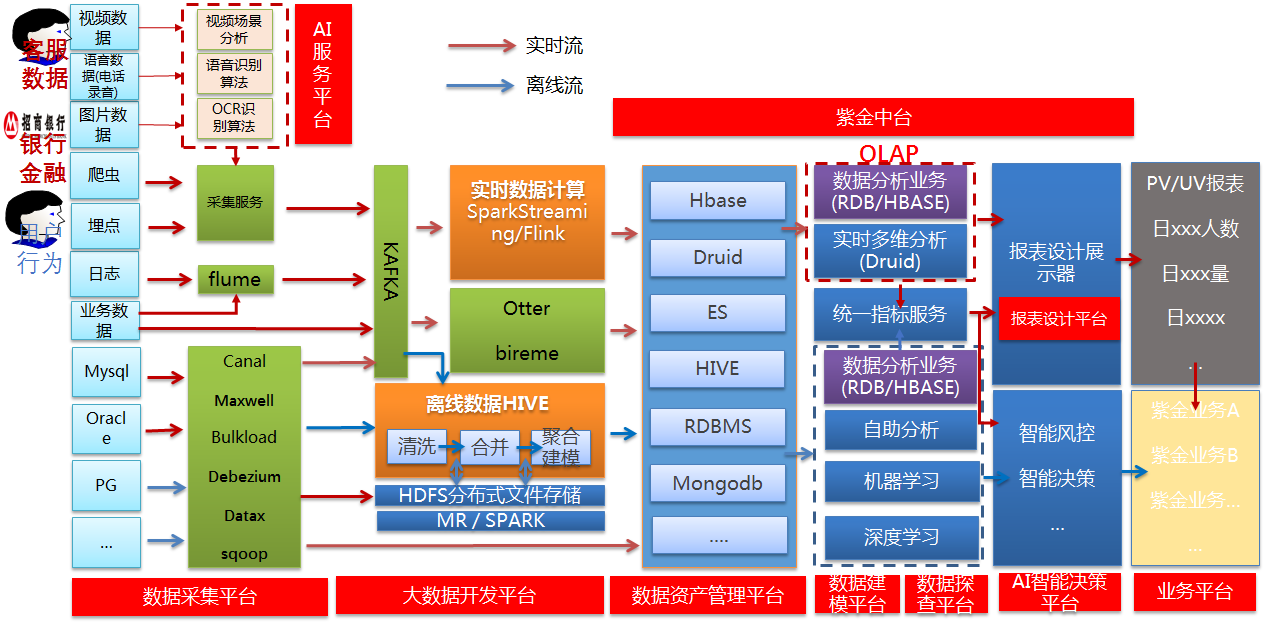
一、总体设计
初来公司时,公司还没有大数据,我是作为大数据架构师招入的,结合公司的线上和线下业务,制定了如下的大数据架构路线图。
二、大数据任务开发和调度平台架构设计
在设计完总体架构后,并且搭建完hadoop/yarn的大数据底层计算平台后, 按照总体架构设计思路, 首先需要构建的就是大数据开发平台。这也是一个非常核心的平台,也是最基础最重要的一个环节。
一开始设计的架构图如下所示。
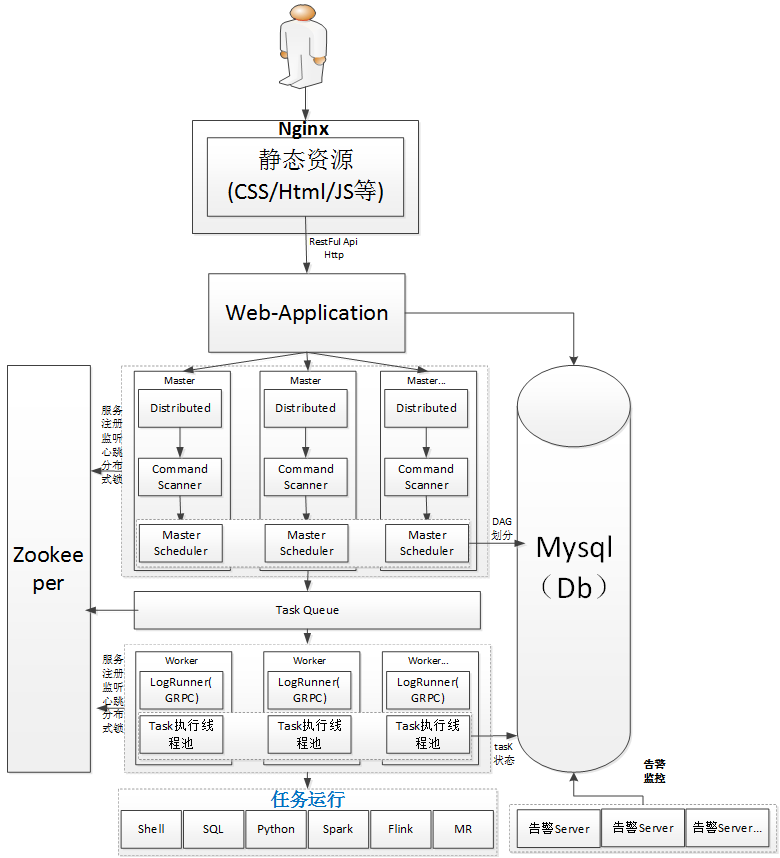
架构设计解释说明如下:
MasterServer:
MasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。 MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。
该服务内主要包含:
Distributed 分布式调度组件,主要负责定时任务的启停操作,当Distributed调起任务后,Master内部会有线程池具体负责处理任务的后续操作
MasterScheduler是一个扫描线程,定时扫描数据库中的 command 表,根据不同的命令类型进行不同的业务操作
MasterExecThread主要是负责DAG任务切分、任务提交监控、各种不同命令类型的逻辑处理
MasterTaskExecThread主要负责任务的持久化
WorkerServer:
WorkerServer同样也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。
该服务包含:
FetchTaskThread主要负责不断从Task Queue中领取任务,并根据不同任务类型调用TaskScheduleThread对应执行器。
LoggerServer是一个GRPC服务,提供日志分片查看、刷新和下载等功能
ZooKeeper:
ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错。另外系统还基于ZooKeeper进行事件监听和分布式锁。 也曾经想过基于Redis实现过队列,不过还是想依赖到的组件尽量地少,减少研发的学习成本,所以最后还是去掉了Redis实现。
Task Queue:
提供任务队列的操作,队列也是基于Zookeeper来实现。由于队列中存的信息较少,不必担心队列里数据过多的情况,对系统稳定性和性能没影响。
告警服务:
