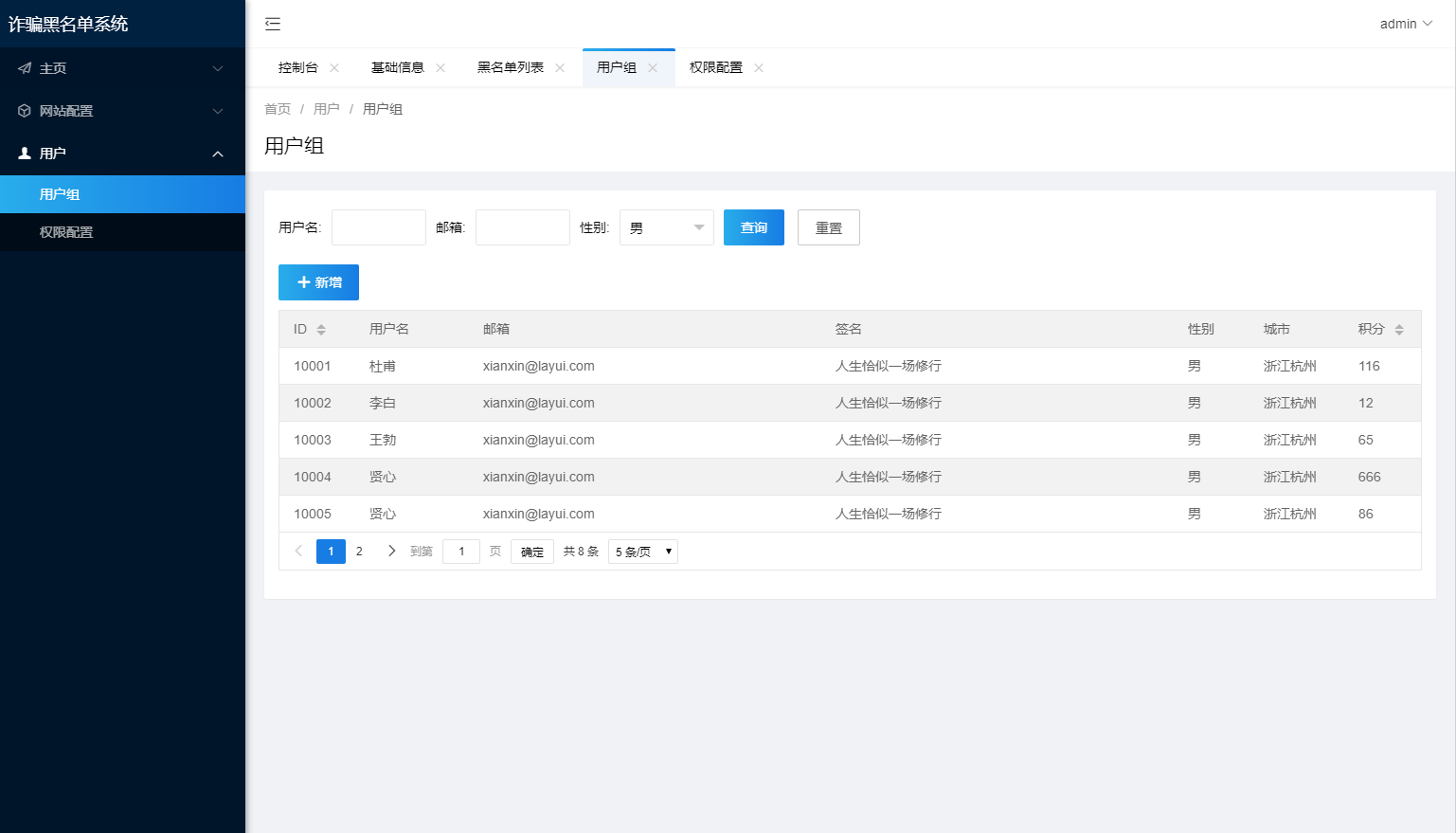
引言:一场跨数据库的浪漫邂逅 💑
在数据的世界里,不同数据库系统就像是来自不同星球的恋人,它们各自拥有独特的魅力,但偶尔也会渴望一场跨越界限的亲密接触。今天,我们就来见证一场PostgreSQL与MySQL之间的浪漫邂逅——定时获取PostgreSQL中的数据,并将其温柔地同步至MySQL的怀抱中。这不仅是一场技术的挑战,更是一次数据流转的艺术展现!
