(x)) + (1-\alpha) \cdot \mathcal{L}_{\text{new}} L=α⋅KL(pold(x)∥pnew(x))+(1−α)⋅Lnew
通过温度调节(temperature scaling),可以控制软标签的平滑度,影响新模型的学习效果。 -
基于结构扩展的方法:
通过动态增加模型的神经元或网络层,以适应新的知识。此策略的优点在于能够扩展模型容量,适应更多任务和数据。然而,这也可能导致模型过于庞大,增加计算复杂性和推理时间。这种方法在迁移学习或多任务学习中有实际应用。 -
混合策略:
结合上述多种策略,以期在不同场景下达到更优的平衡。例如,在回放策略中加入正则化项,或者在知识蒸馏的基础上动态扩展模型结构。尽管设计更加复杂,但往往能够提供更好的性能和灵活性。
增量学习的应用场景
增量学习策略在多个领域展现了广泛的应用前景:
-
在线学习系统:如推荐系统和广告系统,需要根据用户行为的变化不断更新模型,以提供更个性化的服务。增量学习使这些系统在不频繁重新训练的情况下,保持对用户兴趣的敏感性和反应速度。
-
自动驾驶:自动驾驶车辆需要在不断变化的环境中运行,增量学习能够帮助模型在接受新数据时,保持对旧数据的认知,确保车辆在各种路况下都能做出正确判断。
-
个性化医疗:随着病人数据的不断累积,模型需要动态调整以提供个性化的治疗方案。增量学习能够使医疗系统在保留旧患者知识的同时,快速学习新患者的特征,为个体提供精准治疗。
-
自然语言处理:语言模型需要不断更新以适应新词汇、新表达方式和新语境。增量学习使得这些模型能够在不失去原有语言理解能力的情况下,逐步扩展其词汇量和表达方式。
举个栗子:在线推荐系统中的增量学习
假设你是一个在线音乐推荐系统的用户。每天都有成千上万的新歌曲上传,用户的偏好也在不断变化。如果系统仅基于你之前的偏好来推荐音乐,它可能无法及时推荐你感兴趣的新歌曲。为了保持推荐的准确性,系统会使用增量学习来逐步更新模型,使其能够在不忘记你之前喜好的同时,学习到你新近的偏好。例如,你最近开始喜欢某种新风格的音乐,系统通过增量学习不断更新推荐模型,既不丢失你之前喜欢的歌曲风格,又能及时为你推荐最新的歌曲。
增量学习面临的挑战与解决方案
挑战
- 灾难性遗忘:新数据的引入可能导致模型丧失对旧数据的记忆,从而导致性能下降。解决这一问题是增量学习中的核心挑战之一。
- 存储与计算:某些策略(如回放策略)可能需要大量的存储空间或计算资源,特别是当数据量庞大时。
- 模型扩展:基于结构扩展的策略可能导致模型变得过于庞大,影响其实际应用。
解决方案
- 混合策略:结合正则化、回放、知识蒸馏等策略,可以有效缓解灾难性遗忘问题,减少存储和计算需求。
- 记忆库管理:通过选择性回放或生成模型合成数据,可以在减少存储需求的同时保持模型性能。
- 动态资源分配:在结构扩展中,合理分配计算资源和模型容量,确保模型能够在维持性能的同时,控制其复杂性。
未来的发展方向
随着增量学习在各种实际应用中的普及,未来的发展可能包括:
-
无监督增量学习:探索如何在无标签数据的情况下进行有效的增量学习,使其在更多应用场景中具有实际意义。
-
与元学习结合:结合元学习快速适应新任务的能力,设计增量学习策略,提高模型在面对任务和数据变化时的适应性和稳健性。
-
跨领域增量学习:研究如何在不同领域间共享和增量学习知识,推动迁移学习的发展。
-
高效计算增量学习:在计算资源有限的设备上,如边缘设备或移动设备上,研究如何高效地进行增量学习,确保其在实际应用中的可行性。
-
增量学习框架与工具:随着增量学习的复杂性增加,开发出更加健全的增量学习框架和工具,以简化其实现和应用,成为了未来的研究方向之一。
结论
增量学习为应对数据和任务不断变化的挑战提供了一种强大的方法。通过结合正则化、回放、知识蒸馏等多种策略,增量学习能够在保持模型性能的同时,减少重新训练的成本和资源消耗。尽管增量学习面临着存储需求、计算复杂性以及灾难性遗忘等挑战,但其广泛的应用前景和不断发展的技术手段,预示着它在未来会成为机器学习领域中的重要研究方向。