提供告警相关接口,接口主要包括告警两种类型的告警数据的存储、查询和通知功能。其中通知功能又有邮件通知和SNMP(暂未实现)两种。
API(web App 应用动态请求处理)
API接口层,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务。 接口包括工作流的创建、定义、查询、修改、发布、下线、手工启动、停止、暂停、恢复、从该节点开始执行等等。
UI(web app前端)
系统的前端页面,提供系统的各种可视化操作界面,详见系统使用手册部分。
web application采用前后端分离的方式, UI(web app前端) 中的静态资源采用nginx进行管理。
nginx.conf中的配置(前后端分离配置):
server {
listen 8888;# 监听端口
server_name bigdata-manager;
#charset koi8-r;
access_log /var/log/nginx/access.log main;
location / {
root /opt/app/dist; 静态资源文件的路径
index index.html index.html;
}
location /webPortal{
proxy_pass http://127.0.0.1:12345;# 动态请求处理,请求后端的API
}
}
DAG: 全称Directed Acyclic Graph,简称DAG。工作流中的Task任务以有向无环图的形式组装起来,从入度为零的节点进行拓扑遍历,直到无后继节点为止。
本文作者:张永清 转载请注明来源博客园:https://www.cnblogs.com/laoqing/p/12692566.html
三、架构设计思想
1、中心化还是去中心化设计的选择
中心化思想:中心化的设计理念比较简单,分布式集群中的节点按照角色分工,大体上分为两种角色:
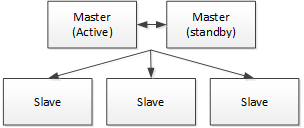
- Master的角色主要负责任务分发并监督Slave的健康状态,可以动态的将任务均衡到Slave上,以致Slave节点不至于“忙死”或”闲死”的状态。
- Worker的角色主要负责任务的执行工作并维护和Master的心跳,以便Master可以分配任务给Slave。
中心化思想设计存在的不足:
- 一旦Master出现了问题,则集群就会瘫痪,甚至整个集群就会崩溃。为了解决这个问题,大多数Master/Slave架构模式都采用了主备Master的设计方案,可以是热备或者冷备,也可以是自动切换或手动切换,而且越来越多的新系统都开始具备自动选举切换Master的能力,以提升系统的可用性。
