本文根据“一文看懂Mamba,Transformer最强竞争者”(机器之心 编辑:Panda)一文修改,并补充了一些新的观点。
在深度学习领域的广阔天地中,随着技术的不断进步,对更高效、更强大模型架构的探索从未停歇。Transformer模型作为近年来的一颗璀璨明星,凭借其强大的序列建模能力,在机器翻译、文本生成、语音识别等前沿领域大放异彩,树立了新的性能标杆。这一成功背后,关键在于Transformer内置的注意力机制,它犹如一盏明灯,照亮了输入序列中的关键信息路径,使模型能够更深入地理解上下文环境,从而做出更为精准的预测和决策。
然而,正如每枚硬币都有其两面,Transformer的注意力机制在赋予其卓越性能的同时,也带来了计算复杂度的显著上升,特别是当面对超长文本序列时,这种二次增长的计算需求成为了制约其应用的一大瓶颈。为了解决这一问题,研究者们不断探索新的路径,以期在保持高效建模能力的同时,降低计算成本。
正是在这样的背景下,结构化状态空间序列模型(SSM)应运而生,它以独特的视角和创新的架构,为深度学习领域带来了新的希望。SSM不仅继承了传统状态空间模型在序列处理方面的优势,还巧妙地融合了RNN的序列记忆和CNN的空间特征提取能力,形成了一种既能捕捉长期依赖又能高效处理局部信息的混合模型。通过优化循环或卷积操作,SSM实现了计算成本随序列长度的线性或近线性增长,有效缓解了Transformer在计算资源上的压力。
SSM家族中的Mamba模型更是其中的佼佼者,它不仅在建模能力上与Transformer不相上下,更在处理长序列数据时展现出了卓越的线性可扩展性。这一成就得益于Mamba引入的精炼选择机制,该机制能够智能地根据输入数据动态调整模型参数,剔除冗余信息,保留关键特征,从而在保证信息精度的同时提高了处理效率。此外,Mamba还充分利用了硬件加速技术,通过扫描操作替代传统卷积,在高性能GPU上实现了计算速度的大幅提升,进一步增强了其实用性和竞争力。
如图1所示,Mamba模型在处理复杂长序列数据时的卓越表现,以及其在计算成本上的显著优势,正逐步奠定其作为未来基础模型的重要地位。随着计算机视觉、自然语言处理、医疗健康等领域对高效、精准模型需求的日益增长,Mamba有望引领一场深刻的变革,推动这些领域的技术进步和应用拓展。
因此,研究和应用 Mamba 的文献迅速增长,让人目不暇接,一篇全面的综述报告必定大有裨益。近日,香港理工大学的一个研究团队在 arXiv 上发布了他们的贡献。

-
论文标题:A Survey of Mamba
-
论文地址:https://arxiv.org/pdf/2408.01129
