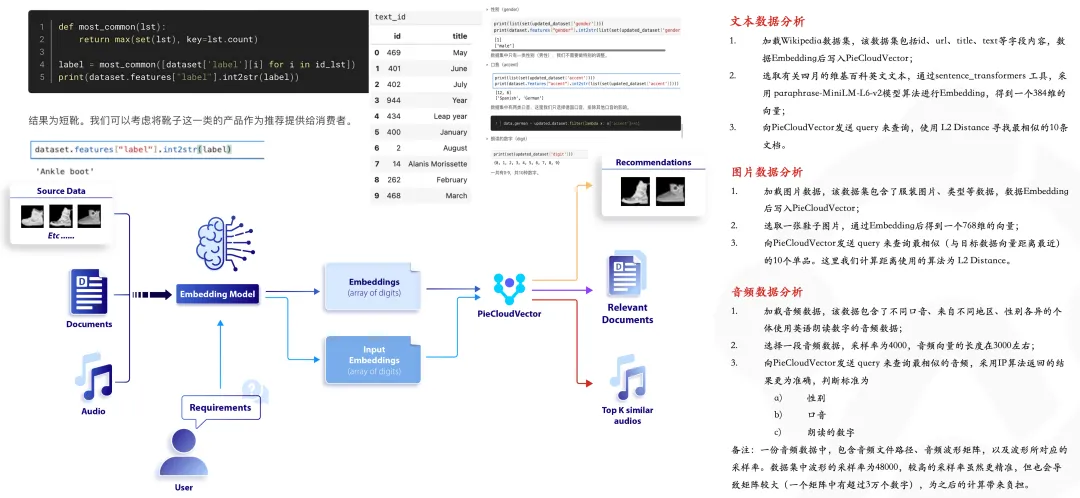
LlamaDecoderLayer源码解析
- 1. LlamaDecoderLayer 介绍
- 2. LlamaDecoderLayer 类源码解析
1. LlamaDecoderLayer 介绍
LlamaDecoderLayer 是 LLaMA 模型中的一个关键组件,它结合了自注意力机制、全连接层和残差连接,以及对输入数据的归一化。主要流程为:
- 输入归一化:在进入自注意力模块之前,首先对输入的隐藏状态进行归一化处理
- 自注意力计算:将归一化后的隐藏状态传递给自注意力模块
- 残差连接:将自注意力处理后的隐藏状态与输入状态进行相加
- 后注意力处理:对残差连接后的隐藏状态进行后注意力归一化处理
- 全连接层处理:对隐藏状态进一步处理
- 最终残差连接:将经过全连接层处理后的隐藏状态与处理前的隐藏状态进行相加,再次形成残差连接
- 返回输出:返回最终的隐藏状态
Llama Decoder Layer 的结构如下:

2. LlamaDecoderLayer 类源码解析
源码地址:transformers/src/transformers/models/llama/modeling_llama.py
# -*- coding: utf-8 -*-
# @time: 2024/8/28 14:52
import torch
from typing import Optional, Tuple
from torch import nn
from transformers import LlamaConfig, Cache
from transformers.models.llama.modeling_llama import LlamaAttention, LlamaFlashAttention2, LlamaSdpaAttention, LlamaMLP, LlamaRMSNorm
# 定义一个字典,将不同类型的注意力实现类与字符串名称对应起来
LLAMA_ATTENTION_CLASSES = {
"eager": LlamaAttention, # 默认的注意力实现
"flash_attention_2": LlamaFlashAttention2, # 使用 Flash Attention 2 的实现
"sdpa": LlamaSdpaAttention, # 使用 SDPA 的注意力实现
}
class LlamaDecoderLayer(nn.Module):
def __init__(self, config: LlamaConfig, layer_idx: int):
super().__init__()
self.hidden_size = config.hidden_size # 从配置中获取隐藏层的维度大小
# 根据配置中的注意力实现类型,选择相应的注意力类并实例化
self.self_attn = LLAMA_ATTENTION_CLASSES[config._attn_implementation](config=config, layer_idx=layer_idx)
# 实例化一个全连接层(MLP),用于后续的非线性变换
self.mlp = LlamaMLP(config)
# 输入归一化层,用于规范化输入的隐藏状态
self.input_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
# 注意力后的归一化层,用于规范化经过注意力计算后的隐藏状态
self.post_attention_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
def forward(
self,
hidden_states: torch.Tensor, # 输入的隐藏状态
attention_mask: Optional[torch.Tensor] = None, # 注意力掩码
position_ids: Optional[torch.LongTensor] = None, # 位置编码ID
past_key_value: Optional[Cache] = None, # 缓存的键值对,用于加速推理
output_attentions: Optional[bool] = False, # 是否输出注意力权重
use_cache: Optional[bool] = False, # 是否使用缓存来加速解码
cache_position: Optional[torch.LongTensor] = None, # 缓存中位置的索引
position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, # 位置嵌入,将在v4.45版本中变为必填项
**kwargs, # 其他额外参数,主要用于特殊情况(如分布式训练)
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`torch.FloatTensor`, *optional*):
attention mask of size `(batch_size, sequence_length)` if flash attention is used or `(batch_size, 1,
query_sequence_length, key_sequence_length)` if default attention is used.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
(see `past_key_values`).
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
Indices depicting the position of the input sequence tokens in the sequence
position_embeddings (`Tuple[torch.FloatTensor, torch.FloatTensor]`, *optional*):
Tuple containing the cosine and sine positional embeddings of shape `(batch_size, seq_len, head_dim)`,
with `head_dim` being the embedding dimension of each attention head.
kwargs (`dict`, *optional*):
Arbitrary kwargs to be ignored, used for FSDP and other methods that injects code
into the model
"""
residual = hidden_states # 保存原始的输入状态,用于后续的残差连接
hidden_states = self.input_layernorm(hidden_states) # 对输入的隐藏状态进行归一化处理
# Self Attention: 执行自注意力计算
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
cache_position=cache_position,
position_embeddings=position_embeddings,
**kwargs, # 传递额外的参数
)
hidden_states = residual + hidden_states # 将注意力输出与原始输入相加,形成残差连接
# Fully Connected
residual = hidden_states # 更新残差连接的值为当前隐藏状态
hidden_states = self.post_attention_layernorm(hidden_states) # 对经过注意力后的隐藏状态进行归一化处理
hidden_states = self.mlp(hidden_states) # 通过全连接层(MLP)进行进一步的处理
hidden_states = residual + hidden_states # 再次形成残差连接
outputs = (hidden_states,) # 输出当前层的隐藏状态
if output_attentions: # 如果需要输出注意力权重,则将其添加到输出中
outputs += (self_attn_weights,)
if use_cache: # 如果使用缓存,则将更新后的键值对添加到输出中
outputs += (present_key_value,)
# 返回输出
return outputs