- 另外一个问题是如果Scheduler在Master上,虽然可以支持一个DAG中不同的任务运行在不同的机器上,但是会产生Master的过负载。如果Scheduler在Slave上,则一个DAG中所有的任务都只能在某一台机器上进行作业提交,则并行任务比较多的时候,Slave的压力可能会比较大。
去中心化思想:
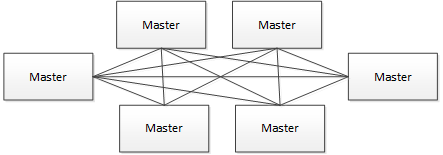
- 在去中心化设计里,通常没有Master/Slave的概念,所有的角色都是一样的,地位是平等的,任意节点设备down机,都只会影响很小范围的功能。
- 去中心化设计的核心设计在于整个分布式系统中不存在一个区别于其他节点的”管理者”,因此不存在单点故障问题。但由于不存在” 管理者”节点所以每个节点都需要跟其他节点通信才得到必须要的机器信息,而分布式系统通信的不可靠行,则大大增加了上述功能的实现难度。
- 真正去中心化的分布式系统并不多见。反而动态中心化分布式系统正在不断涌出。在这种架构下,集群中的管理者是被动态选择出来的,而不是预置的,并且集群在发生故障的时候,集群的节点会自发的举行"会议"来选举新的"管理者"去主持工作。最典型的案例就是ZooKeeper及Go语言实现的Etcd。
- 我们设计的去中心化是Master/Worker注册到Zookeeper中,实现Master集群和Worker集群无中心,并使用Zookeeper分布式锁来选举其中的一台Master或Worker为“管理者”来执行任务。
2、分布式锁的设计
使用ZooKeeper实现分布式锁来实现同一时刻集群中只有一台Master执行Scheduler,或者只有一台Worker执行任务的提交处理。
获取分布式锁的核心流程算法如下:
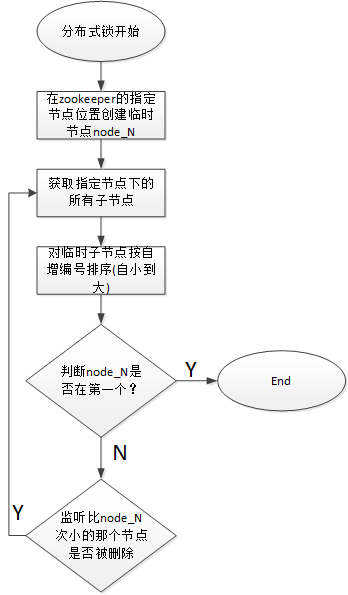
本文作者:张永清 转载请注明来源博客园:https://www.cnblogs.com/laoqing/p/12692566.html
分布式锁的代码实现:
一般不建议自己去实现,逻辑比较复杂,可以直接使用org.apache.curator 框架,引入如下依赖
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>${curator.version}</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>${curator.version}</version>
