SwiftBrush v2:让你的一步扩散模型比它的老师更好
Paper Title:SwiftBrush v2: Make Your One-step Diffusion Model Better Than Its Teacher
paper是VinAI Research发表在ECCV 2024的工作
paper地址
Code地址
Abstract.
在本文中,我们旨在提高 SwiftBrush(一种著名的一步式文本到图像扩散模型)的性能,使其与多步稳定扩散模型相媲美。首先,我们探索了 SwiftBrush 和 SD Turbo 之间的质量多样性权衡:前者在图像多样性方面表现出色,而后者在图像质量方面表现出色。这一观察结果促使我们提出了对训练方法的修改,包括更好的权重初始化和高效的 LoRA 训练。此外,我们引入了一种新颖的固定 CLIP 损失,增强了图像文本对齐,从而提高了图像质量。
值得注意的是,通过结合使用高效 LoRA 和完整训练训练的模型的权重,我们实现了一种新的最先进的一步式扩散模型,实现了 8.14 的 FID,超越了所有基于 GAN 和多步稳定扩散模型。项目页面位于:https://swiftbrushv2.github.io/
关键词:一步扩散模型·文本到图像合成
1 Introduction

图 1:我们的一步式扩散模型实现了令人印象深刻的 8.14 FID,通过一次 UNet 前向推理即可生成高质量且多样化的结果。从“一只头上有白色条纹的笑着的可爱灰兔,背景中有一堆金币,色彩鲜艳,迪士尼图片渲染,照片般逼真”(前两行)和“一位看着相机的女人的肖像”(后两行)提示生成的示例图像展示了我们的模型能够快速创建具有视觉吸引力且多样化的输出。
近年来,文本转图像生成技术取得了长足的发展,用户可以根据简单的描述创建高质量的图像。最先进的模型 [3、33、40、42] 可以在艺术竞赛中超越人类 [43],或者生成几乎与真实图像难以区分的合成图像 [7]。在流行的文本转图像网络中,稳定扩散 (SD) 模型 [41、42] 因其开源性而得到最广泛的应用。然而,大多数 SD 模型被设计为多步扩散模型,需要多个前向步骤才能生成输出图像。这种缓慢且计算成本高昂的机制阻碍了这些模型在实时或设备端应用中的使用。
最近,许多研究试图减少文本到图像扩散模型中所需的去噪步骤。值得注意的是,最近很少有研究成功开发出一步扩散模型,从而显著加快图像生成速度。虽然早期的尝试 [13、32] 会产生模糊和畸形的照片,但后续方法可以产生清晰且高质量的输出。这些方法主要将知识从预先训练的多步骤 SD 模型(称为教师模型)蒸馏到一步学生模型。InstaFlow [30] 在多阶段且计算量大的训练过程中采用了 Rectified Flows [29]。
DMD [54] 将重建和分布匹配损失结合作为训练目标,需要教师提供大量预生成的图像。SD Turbo [46] 将对抗性训练与分数蒸馏损失结合起来,实现了逼真的生成。然而,它严重依赖于大规模的图像-文本对训练数据集,并且如后所述,多样性较差。
SwiftBrush [34] 利用变分分数蒸馏 (VSD) 通过 LoRA [17] 中间教师模型将知识从教师网络迁移到一步式学生。值得注意的是,训练 SwiftBrush 简单、快速且无需图像,这是一种有趣的方法。
尽管取得了这些令人鼓舞的成就,但单步文本到图像扩散模型在 FID 度量方面仍然不如多步模型。在标准 COCO 2014 基准 [28] 上,SDv2.1 在无分类器指导 (cfg) 尺度为 2 的情况下可以实现最低的 FID-30K 分数 9.64,而等效参数尺度的单步模型的最佳报告分数为 11.49 [54]。这种差距是意料之中的,因为直接在一步中从噪声中预测出干净的图像比通过多步方案要困难得多。因此,人们可能会认为单步文本到图像模型只能接近或达到与教师模型类似的性能,但永远不会超过它。
在本文中,我们通过寻求一种可以在数量和质量上超越其多步骤教师模型的单步模型来挑战这一信念。我们的解决方案从 SwiftBrush 中汲取灵感,其无图像训练可实现有效、可扩展且灵活的提炼。我们检查其当前状态并将其与 SD Turbo 进行比较。第 4.1 节中的比较强调了质量多样性权衡:SwiftBrush 由于其无图像和动态训练而提供更多样化的输出,而 SD Turbo 由于其对抗性训练而产生高质量但模式崩溃的输出。这种洞察力促使我们使用 SD Turbo 初始化 SwiftBrush 训练,从而显着增强了单步学生模型。此外,我们额外的限制 CLIP 损失与 SwiftBrush 灵活的训练机制相结合,使学生模型能够超越老师。
最后,我们在更大的文本提示数据集上训练学生,以便在老师和学生模型之间更好地进行知识转移。