场景设定:数据的星际旅行 🚀
想象一下,你是一位数据守护者,负责管理着两个星球的数据库:PostgreSQL的“科技星球”和MySQL的“人文星球”。每天,你都需要从“科技星球”收集最新的科研成果(数据),然后运送到“人文星球”上,让那里的居民也能享受到科技进步的果实。
思路分析:星际导航图 🗺️
要完成这场星际旅行,我们需要精心规划航线:
启航准备:确保两艘飞船(数据库连接)都已就绪,且飞船上的储物舱(数据表)结构相似,便于数据转移。
坐标定位:首先,从PostgreSQL中读取最新的数据ID,这是我们的“出发坐标”。然后,在MySQL中查询最新的数据ID,作为我们的“目标坐标”。
航线规划:通过比较两个坐标的差距,我们可以确定哪些数据是新增的,需要被“运送”到MySQL。这就像是在浩瀚的数据海洋中,绘制出一条最优的航线。
数据转移:根据规划好的航线,将选定的数据从PostgreSQL中提取出来,并安全地“降落”在MySQL的相应位置。
实战代码:编写星际导航程序 💻
虽然具体的代码实现需要你们自己来完成(因为你们才是这场冒险的主角!),但我可以给你们一个大致的框架,就像是一个星际导航程序的伪代码:
# 假设这是你的星际导航程序
def connect_to_postgresql():
# 连接PostgreSQL数据库,获取连接对象
# ...
return pg_connection
def connect_to_mysql():
# 连接MySQL数据库,获取连接对象
# ...
return mysql_connection
def fetch_latest_ids(connection, table_name):
# 从指定数据库中获取最新数据ID
# 使用SQL查询,如 SELECT MAX(id) FROM table_name
# ...
return latest_id
def sync_data(pg_connection, mysql_connection, source_table, target_table):
# 1. 获取两个数据库的最新ID
pg_latest_id = fetch_latest_ids(pg_connection, source_table)
mysql_latest_id = fetch_latest_ids(mysql_connection, target_table)
# 2. 确定需要同步的数据范围
if pg_latest_id > mysql_latest_id:
# 3. 编写SQL查询,选择ID在mysql_latest_id到pg_latest_id之间的数据
# 4. 执行查询,获取数据
# 5. 编写SQL语句,将获取的数据插入MySQL
# ...
# 定时执行数据同步任务
# 可以使用APScheduler等库来实现定时任务
结尾:星际旅行的意义 🌟
通过这场PostgreSQL到MySQL的数据同步冒险,我们不仅实现了数据的跨库流动,更深刻体会到了数据在不同系统间共享的重要性。正如星际旅行不仅仅是为了探索未知,更是为了促进不同文明之间的交流与融合。希望这次经历能激发你们对数据世界更多奇妙的想象和探索!
实际源码
"""
功能:
监测数据表是否更新
连接postgresql
连接mysql
比较-同步
"""
import sys
import pymysql
import psycopg2
import pandas as pd
import numpy as np
dbname_mysql = 'followup'
table_name_list_mysql = ['s01_issue_table',
'np_kickoff','np_rfq',
's02_np_kickoff','s02_np_rfq',
's06_kick_off_list','s06rfqlist']
dbname_postgresql = 'lcmbigdata'
table_name_list_postgresql = ['s01_issue_table',
'np_kickoff','np_rfq',
's02_np_kickoff','s02_np_rfq',
's06_kick_off_list','s06rfqlist']
col_address_lists = [['create_time', 'update_time'],
['create_time', 'update_time','kickoffdate'],['create_time', 'update_time','evaluation_date'],
['create_time', 'update_time','kickoffdate'],['create_time', 'update_time','evaluation_date'],
['create_time', 'update_time','kickoffdate'],['create_time', 'update_time','evaluation_date']]
modelname_postgresql = 'digitalelf'
# 数据库连接参数
conn_params_mysql = {
"database": dbname_mysql,
"user": "root",
"password": "root",
"host": "localhost",
"port": 3306 # 端口号应该是整数
}
conn_params_postgresql = {
"database": dbname_postgresql,
"user": "postgres", # 数据库用户
"password": "root", # 数据库密码
"host": "localhost", # 数据库服务器地址
"port": 6666 # 数据库端口
}
issue_columns = ['id' ,'model_no' ,'part_no' ,'issue_type', 'issue_from', 'start_date',
'end_date' ,'status', 'priority', 'fab', 'issue_description', 'root_cause',
'customer' ,'customer_operation' ,'phase', 'analysis', 'solution', 'progress',
'lesson_learnt' ,'create_by' ,'create_time', 'update_by', 'update_time',
