一、模型介绍
合成运动丰富且时间一致的视频仍然是人工智能领域的一项挑战,尤其是在处理较长的持续时间时。现有的文本到视频 (T2V) 模型通常采用空间交叉注意进行文本控制,等效地指导不同帧的生成而无需特定于帧的文本指导。因此,模型理解提示中传达的时间逻辑并生成具有连贯运动的视频的能力受到限制。为了解决这一限制,我们引入了 FancyVideo ,这是一种创新的视频生成器,它通过精心设计的跨帧文本指导模块 (CTGM) 改进了现有的文本控制机制。具体而言,CTGM 分别在交叉注意的开始、中间和结束时结合了时间信息注入器 (TII)、时间亲和力细化器 (TAR) 和时间特征增强器 (TFB),以实现特定于帧的文本指导。
二、模型搭建流程
基础环境最低要求说明:
| 环境名称 | 版本信息1 |
|---|---|
| Ubuntu | 22.04.4 LTS |
| CUDA | 12.1 |
| Python | 3.10 |
| NVIDIA Corporation | RTX 3090 |
| 模型大小 | 超过 100G,需要数据盘扩容 |
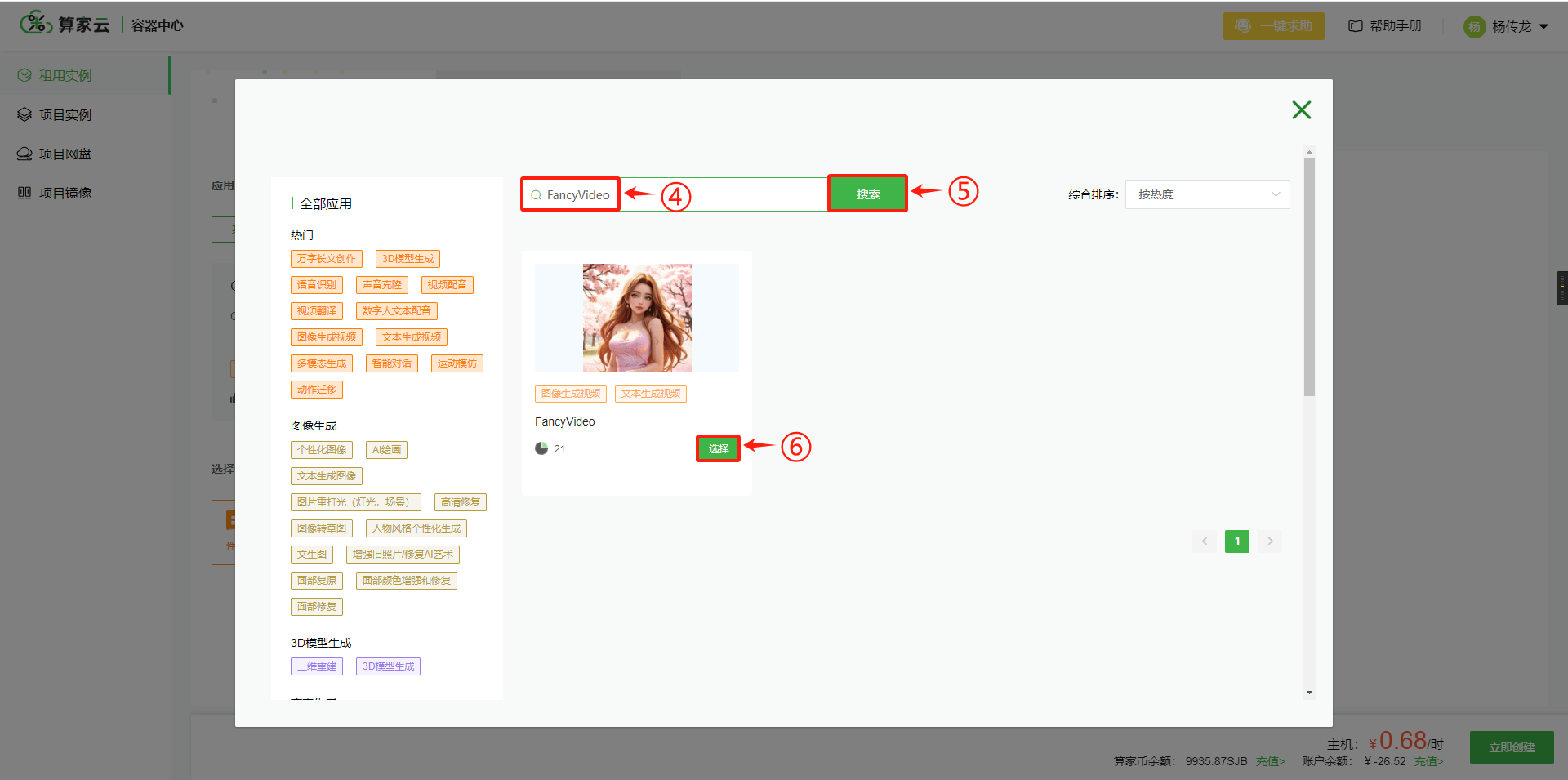
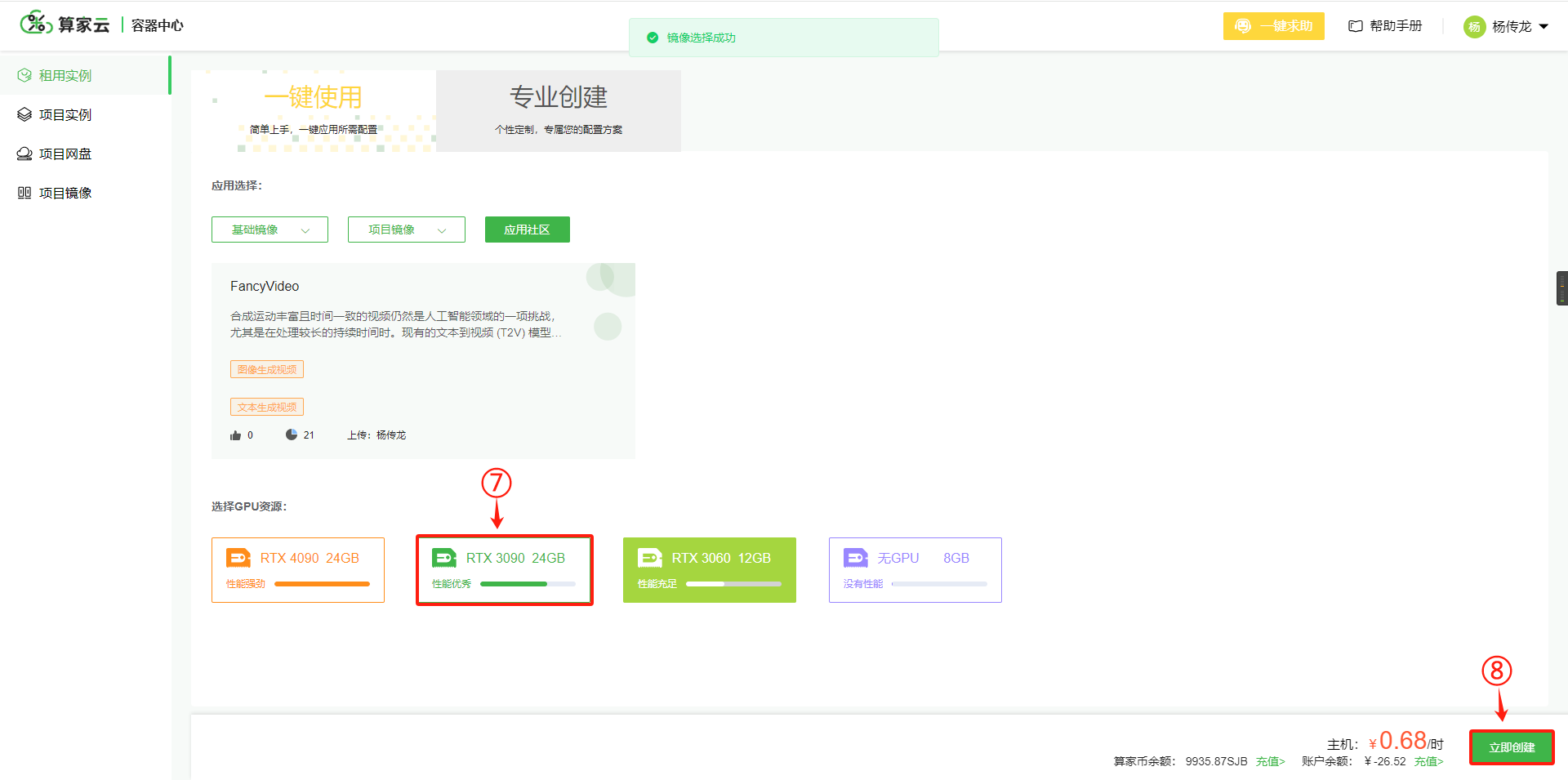
1. 根据需求选择主机和镜像,进行一键创建实例
租用实例 --》一键使用 --》进入“应用社区”–》搜索并选择“FancyVideo” 大模型 –》选择RTX 3090 GPU,即可在平台进行实例创建。

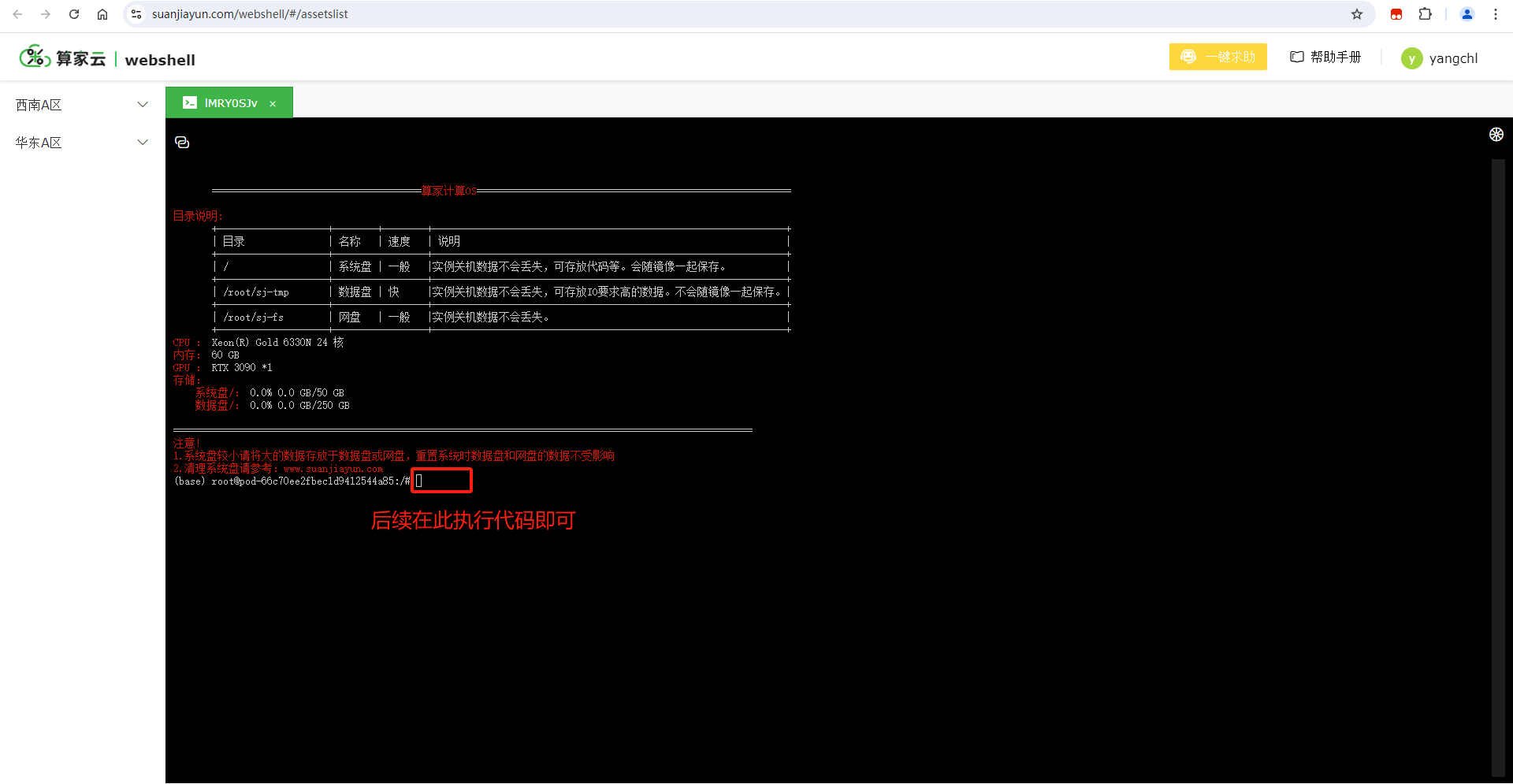
2. 进入网页端命令行
项目实例 --》点击“WebSSH”–》执行“启动 web 页面”的相关命令

3. 下载预训练模型