</dependency>
参考代码如下:
public class AbstractZKClient
{
private CuratorFramework zkClient = null;
public AbstractZKClient(String zookeeperConnectionString, Integer zookeeperRetrySleep, Integer zookeeperRetryMaxtime, Integer zookeeperSessionTimeout, Integer zookeeperConnectionTimeout) {
RetryPolicy retryPolicy = new ExponentialBackoffRetry(zookeeperRetrySleep, zookeeperRetryMaxtime);
zkClient = CuratorFrameworkFactory.builder()
.connectString(zookeeperConnectionString)
.retryPolicy(retryPolicy)
.sessionTimeoutMs(1000 * zookeeperSessionTimeout)
.connectionTimeoutMs(1000 * zookeeperConnectionTimeout)
.build();
zkClient.start();
initStateLister();
}
private void initStateLister() {
if (zkClient == null) {
return;
}
ConnectionStateListener csLister = (client, newState) -> {
log.info("state changed , current state : " + newState.name());
/**
* probably session expired
*/
if (newState == ConnectionState.LOST) {
// if lost , then exit
log.info("current zookeepr connection state : connection lost ");
}
};
zkClient.getConnectionStateListenable().addListener(csLister);
}
public void start() {
if (null != zkClient) {
if(!zkClient.isStarted()){
zkClient.start();
}
log.info("zookeeper start ...");
} else {
log.info("zkClient need to init,please check...");
}
}
public <T, R> R distributedLockExec(String lockPath, Long time, TimeUnit unit) {
InterProcessMutex lock = null;
try {
lock = new InterProcessMutex(zkClient, lockPath);
if (null == time && null == unit) {
lock.acquire();
//执行的处理
return exec.exec(parameters);
} else if (null != time && null != unit) {
if (lock.acquire(time, unit)) {
//执行的处理
return exec.exec(parameters);
} else {
log.info("zk distributedLockExec timeout...");
}
} else {
log.error("zk distributedLockExec time or unit is null");
}
} catch (Exception e) {
log.error("zk distributed lock exec failed", e);
} finally {
try {
if (null != lock) {
lock.release();
}
} catch (Exception e) {
log.error("zk distributed lock relase failed", e);
}
}
return null;
}
}
线程分布式锁实现流程图:
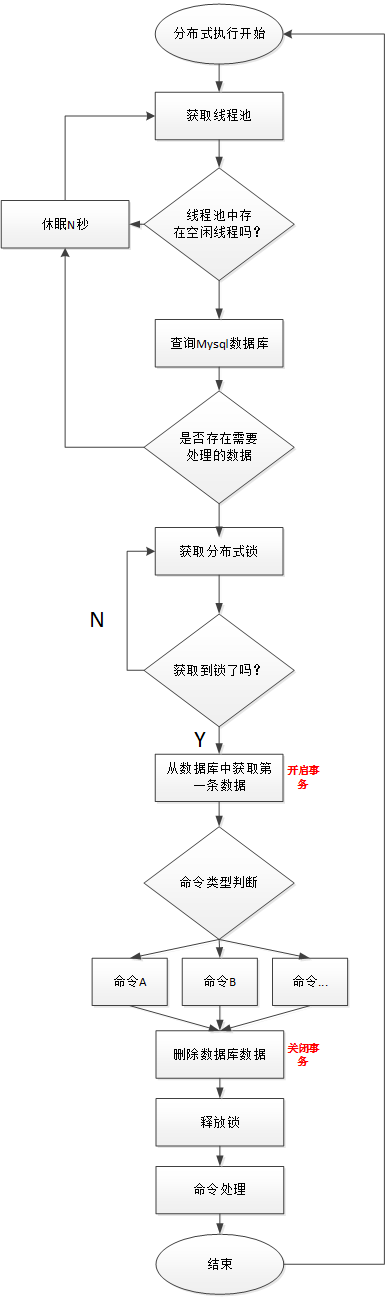
线程不足,循环等待问题:
-
如果一个DAG中没有子流程,则如果Command中的数据条数大于线程池设置的阈值,则直接流程等待或失败。
-
如果一个大的DAG中嵌套了很多子流程,如下图:
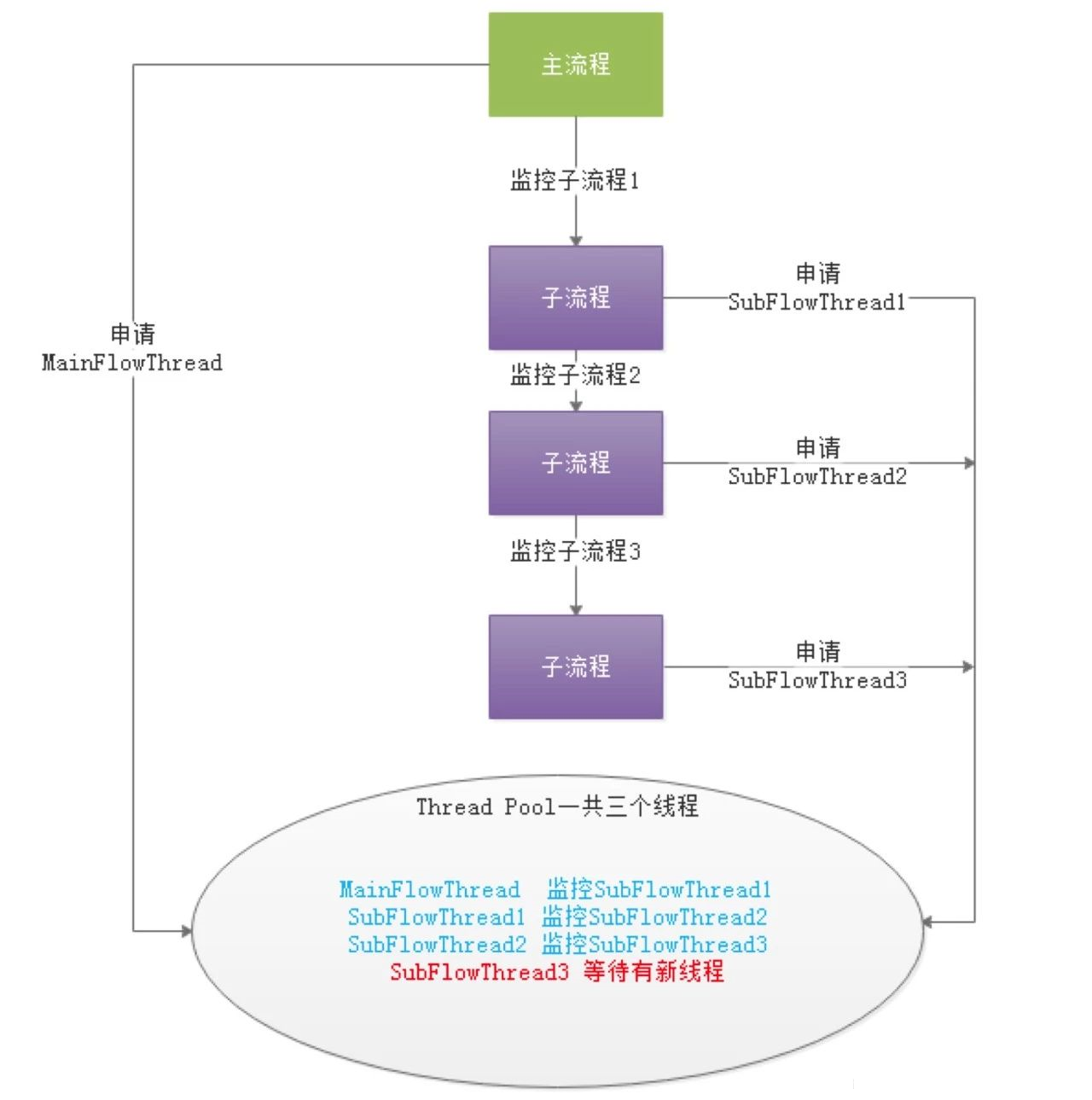