'sys_org_code' ,'site', 'issue_owner', 'is_nudd' ,'attachment' ,'issue_dept',
'issue_update' ,'func', 'material_structure']
kickoff_columns = ['id', 'week', 'jiazhi', 'jishu', 'modelno', 'pn', 'customer', 'technology', 'cellsite', 'kickoffdate', 'mpdate', 'dvtdate', 'fcst', 'design_processremark', 'yingyong', 'kickoff_gopremium', 'jingzhengduishou', 'kehu_shiyong_fangshi', 'odm', 'others_feiyong', 'renli_target', 'fy_target', 'mpiowner', 'mpi_bumen', 'pm', 'create_by', 'create_time', 'update_by', 'update_time', 'sys_org_code']
rfq_columns = ['id', 'model_no', 'customer', 'evaluation_date', 'rfq_result', 'fail_cause', 'create_by', 'create_time', 'update_by', 'update_time', 'sys_org_code']
s02_kickoff_columns = ['id', 'week', 'customer', 'technology', 'odm', 'pm', 'create_by', 'create_time', 'update_by', 'update_time', 'sys_org_code', 'renli_target', 'fy_target', 'jiazhi', 'jishu', 'pn', 'cellsite', 'kickoffdate', 'mpdate', 'dvtdate', 'fcst', 'design_processremark', 'yingyong', 'kickoff_gopremium', 'jingzhengduishou', 'kehu_shiyong_fangshi', 'others_feiyong', 'mpiowner', 'mpi_bumen', 'modelno']
s02_rfq_columns = ['id', 'customer', 'create_by', 'create_time', 'update_by', 'update_time', 'sys_org_code', 'model_no', 'evaluation_date', 'rfq_result', 'fail_cause']
s06_kickoff_columns = ['id', 'modelno', 'technology', 'cellsite', 'fcst', 'jingzhengduishou', 'odm', 'mpiowner', 'pm', 'create_by', 'create_time', 'update_by', 'update_time', 'sys_org_code', 'week', 'jiazhi', 'jishu', 'kickoff_gopremium', 'pn', 'customer', 'kickoffdate', 'mpdate', 'dvtdate', 'yingyong', 'kehu_shiyong_fangshi', 'others_feiyong', 'renli_target', 'fy_target', 'design_processremark', 'mpi_bumen']
s06_rfq_columns = ['id', 'create_by', 'create_time', 'update_by', 'update_time', 'sys_org_code', 'model_no', 'customer', 'evaluation_date', 'rfq_result', 'fail_cause']
columns_names = [issue_columns,
kickoff_columns,rfq_columns,
s02_kickoff_columns,s02_rfq_columns,
s06_kickoff_columns,s06_rfq_columns]
sql_host = 'localhost'
port = 3306
user = 'root'
password = 'root'
sql_db_name = 'followup'
# sql_table_name = 'np_issue'
def replace_nan_with_none(value):
"""将 numpy.nan 替换为 None,其他值保持不变。"""
return None if np.isnan(value) else value
# #数据库SQL上传函数
def sql_connect():
try:
conn = pymysql.connect(
host = sql_host,
port = port,
user = user,
password = password,
db = sql_db_name,
charset='utf8')
return conn
except Exception as e:
logging.error('SQL CONNECT' + str(e))
def sql_upload(raw_data, table_name):
"""
将DataFrame raw_data写入MySQL数据库指定的table_name表中。
"""
# 连接数据库
conn = sql_connect()
cursor = conn.cursor()
# 确保表存在,如果不存在则创建表
# 注意:这里简化了表的创建过程,实际应用中可能需要根据raw_data的列名和数据类型创建合适的表结构
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS {table_name} (
-- 假设所有列都是VARCHAR类型,实际情况应根据raw_data的列调整
flag VARCHAR(255),
period VARCHAR(255),
dept VARCHAR(255),
-- 其他列...