这份综述报告从多个角度对 Mamba 进行了总结,既能帮助初学者学习 Mamba 的基础工作机制,也能助力经验丰富的实践者了解最新进展。
Mamba 是一个热门研究方向,也因此有多个团队都在尝试编写综述报告,除了本文介绍的这一篇,还有另一些关注状态空间模型或视觉 Mamba 的综述,详情请参阅相应论文:
-
Mamba-360: Survey of state space models as transformer alternative for long sequence modelling: Methods, applications, and challenges. arXiv:2404.16112
-
State space model for new-generation network alternative to transformers: A survey. arXiv:2404.09516
-
Vision Mamba: A Comprehensive Survey and Taxonomy. arXiv:2405.04404
-
A survey on vision mamba: Models, applications and challenges. arXiv:2404.18861
-
A survey on visual mamba. arXiv:2404.15956
预备知识
循环神经网络(RNN)
循环神经网络(Recurrent Neural Network, RNN)作为一类特殊的神经网络架构,其核心在于其内置的循环结构,该结构赋予了RNN处理序列数据(如时间序列、文本数据等)并保留内部记忆的能力。具体而言,RNN在处理序列中的每一个元素时,都会将其与前一时刻的隐藏状态相结合,这一过程通过内部的循环连接实现。隐藏状态作为RNN的记忆单元,不仅包含了当前输入的信息,还融合了历史输入的影响,使得RNN能够捕获序列中的时序依赖关系。
在标准的RNN框架中,每个时间步骤k的处理过程可以分解为以下几个关键步骤:首先,将当前时间步骤的输入向量xk与前一时间步骤的隐藏状态hk−1作为联合输入,送入一个激活函数(如Sigmoid或Tanh)中进行处理;随后,生成当前时间步骤的输出向量yk和更新后的隐藏状态hk。隐藏状态hk不仅作为当前时间步骤的输出的一部分,还会被传递到下一个时间步骤,作为处理下一个输入向量的基础。这种机制确保了RNN能够处理任意长度的序列,并随着序列的推进逐步积累信息。
Transformer