在启动应用程序之前,运行以下命令以自动下载所需的模型:
# 递归复制FancyVideo目录及其所有子目录和文件到/root/sj-tmp/目录下
cp -r /FancyVideo/ /root/sj-tmp/
# 切换到/root/sj-tmp/FancyVideo/目录,假设上一步成功执行,这个目录现在存在
cd /root/sj-tmp/FancyVideo/
# 安装Git LFS(Large File Storage),这是一个Git的扩展,允许你版本控制大文件
# 注意:这一步通常在你打算使用Git LFS来管理大文件时才需要
git lfs install
# 尝试从https://hf-mirror.com/qihoo360/FancyVideo克隆一个Git仓库到当前目录
# fancyvideo-ckpts & cv-vae & res-adapter & longclip & sdv1.5-base-models
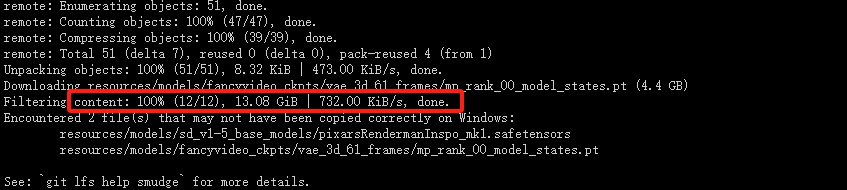
git clone https://hf-mirror.com/qihoo360/FancyVideo

下载成功如下图
移动模型:
mv FancyVideo/resources/models resources/
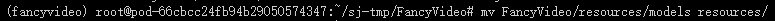
继续下载模型
git lfs install
git clone https://hf-mirror.com/runwayml/stable-diffusion-v1-5 resources/models/stable-diffusion-v1-5

下载模型后,你的资源文件夹如下:
📦 resouces/
├── 📂 models/