则会产生“死等”状态。MainFlowThread等待SubFlowThread1结束,
SubFlowThread1等待SubFlowThread2结束,SubFlowThread2等待SubFlowThread3结束,而SubFlowThread3等待线程池有新线程,则整个DAG流程不能结束,从而其中的线程也不能释放。这样就形成的子父流程循环等待的状态。此时除非启动新的Master来增加线程来打破这样的”僵局”,否则调度集群将不能再使用。
对于启动新Master来打破僵局,似乎有点差强人意,于是我们提出了以下三种方案来降低这种风险:
-
计算所有Master的线程总和,然后对每一个DAG需要计算其需要的线程数,也就是在DAG流程执行之前做预计算。因为是多Master线程池,所以总线程数不太可能实时获取。
-
对单Master线程池进行判断,如果线程池已经满了,则让线程直接失败。
-
增加一种资源不足的Command类型,如果线程池不足,则将主流程挂起。这样线程池就有了新的线程,可以让资源不足挂起的流程重新唤醒执行。
注意:Master Scheduler线程在获取Command的时候是FIFO的方式执行的。
3、集群节点挂掉等异常容错处理
容错设计依赖于Zookeeper的Watcher机制,实现原理如下
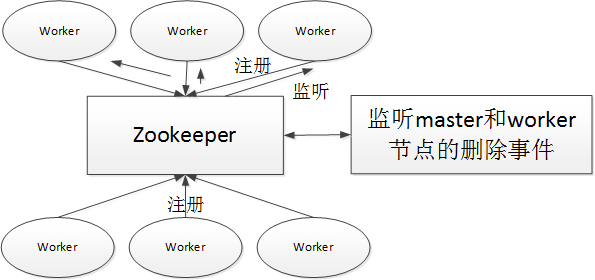
Master监控其他Master和Worker的目录,如果监听到remove事件,则会根据具体的业务逻辑进行流程实例容错或者任务实例容错。
Master容错流程图:

ZooKeeper Master容错完成之后则重新由EasyScheduler中Scheduler线程调度,遍历 DAG 找到”正在运行”和“提交成功”的任务,对”正在运行”的任务监控其任务实例的状态,对”提交成功”的任务需要判断Task Queue中是否已经存在,如果存在则同样监控任务实例的状态,如果不存在则重新提交任务实例。
Worker容错流程图:
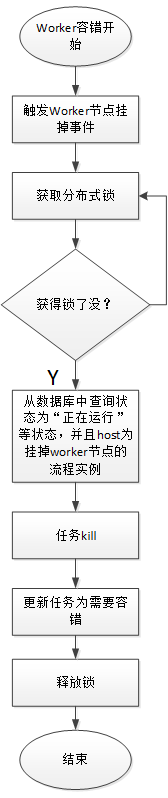
Master Scheduler线程一旦发现任务实例为” 需要容错”状态,则接管任务并进行重新提交。
由于“网络抖动”可能会使得节点短时间内失去和zk的心跳,从而发生节点的remove事件。对于这种情况,我们使用最简单的方式,那就是节点一旦和zk发生超时连接,则直接将Master或Worker服务停掉。
任务失败重试处理:
失败分为:任务失败重试、流程失败恢复、流程失败重跑。