Transformer模型通过引入自注意力机制(Self-Attention Mechanism),在捕获输入序列中的全局依赖关系方面取得了显著进展。与RNN相比,Transformer摒弃了循环结构,转而采用一种基于注意力机制的全新架构,实现了对序列数据的并行处理,大大提高了计算效率。
在Transformer中,自注意力机制的实现依赖于三个关键向量:查询(Query, Q)、键(Key, K)和值(Value, V)。这些向量是通过将原始输入向量序列x进行线性变换得到的。具体而言,输入序列中的每个元素都会通过三个不同的线性变换矩阵,分别生成对应的Q、K、V向量。
接下来,Transformer计算每个位置相对于其他所有位置的注意力分数,这些分数反映了不同位置之间的关联程度。这一计算过程是通过点积(或缩放点积)操作实现的,即将每个位置的查询向量与所有位置的键向量进行点积运算,并通过softmax函数进行归一化,得到注意力权重。这些权重随后被用于对值向量进行加权求和,生成每个位置的上下文表示。
为了进一步提升模型的表达能力和灵活性,Transformer还引入了多头注意力(Multi-Head Attention)机制。多头注意力通过将输入序列并行地送入多个自注意力模块(每个模块称为一个“头”),并独立执行上述自注意力计算过程,最后再将各个头的输出进行拼接和线性变换,从而得到最终的输出。这种方式允许模型从多个角度捕捉输入序列中的不同类型关系和模式,增强了模型的理解能力和泛化能力。
状态空间模型(SSM)
状态方程与观察方程:
SSM的核心在于其状态方程和观察方程。状态方程描述了隐藏状态h(t)如何随时间t变化,通常形式为h(t+1)=A⋅h(t)+B⋅u(t)+ϵ_h,其中A和B是系统矩阵,u(t)是控制输入,ϵ_h是过程噪声。观察方程则连接了隐藏状态与可观测输出y(t),形式为y(t)=C⋅h(t)+D⋅u(t)+ϵ_y,其中C和D是观测矩阵,ϵ_y是观测噪声。
线性与关联属性:
虽然SSM本质上是线性的,但其通过状态变量之间的相互作用和动态变化,能够表达复杂的非线性行为(在扩展卡尔曼滤波等方法中通过非线性函数近似)。SSM的关联属性意味着它能够有效地捕捉序列数据中的长期依赖关系,这对于理解和预测动态系统至关重要。
Zero-Order Hold(ZOH):
在将SSM应用于机器学习时,离散化是一个关键步骤。ZOH方法通过假设在每个时间间隔内状态保持不变,简化了连续时间系统的处理。这一简化不仅降低了计算的复杂性,还使得SSM能够更直接地与离散时间模型(如RNN)进行比较和结合。在Mamba模型中,这种离散化策略可能有助于减少计算负担,同时保持对序列数据的有效建模能力。
线性系统的结合属性:
SSM作为线性系统,其状态转移和观测过程都可以通过矩阵运算来描述,这使得SSM能够自然地与卷积操作相结合。在离散SSM中,状态转移矩阵可以被视为一种特殊的卷积核,它在时间维度上滑动,对隐藏状态进行更新。
Mamba模型中的卷积优化:
Mamba模型通过引入硬件感知优化技术,采用扫描操作替代了传统的卷积操作来进行循环计算。这种优化策略利用了现代GPU的并行计算能力,通过减少不必要的数据移动和重复计算,显著提高了模型的推理速度。在A100 GPU上,这种优化使得Mamba模型的计算速度相比传统方法有了三倍以上的提升。
RNN、Transformer 和 SSM 之间的关系
图 2 展示了 RNN、Transformer 和 SSM 的计算算法。
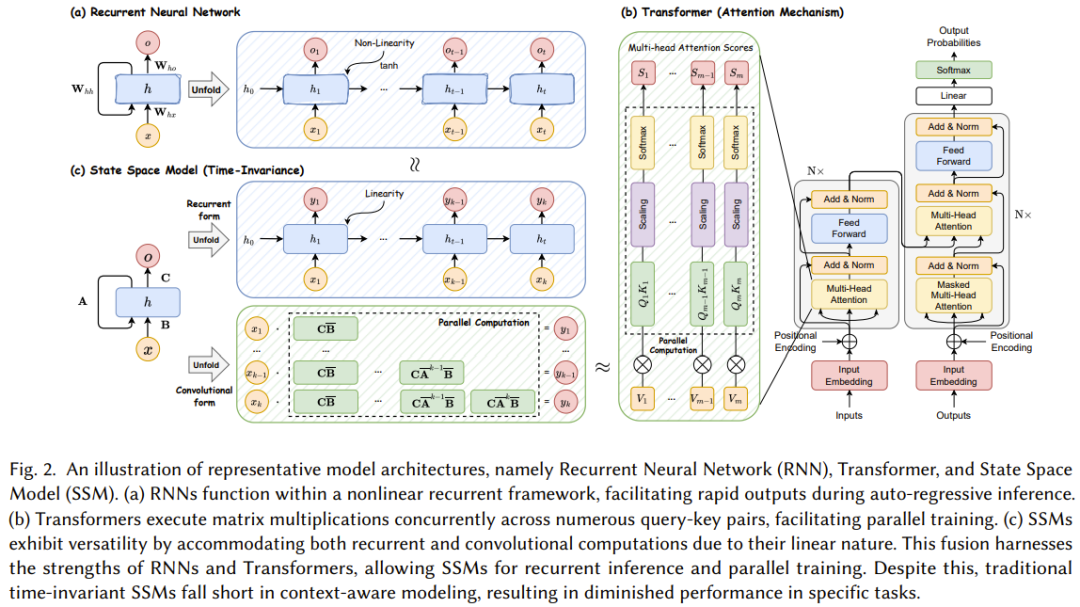
在探讨RNN(循环神经网络)、Transformer和SSM(状态空间模型)之间的关系时,可以从它们的计算特性、并行处理能力、以及在不同任务上的表现等多个维度来进行分析。
RNN与Transformer的关系
计算特性与并行性:
-
RNN:RNN的核心在于其内部的循环连接,使得每个时间步的输出不仅依赖于当前的输入,还依赖于之前的隐藏状态。这种非线性循环框架使得RNN在处理序列数据时非常有效,特别是在需要保留历史信息以进行后续预测或生成时。然而,这种逐步计算的特性也限制了RNN的并行处理能力,因为每个时间步的计算都依赖于前一个时间步的输出。因此,在训练大规模RNN模型时,计算效率往往较低。
-
Transformer:相比之下,Transformer通过自注意力机制(Self-Attention Mechanism)实现了对序列数据的并行处理。Transformer中的每个位置都可以同时与其他位置进行交互,无需像RNN那样顺序处理。这种并行性极大地提高了模型的训练速度,并使得Transformer在处理长序列时更加高效。然而,在自回归推理(如文本生成)时,Transformer需要逐步生成输出,这可能导致推理过程相对耗时。
性能与应用:
- RNN和Transformer在性能上各有优劣,适用于不同的应用场景。RNN由于其天然的序列处理能力,在需要保留长期依赖关系的任务(如语言模型、时间序列预测)中表现出色。而Transformer则凭借其强大的并行计算能力和全局依赖捕捉能力,在机器翻译、文本摘要等任务中取得了显著成果。
SSM与RNN、Transformer的关系
灵活性与计算特性:
- SSM:SSM作为一种传统的数学框架,通过状态方程和观察方程来描述系统的动态行为。与RNN和Transformer相比,SSM具有更高的灵活性。其线性性质使得SSM既能支持循环计算(类似于RNN),也能支持卷积计算(通过适当的离散化)。这种灵活性使得SSM在不同任务中可以根据需要选择合适的计算方式,从而优化模型的性能和效率。