│ └── 📂 fancyvideo_ckpts/
│ └── 📂 CV-VAE/
│ └── 📂 res-adapter/
│ └── 📂 LongCLIP-L/
│ └── 📂 sd_v1-5_base_models/
│ └── 📂 stable-diffusion-v1-5/
├── 📂 demos/
│ └── 📂 reference_images/
│ └── 📂 test_prompts/
4. 启动 webgui.py 文件
# 导航到项目目录
cd /root/sj-tmp/FancyVideo/
# 激活 fancyvideo 虚拟环境
conda activate fancyvideo
# 运行 app.py 文件
python app.py
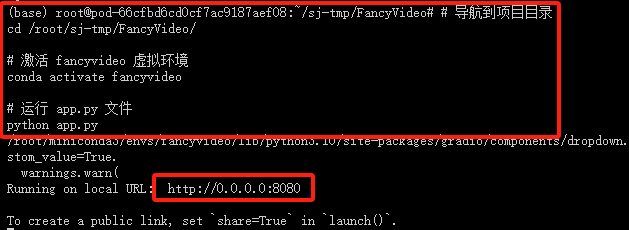
5. 获取端口号
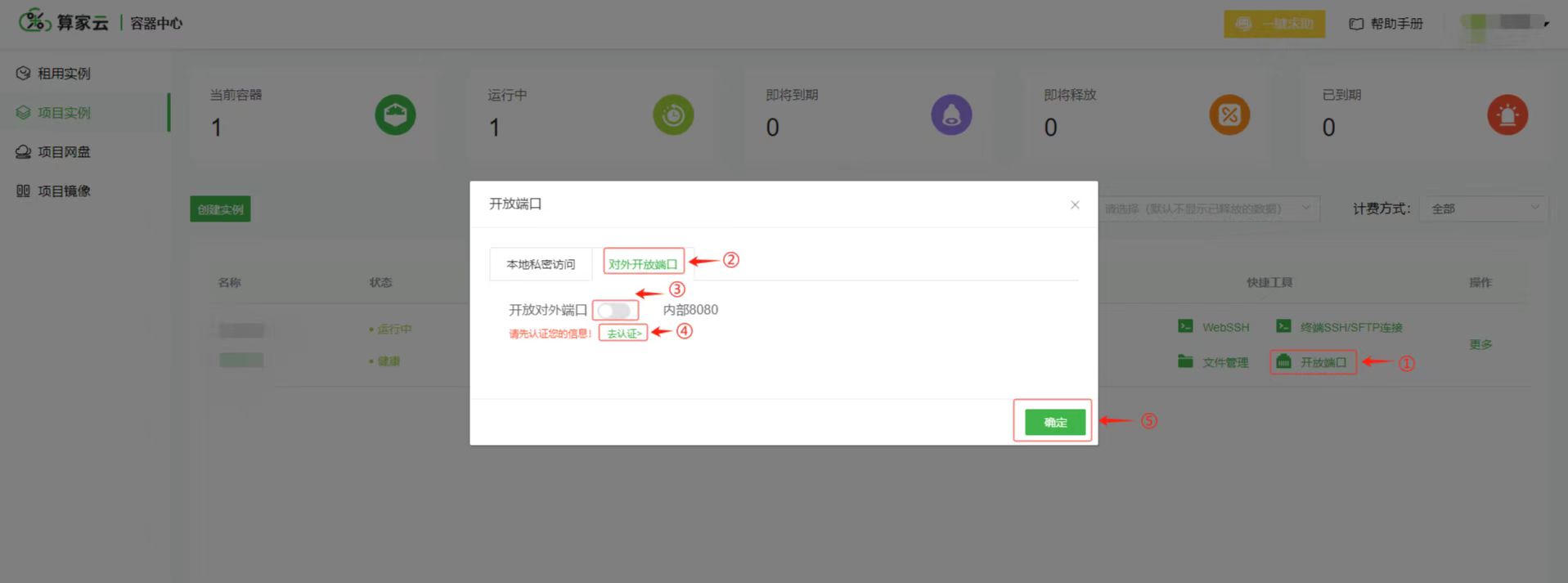
6. 进入 web 页面
将获取到的链接复制到本地浏览器:
# 比如当前获取的地址如下:
http://xn-a.suanjiayun.com:30992
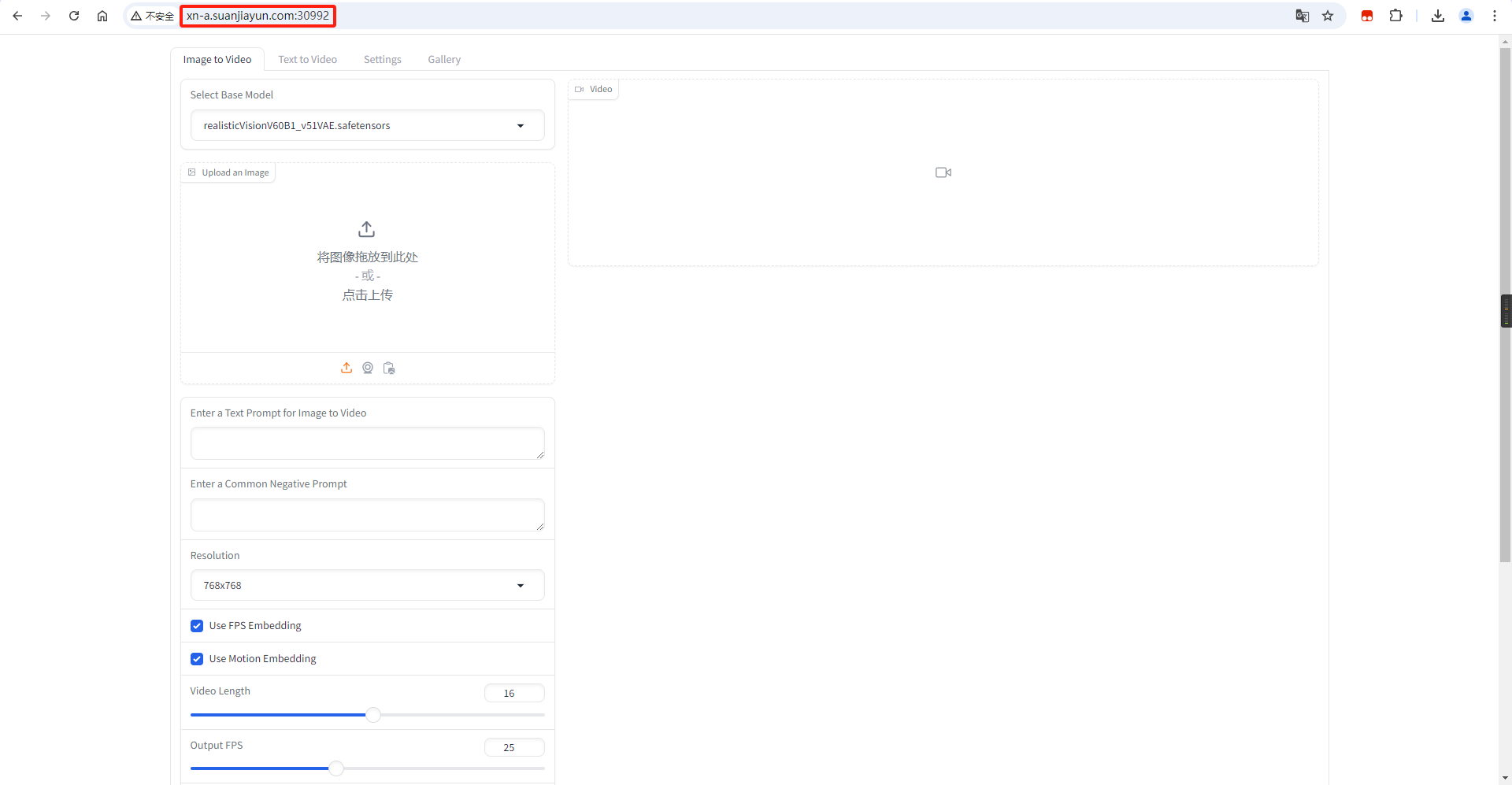
复制下方网址,进入算家云,选择模型,一键开启 AI 之旅!
算家云应用社区 www.suanjiayun.com/container/#/mirror















![Pycharm can‘t open file ‘D:\\Program‘: [Errno 2] No such file or directory](https://i-blog.csdnimg.cn/direct/fa09725f694e44dd965aa160b542877c.png)