bd VARCHAR(255)
);
"""
cursor.execute(create_table_sql)
# 构建插入语句
insert_sql = f"""
INSERT INTO {table_name} ({', '.join(raw_data.columns)})
VALUES ({', '.join(['%s'] * len(raw_data.columns))});
"""
# 执行插入语句
for index, row in raw_data.iterrows():
try:
# 处理列表中的每个元素
# print("index:\n",index)
row_list = list(row)
for i in range(len(row_list)):
if row_list[i] is np.nan:
row_list[i] = replace_nan_with_none(row_list[i])
# if np.nan in row:
# cleaned_row = [replace_nan_with_none(x) for x in list(row)]
cursor.execute(insert_sql, row_list)
conn.commit()
except Exception as e:
print("上传失败:", e)
print(insert_sql,list(row))
conn.rollback()
cursor.close()
conn.close()
print("数据成功上传至数据库")
def data_update_PostgreSQL_MySQL(data_type_tips):
for i in range(0,len(table_name_list_mysql)):
# i=1
print("🦁"*30)
print(f"第{data_type_tips}次更新{table_name_list_mysql[i]}")
print("🐎" * 30)
table_name_mysql = table_name_list_mysql[i]
table_name_postgresql = table_name_list_postgresql[i]
col_address_list = col_address_lists[i]
data_columns = columns_names[i]
id_list_mysql = []
id_list_postgresql = []
id_difference = []
try:
# 使用连接参数建立PostgreSQL连接
try:
conn_postgresql = psycopg2.connect(**conn_params_postgresql)
# print("成功连接到PostgreSQL数据库")
# 创建一个cursor对象来执行SQL命令
cur_postgresql = conn_postgresql.cursor()
# 执行SQL查询(例如:选择所有记录)
# cur_postgresql.execute(f"SELECT * FROM {dbname}.{your_table_name};")
cur_postgresql.execute(f"SELECT id FROM {dbname_postgresql}.{modelname_postgresql}.{table_name_postgresql};")
# 获取所有查询结果
rows = cur_postgresql.fetchall()
for row in rows:
id_list_postgresql.append(row[0])
# print(row)
except (Exception, psycopg2.DatabaseError) as error:
print(f"PostgreSQL数据库错误:{error}")
# 使用连接参数建立MySQL连接
try:
conn_mysql = pymysql.connect(**conn_params_mysql)
# print("成功连接到MySQL数据库")
# 创建一个cursor对象来执行SQL命令
cur_mysql = conn_mysql .cursor()
# 执行SQL查询(例如:选择所有记录)
# 修复 SQL 查询字符串中的表名引用
#cur.execute(f"SELECT * FROM {your_table_name};")
cur_mysql.execute(f"SELECT id FROM {table_name_mysql};")
# 获取所有查询结果
rows = cur_mysql.fetchall()
for row in rows:
id_list_mysql.append(row[0])
# print(row)
for id in id_list_postgresql:
if id not in id_list_mysql:
# print(id)
id_difference.append(id)
print(len(id_difference))
# print(id_difference)
# sys.exit()
print("🐒"*20)
if len(id_difference):
if len(id_difference) == 1:
cur_postgresql.execute(
f"SELECT * FROM {dbname_postgresql}.{modelname_postgresql}.{table_name_postgresql} where id = '{id_difference[0]}';")
else:
id_difference = tuple(id_difference)
cur_postgresql.execute(f"SELECT * FROM {dbname_postgresql}.{modelname_postgresql}.{table_name_postgresql} where id in {id_difference};")
"""新入新的数据库"""
# 获取所有查询结果
rows_new = cur_postgresql.fetchall()
# print(len(rows_new),len(data_columns))
print("🐅" * 20)
rows_pd = pd.DataFrame(rows_new, columns=data_columns)
print("🐍"*20)
# print(len(rows_pd.columns),len(rows_new),len(data_columns))
print("🐉" * 20)
# 处理 DataFrame 中的日期时间列
for col in data_columns:
data_type = rows_pd[col].dtype
if 'datetime64[ns, UTC+08:00]' in str(data_type):
# 移除时区信息
rows_pd[col] = rows_pd[col].dt.tz_localize(None)
# 将日期时间转换为字符串格式
rows_pd[col] = rows_pd[col].dt.strftime('%Y-%m-%d %H:%M:%S')
sql_upload(rows_pd, table_name_mysql)
print(f"已同步{len(id_difference)}条记录至{table_name_mysql}")
# print('★' * 10, '\n', 'successs')
else:
print(f"已同步{len(id_difference)}条记录至{table_name_mysql}")
except (Exception, pymysql.DatabaseError) as error:
print(f"MySQL数据库错误:{error}")
finally:
# 关闭cursor和连接
if cur_postgresql:
cur_postgresql.close()
if conn_postgresql:
conn_postgresql.close()
# print("PostgreSQL数据库连接已关闭")
# 关闭cursor和连接
if cur_mysql:
cur_mysql.close()
if conn_mysql :
conn_mysql .close()
# print("MySQL数据库连接已关闭")
except Exception as e:
print(f"数据库同步ERROR {e}")
def data_update():
for i in range(1,3):
# print(f"第{i}次更新数据库")
data_update_PostgreSQL_MySQL(i)
data_update()
运行结果

增加定时功能
import schedule
import time
def data_update():
print("Updating data...")
# 每15分钟执行一次
schedule.every(15).minutes.do(data_update)
while True:
schedule.run_pending()
time.sleep(1)