并行训练与推理:
- SSM的线性性质还为其带来了并行训练的优势。尽管最常规的SSM是时不变的(即系统矩阵A、B、C和时间间隔Δ与输入x无关),但这一特性并不妨碍SSM通过合理的离散化和并行化策略来实现高效的训练。同时,由于SSM可以支持卷积计算,因此在某些情况下,SSM可以比RNN更高效地执行推理过程(尤其是在可以利用卷积计算的硬件上)。
上下文感知与限制:
- 然而,SSM的上下文感知能力相对有限。由于最常规的SSM不随输入变化而改变其系统矩阵,因此在处理需要高度上下文感知的任务(如选择性复制)时,SSM可能表现不佳。相比之下,RNN和Transformer通过其内部的非线性机制或注意力机制能够更好地捕捉和利用输入数据中的上下文信息。
综上所述,RNN、Transformer和SSM在计算特性、并行处理能力以及上下文感知能力等方面各有优劣,它们之间的关系可以看作是互补而非替代。在实际应用中,可以根据具体任务的需求和硬件条件来选择合适的模型或模型组合以获得最佳性能。
Mamba
为了解决上述传统 SSM 的缺点,实现上下文感知型建模,Albert Gu 和 Tri Dao 提出了可用作通用序列基础模型主干网络的 Mamba。之后,又进一步提出了 Mamba-2,其中的结构化空间状态对偶(SSD/Structured Space-State Duality)构建了一个将结构化 SSM 与多种形式的注意力连接起来的稳健的理论框架,可将原本为 Transformer 开发的算法和系统优化技术迁移用于 SSM。
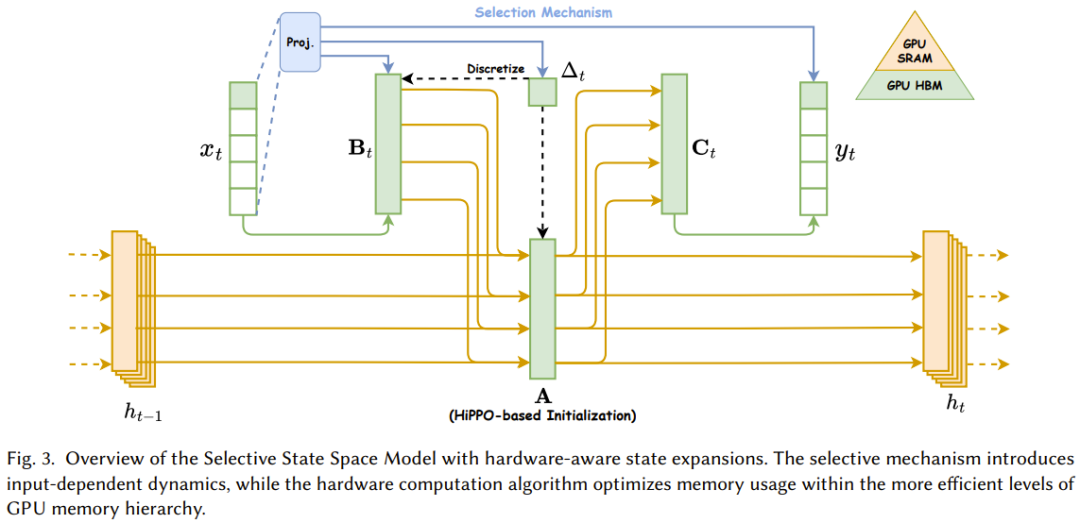
Mamba-1 使用硬件感知型算法的选择式状态空间模型
Mamba-1 基于结构化状态空间模型引入了三大创新技术,即基于高阶多项式投影算子(HiPPO)的内存初始化、选择机制和硬件感知型计算。如图 3 所示。这些技术的目标是提升 SSM 的长程线性时间序列建模能力。
1. 基于高阶多项式投影算子(HiPPO)的内存初始化
技术细节:
- HiPPO 投影算子:HiPPO 是一种用于时间序列建模的投影算子,它特别适用于捕捉长期依赖关系。在 Mamba-1 中,HiPPO 被用作状态空间模型的初始状态或记忆初始化方法。HiPPO 投影算子通常定义为一种多项式函数,该函数能够优先保留时间序列中的低频(长期)成分,同时抑制高频(短期)噪声。