- 任务失败重试是任务级别的,是调度系统自动进行的,比如一个Shell任务设置重试次数为3次,那么在Shell任务运行失败后会自己再最多尝试运行3次
- 流程失败恢复是流程级别的,是手动进行的,恢复是从只能从失败的节点开始执行或从当前节点开始执行
- 流程失败重跑也是流程级别的,是手动进行的,重跑是从开始节点进行
我们将工作流中的任务节点分了两种类型。
-
一种是业务节点,这种节点都对应一个实际的脚本或者处理语句,比如Shell节点,MR节点、Spark节点、依赖节点等。
-
还有一种是逻辑节点,这种节点不做实际的脚本或语句处理,只是整个流程流转的逻辑处理,比如子流程节等。
每一个业务节点都可以配置失败重试的次数,当该任务节点失败,会自动重试,直到成功或者超过配置的重试次数。逻辑节点不支持失败重试。但是逻辑节点里的任务支持重试。
如果工作流中有任务失败达到最大重试次数,工作流就会失败停止,失败的工作流可以手动进行重跑操作或者流程恢复操作
4、日志查看实现
由于Web Application和Worker不一定在同一台机器上,所以查看日志不能像查询本地文件那样。有两种方案:
-
将日志放到ES搜索引擎上存储,通过对es进行查询。
-
通过gRPC通信获取远程日志信息
介于考虑到尽可能的系统设计的轻量级性,所以选择了gRPC实现远程访问日志信息。
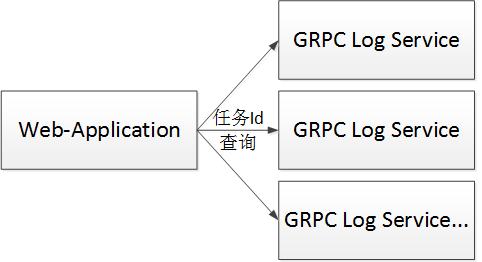
GRPC的传输的性能以及I/O都比较高,日志查询起来也很快。
5、任务优先级设计
如果没有优先级设计,采用公平调度设计的话,会遇到先行提交的任务可能会和后继提交的任务同时完成的情况,而不能做到设置流程或者任务的优先级,因此我们对此进行了重新设计,目前我们设计如下:
-
按照不同流程实例优先级优先于同一个流程实例优先级优先于同一流程内任务优先级优先于同一流程内任务提交顺序依次从高到低进行任务处理。
-
具体实现是根据任务实例的json解析优先级,然后把流程实例优先级流程实例id任务优先级_任务id信息保存在ZooKeeper任务队列中,当从任务队列获取的时候,通过字符串比较即可得出最需要优先执行的任务。
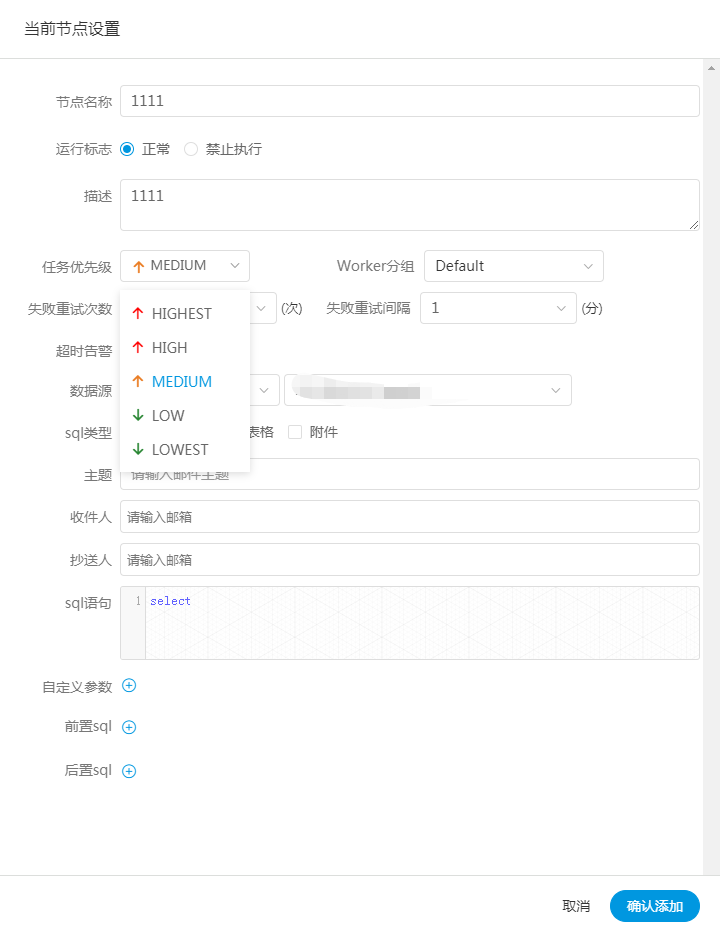
- 流程定义的优先级是考虑到有些流程需要先于其他流程进行处理,这个可以在流程启动或者定时启动时配置,共有5级,依次为HIGHEST、HIGH、MEDIUM、LOW、LOWEST
- 任务的优先级也分为5级,依次为HIGHEST、HIGH、MEDIUM、LOW、LOWEST,如下图所示
-
-