🎁👉点击进入文心快码 Baidu Comate 官网,体验智能编码之旅,还有超多福利!🎁
【大厂面试真题】系列,带你攻克大厂面试真题,秒变offer收割机!
❓今日问题:在8g内存的机器,能否启动一个7G堆大小的java进程?
❤️一起看看文心快码Baidu Comate给出的答案吧!如果这个问题你也会,也可以在评论区写出你的答案哦~
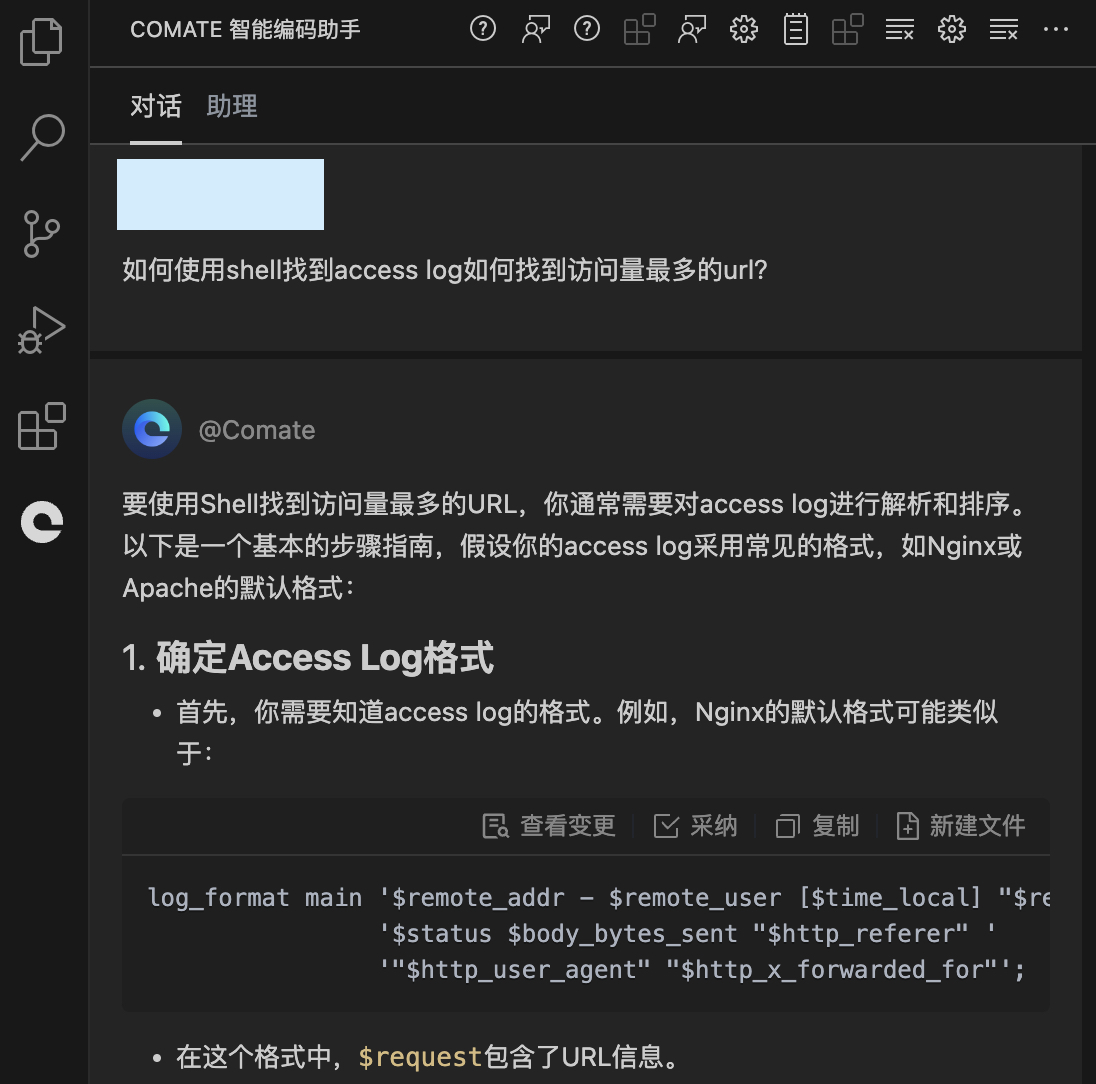
@Comate
要使用Shell找到访问量最多的URL,你通常需要对access log进行解析和排序。以下是一个基本的步骤指南,假设你的access log采用常见的格式,如Nginx或Apache的默认格式:
1.确定Access Log格式
-
首先,你需要知道access log的格式。例如,Nginx的默认格式可能类似于:
log_format main '$remote_addr - $remote_user [$time_local]
"$re '$status $body_bytes_sent "$http_referer" '
""$http_user_agent" "$http_x_forwarded_for"";-
在这个格式中,$request包含了URL信息。
2.使用Shell命令解析和排序
-
你可以使用awk,sort,和uniq等命令来解析和排序日志。
示例:
假设你的access log文件名为access.log,并且URL是日志行的第7个字段(根据$request的位置和日志格式可能有所不同),你可以使用以下命令:
awk '{print $7}' access.log | sort | uniq -c | sort -nr | headawk '{print $7}' access.log:提取日志中每行的第7个字段(通常是URL)。
sort:对提取出的URL进行排序。
uniq-c:统计每个URL出现的次数。
sort-nr:根据出现次数进行数字逆序排序。
head-n10:显示出现次数最多的前10个URL。
3.分析结果
执行上述命令后,你将看到一个按访问量排序的URL列表。列表的每一行都显示了URL和对应的访问次数。
注意事项:
-
确保根据你的实际日志格式调整字段选择器(在awk命令中的$7)。
-
如果日志文件非常大,这些命令可能需要一些时间来执行。你可以考虑使用
-
更高效的日志分析工具,如awk的更复杂脚本、sed、perl或专门的日志分析软件。
-
如果你的服务器是多核的,并且处理非常大的日志文件,你可以在sort命令中使用-p参数来利用多个处理器核心进行并行处理。但请注意,这可能会增加内存使用。
🎁👉点击进入文心快码 Baidu Comate 官网,体验智能编码之旅,还有超多福利!🎁