- 实现方式:在 Mamba-1 的实现中,HiPPO 投影算子被应用于输入时间序列,生成一个初始的隐藏状态矩阵。这个初始状态矩阵被设计为能够捕获输入序列中的长期趋势和周期性模式,从而为后续的状态更新提供一个良好的起点。
2. 选择机制
技术细节:
- 内容感知表征:选择机制允许 Mamba-1 的状态空间模型根据输入内容动态地调整其内部状态。这通过引入一种基于内容的门控机制来实现,该机制能够决定哪些输入信息应该被保留在隐藏状态中,哪些应该被忽略。
- 实现方式:通常,这种选择机制可以通过一个额外的神经网络层(如门控循环单元或注意力机制)来实现。该层接收输入序列和当前隐藏状态作为输入,并输出一个权重向量,用于调整隐藏状态的更新。这样,模型就能够根据输入内容的不同,灵活地调整其内部状态,从而生成更加准确和有意义的输出。
3. 硬件感知型计算
技术细节:
- Parallel Associative Scan(并行关联扫描):这是一种高效的并行算法,用于计算状态空间模型中的累积和或累积乘积等操作。在 Mamba-1 中,该算法被用于加速状态更新过程中的某些计算步骤,如计算隐藏状态的累积效应。
- Memory Recomputation(内存重新计算):这是一种内存优化技术,用于减少训练过程中的内存占用。在反向传播过程中,该技术允许模型在计算梯度时重新计算某些中间结果,而不是将它们全部存储在内存中。这可以显著减少内存使用量,特别是在处理大规模数据集时。
Mamba-2:状态空间对偶
1. 结构化状态空间对偶(SSD)
技术细节:
- 半可分离矩阵变换:SSD 框架将 Transformer 的注意力机制和 SSM 的线性时不变系统视为半可分离的矩阵变换。这种视角使得两种模型在理论上可以相互转换和融合。
- 等价性证明:Albert Gu 和 Tri Dao 证明了选择式 SSM 可以被看作是一种使用半可分离掩码矩阵实现的结构化线性注意力机制。这一发现为将 Transformer 的优化技术应用于 SSM 提供了理论基础。
2. 块分解矩阵乘法算法
技术细节:
- 矩阵块分解:在 Mamba-2 中,状态空间模型被视为一个半可分离矩阵,并通过块分解矩阵乘法算法进行高效计算。该算法将矩阵分解为多个块,其中对角块表示块内计算(即每个时间步的独立计算),非对角块表示块间计算(即跨时间步的依赖关系)。
- 计算效率:通过这种分解方法,Mamba-2 能够并行处理多个块内计算,同时减少块间计算的复杂度。这使得 Mamba-2 在训练过程中能够充分利用现代硬件的并行计算能力,从而实现更快的训练速度。
3. 性能与效率
技术细节:
- 训练速度提升:实验结果表明,Mamba-2 的训练速度可以超过 Mamba-1 的并行关联扫描算法的 2-8 倍。这主要得益于 SSD 框架和块分解矩阵乘法算法的高效性。
- 性能媲美 Transformer:尽管 Mamba-2 采用了与 Transformer 不同的模型架构,但其性能却能够媲美甚至超过 Transformer。这证明了 SSD 框架的有效性以及将 Transformer 技术应用于 SSM 的潜力。
Mamba 块
下面来看看 Mamba-1 和 Mamba-2 的块设计。图 4 比较了这两种架构。
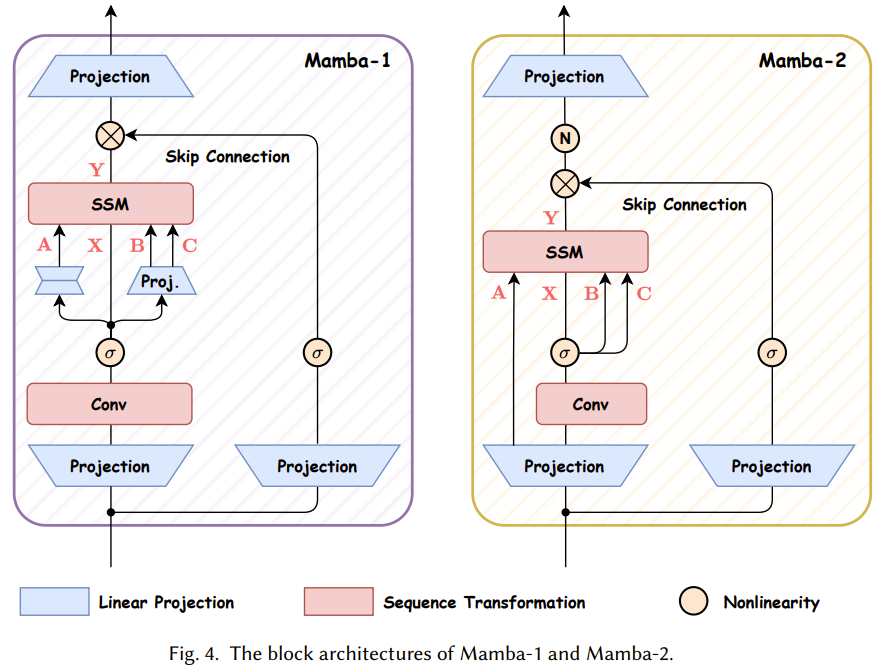
Mamba 模型正在发展进步
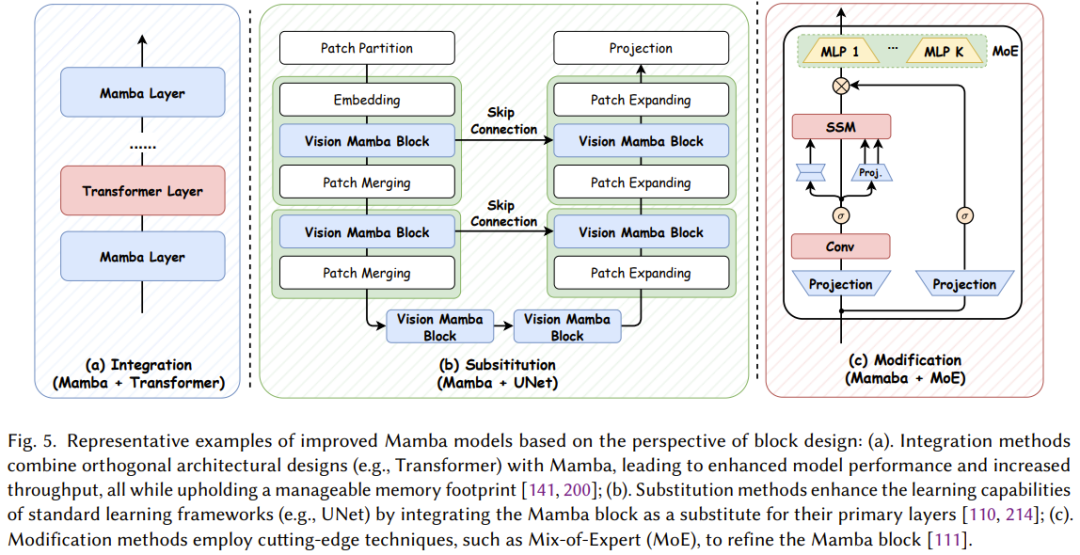
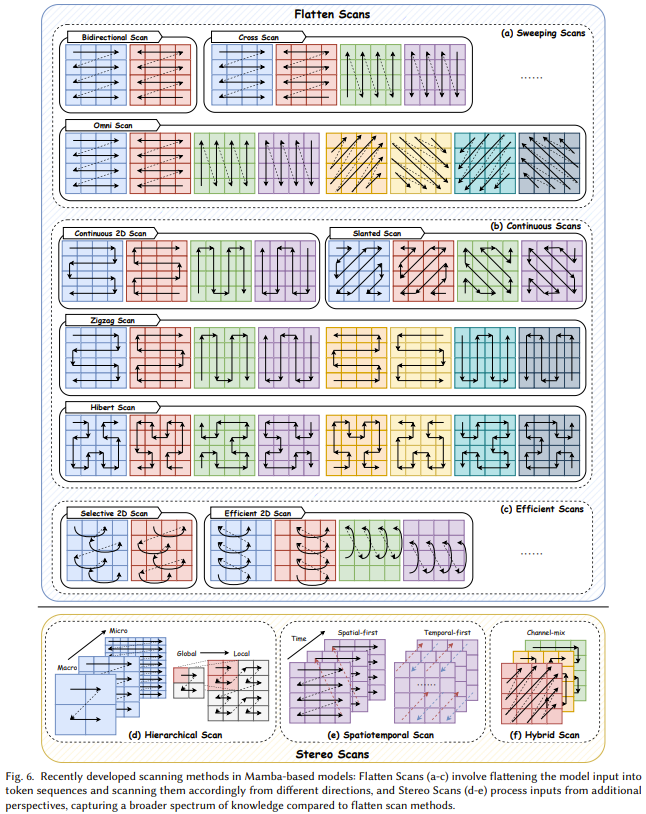
状态空间模型和 Mamba 近来发展迅猛,已经成为了一大极具潜力的基础模型骨干网络选择。尽管 Mamba 在自然语言处理任务上表现不俗,但也仍具有一些难题,比如记忆丢失、难以泛化到不同任务、在复杂模式方面的表现不及基于 Transformer 的语言模型。为了解决这些难题,研究社区为 Mamba 架构提出了诸多改进方案。现有的研究主要集中于修改块设计、扫描模式和记忆管理。表 1 分类总结了相关研究。
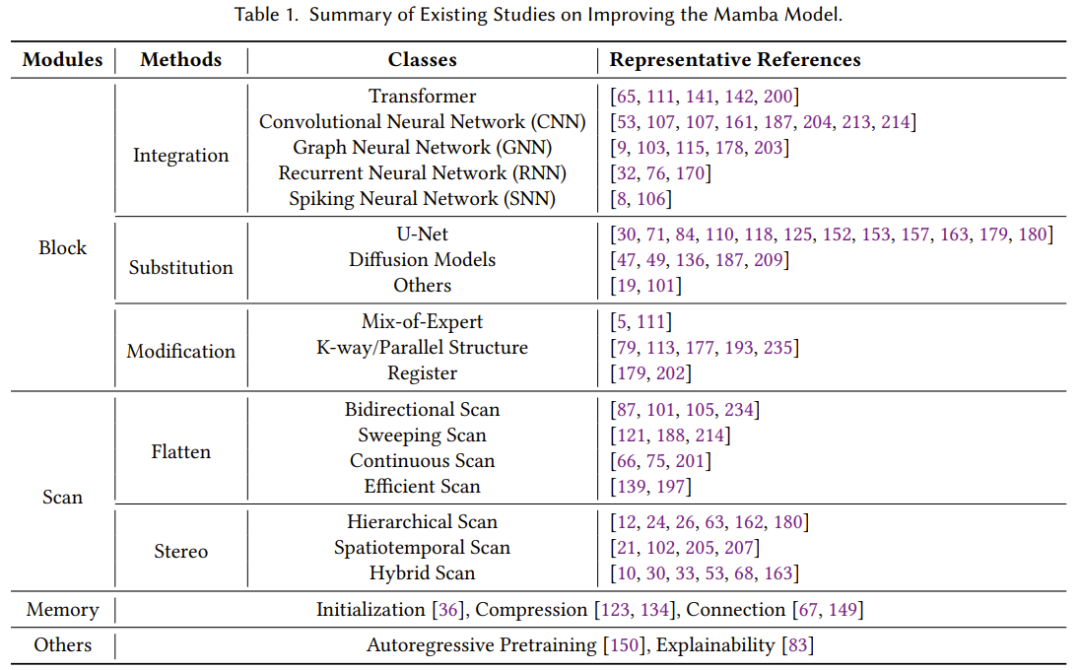
块设计、扫描模式和记忆管理的详细内容
一、块设计
在Mamba模型中,块设计是构建高效且强大序列建模能力的核心。根据《A Survey of Mamba》论文中的描述,块设计的研究主要集中在如何优化Mamba模块的结构和功能,以提升模型的性能。
基本块结构的优化:
线性投射与SSM参数:每个Mamba块通常包含对输入序列的线性投射,以及SSM的(A, B, C)参数矩阵。研究者们通过调整这些参数矩阵的初始化方式、维度或结构,来优化SSM的动态行为,进而提升模型的表达能力。
残差连接与归一化:为了缓解深层网络中的梯度消失或爆炸问题,研究者们常在Mamba块中引入残差连接和归一化层(如Layer Normalization)。这些技术有助于稳定训练过程,提高模型的收敛速度和性能。
复合块结构:
层次化堆叠:通过将多个Mamba块以层次化的方式堆叠起来,形成更深的网络结构,可以捕获更复杂的序列特征。同时,为了保持信息的流畅传递,研究者们会在堆叠过程中引入跳跃连接或门控机制。
多尺度建模:为了处理不同时间尺度的序列信息,研究者们设计了多尺度Mamba块。这些块能够同时捕获局部和全局的序列特征,从而提高模型对复杂序列数据的建模能力。
新颖块设计:
图神经网络(GNN)集成:为了处理具有图结构的数据(如社交网络、知识图谱等),研究者们尝试将GNN与Mamba结合,设计出能够同时处理序列和图结构数据的复合块。
注意力机制增强:为了提升模型对重要信息的关注度,研究者们在Mamba块中引入了注意力机制(如自注意力、多头注意力等)。这些机制能够动态地调整不同时间步或特征的重要性,从而提高模型的性能。
二、扫描模式
扫描模式是Mamba模型中用于处理序列数据的关键机制。它决定了SSM如何随时间更新其状态,并生成输出序列。根据论文中的描述,扫描模式的研究主要集中在如何提高计算效率、降低内存需求以及增强模型的泛化能力。
并行关联扫描:
核融合与重新计算:并行关联扫描利用SSM的线性性质,在硬件层级上设计核融合和重新计算策略,以减少计算冗余并提高计算效率。这种方法能够显著加速训练过程,并降低内存需求。
时变SSM:为了更灵活地处理序列数据中的动态变化,研究者们设计了时变SSM。这些SSM的参数随时间变化,能够更准确地捕获序列中的非平稳特性。
双向扫描:
为了克服单向扫描在捕获全局信息方面的局限性,研究者们提出了双向扫描模式。在这种模式下,模型会同时考虑序列的前后文信息,从而更全面地理解序列数据。双向扫描可以显著提高模型在处理复杂序列任务时的性能。
分组扫描:
为了进一步提高计算效率和并行度,研究者们提出了分组扫描方法。在这种方法中,输入序列被分成多个组,每个组使用独立的SSM进行建模。然后,在更高层次上对这些组的信息进行融合,以生成最终的输出序列。分组扫描有助于减少计算量并加速训练过程。
三、记忆管理
记忆管理是SSM中至关重要的一个方面,它决定了模型如何存储和利用历史信息。在Mamba模型中,记忆管理的研究主要集中在如何优化SSM的隐藏状态表示、防止记忆丢失以及实现无损或低损的记忆压缩。
记忆初始化:
基于HiPPO的方法被用于初始化SSM的隐藏状态。这些方法能够确保SSM在初始阶段就具有捕获长期依赖关系的能力。然而,研究者们仍在探索更高效的记忆初始化策略,以进一步提高模型的性能。
记忆传递与融合:
在多层Mamba模型中,如何在不同层之间有效地传递和融合隐藏信息是一个关键问题。研究者们通过设计跳跃连接、门控机制或注意力机制等方法,来确保信息的流畅传递和有效融合。
记忆压缩:
为了减少内存占用并提高计算效率,研究者们提出了多种记忆压缩方法。这些方法包括低秩近似、稀疏化、量化等。通过压缩隐藏状态的表示,可以在保持模型性能的同时降低计算成本和内存需求。
长期记忆保持:
为了防止在长期训练过程中记忆丢失,研究者们设计了多种机制来保持SSM的隐藏状态稳定。这些机制包括正则化项、梯度裁剪、学习率调整等。通过这些方法,可以确保模型在训练过程中能够持续捕获和利用历史信息。