鉴于资源有限,以及提供有效且经济实惠的模型训练解决方案的目标,我们将训练限制在具有可负担 GPU 小时数的 A100 40GB GPU 上。这种限制条件使我们无法有效地使用限制的 CLIP 损失并完全微调学生模型。因此,我们提出了两种训练方案,一种支持完整的学生模型训练而不需要额外的损失,另一种采用与上述辅助损失相关的基于 LoRA 的模型训练。这两种训练方案都产生了高质量的输出模型,在大多数指标上都超越了所有以前基于一步扩散的方法。特别是在使用简单的权重线性插值合并这两个模型时,我们在 COCO 2014 基准上获得了 FID-30K 为 8.77 的一步模型。这样的学生模型是第一个超越其多步骤教师模型的模型,打破了普遍的看法。它甚至超过了所有基于 GAN 的文本到图像方法 [22, 45],同时还提供近乎实时的速度。通过对最少真实数据进行额外的正则化 [54],我们的合并模型得到进一步增强,FID 分数达到 8.14,为高效、高质量的文本转图像模型树立了新的标准。
总之,我们的贡献包括(1)分析现有的具有代表性的基于扩散的文本到图像模型,以揭示质量与多样性的权衡;(2)简单而有效地整合 SwiftBrush 和 SD Turbo,以结合两者的优点;(3)提出额外的限制性 CLIP 损失,以增强学生网络的图像-文本对齐并超越教师模型;(4)两种资源高效的训练策略来利用上述提议;(5)融合的一步式学生模型,该模型在所有指标上都优于多步骤文本到图像教师模型,并为该领域树立了新的标准。
2 Related Work
2.1 Text-to-Image Generation
文本到图像生成涉及根据输入文本提示合成高质量图像。这项任务已经发展了几十年,从 CUB [48] 和 COCO [28] 等受限领域过渡到 LAION-5B [47] 等通用领域。这种演变是由 CLIP [39] 和 ALIGN [20] 等大型视觉语言模型 (VLM) 的出现推动的。利用这些模型和数据集,人们引入了各种方法,包括自回归模型,如 DALL-E [40]、CogView [11] 和 Parti [55];基于 mask 的 Transformer,如 MUSE [5] 和 MaskGIT [6];基于 GAN 的模型,如 StyleGAN-T [45]、GigaGAN [22];以及扩散模型,如 GLIDE [35]、Imagen [44]、稳定扩散 (SD) [41]、DALL-E2 [40]、DALL-E3 [3] 和 eDiff-I [2]。
其中,扩散模型因其能够生成高质量图像而广受欢迎。然而,它们通常需要多步采样才能生成高质量图像,这限制了它们的实时和设备应用。
2.2 Accelerating Text-to-Image Diffusion Models
加速扩散模型采样的努力包括更快的采样器和蒸馏技术。早期的方法通过结合潜在一致性模型来蒸馏潜在扩散模型,将采样步骤减少到 4-8 步 [9,32]。
最近的研究通过训练从预训练的多步扩散模型中蒸馏出的学生模型,实现了一步式文本到图像的生成,采用了各种技术,例如整流流 [30]、重建和分布匹配损失 [54] 和对抗性目标 [27,46,52,57]。然而,输出图像通常表现出模糊和伪影,并且一步式方法与多步模型相比仍然表现不佳,同时需要大规模文本图像对进行训练。
SwiftBrush [34] 提出了一种只需对提示输入进行训练的一步式蒸馏技术,与其他方法有所不同。该方法通过中间的 LoRA 多步教师,逐步将知识从教师传授给一步学生。SwiftBrush 的无图像训练程序提供了一种简单的方法来扩展训练数据,并通过辅助损失来扩展学生模型的能力,而不受有限大小的图像训练数据的限制。因此,尽管 SwiftBrush 在质量上与教师模型相比还存在差距,但我们认为它具有很大的进一步发展潜力,可以产生一步法学生模型,甚至在多步教师模型的比赛中击败它。
3 Background
扩散模型是生成模型,通过模拟扩散过程将噪声分布转换为目标数据分布。这一转换过程涉及在 T T T 步中逐步向干净图像 x 0 \mathbf{x}_0 x0 添加噪声 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I)(前向过程),然后学习逆转该过程(逆向过程)。前向过程可以表示为:
x t = α t x 0 + σ t ϵ ∀ t ∈ 0 , T ‾ \mathbf{x}_t=\alpha_t \mathbf{x}_0+\sigma_t \epsilon \quad \forall t \in \overline{0, T} xt=αtx0+σtϵ∀t∈0,T
其中 x t \mathbf{x}_t xt 是时间步 t t t 的数据, { ( α t , σ t ) } t = 1 T \left\{\left(\alpha_t, \sigma_t\right)\right\}_{t=1}^T {(αt,σt)}t=1T 是噪声调度,满足 ( α T , σ T ) = ( 0 , 1 ) \left(\alpha_T, \sigma_T\right)=(0,1) (αT,σT)=(0,1) 和 ( α 0 , σ 0 ) = ( 1 , 0 ) \left(\alpha_0, \sigma_0\right)=(1,0) (α0,σ0)=(1,0)。另一方面,逆向过程旨在从噪声中重建原始数据。训练的目标是最小化由模型 ϵ ϕ \epsilon_\phi ϵϕ(由 ϕ \phi ϕ 参数化)预测的输出与实际添加的噪声之间的差异:
min ϕ E t ∼ U ( 0 , T ) , ϵ ∼ N ( 0 , I ) ∥ ϵ ϕ ( x t , t ) − ϵ ∥ 2 2 \min _\phi \mathbb{E}_{t \sim \mathcal{U}(0, T), \epsilon \sim \mathcal{N}(0, I)}\left\|\epsilon_\phi\left(\mathbf{x}_t, t\right)-\epsilon\right\|_2^2 ϕminEt∼U(0,T),ϵ∼N(0,I)∥ϵϕ(xt,t)−ϵ∥22
文本生成图像的扩散模型通过在推理过程中集成文本嵌入来生成图像,旨在使文本描述与视觉输出对齐。一个关键挑战是缺乏确保文本相关性和图像保真度的机制。为了解决这个问题,大规模的文本生成图像扩散模型通常使用无分类器引导方法,在不使用单独分类器的情况下增强文本与图像的对齐。这是通过将模型的有文本条件和无文本条件的输出进行插值来实现的,控制因素是引导尺度 γ \gamma γ。模型的最终输出为:
ϵ ^ ϕ ( x t , t , y ) = ϵ ϕ ( x t , t , y ) + γ ⋅ ( ϵ ϕ ( x t , t , y ) − ϵ ϕ ( x t , t ) ) \hat{\epsilon}_\phi\left(\mathbf{x}_t, t, \mathbf{y}\right)=\epsilon_\phi\left(\mathbf{x}_t, t, \mathbf{y}\right)+\gamma \cdot\left(\epsilon_\phi\left(\mathbf{x}_t, t, \mathbf{y}\right)-\epsilon_\phi\left(\mathbf{x}_t, t\right)\right) ϵ^ϕ(xt,t,y)=ϵϕ(xt,t,y)+γ⋅(ϵϕ(xt,t,y)−ϵϕ(xt,t))
其中 ϵ ϕ ( x t , t , y ) \epsilon_\phi\left(\mathbf{x}_t, t, \mathbf{y}\right) ϵϕ(xt,t,y) 是在文本嵌入 y \mathbf{y} y 条件下的预测输出,而 ϵ ϕ ( x t , t ) \epsilon_\phi\left(\mathrm{x}_t, t\right) ϵϕ(xt,t) 是无条件预测,即使用空文本的情况。这个公式展示了无分类器引导如何直接影响生成过程,从而产生更精确和相关的图像输出。
SwiftBrush [34] 是一种一步文本生成图像的生成模型,采用了一种受文本生成3D方法启发的无图像蒸馏技术。这种方法的核心是重新利用变分得分蒸馏(VSD)[49],一种新颖的损失函数,用来解决早期文本生成3D工作中常见的过度平滑和多样性减少问题 [38]。具体来说,SwiftBrush 使用了两个教师模型,一个是冻结的教师模型 ϵ ϕ \epsilon_\phi ϵϕ,另一个是 LoRA [17] 教师模型 ϵ ψ \epsilon_\psi ϵψ,以指导一步学生模型 f θ f_\theta fθ。其中,LoRA 教师模型旨在弥合冻结教师模型与学生模型之间的差距。一方面,学生模型的训练损失形式化为:
∇ θ L V S D = E t , y , z [ w ( t ) ( ϵ ^ ϕ ( x t , t , y ) − ϵ ^ ψ ( x t , t , y ) ) ∂ f θ ( z , y ) ∂ θ ] \nabla_\theta \mathcal{L}_{VSD} = \mathbb{E}_{t, \mathbf{y}, \mathbf{z}}\left[w(t)\left(\hat{\epsilon}_\phi\left(\mathbf{x}_t, t, \mathbf{y}\right)-\hat{\epsilon}_\psi\left(\mathbf{x}_t, t, \mathbf{y}\right)\right) \frac{\partial f_\theta(\mathbf{z}, \mathbf{y})}{\partial \theta}\right] ∇θLVSD=Et,y,z[w(t)(ϵ^ϕ(xt,t,y)−ϵ^ψ(xt,t,y))∂θ∂fθ(z,y)]
其中, z ∼ N ( 0 , I ) \mathbf{z} \sim \mathcal{N}(0, I) z∼N(0,I) 是输入到学生网络的噪声, x t = α t x ^ 0 + σ t ϵ \mathbf{x}_t=\alpha_t \hat{\mathbf{x}}_0+\sigma_t \epsilon xt=αtx^0+σtϵ 是学生模型输出 x ^ 0 = f θ ( z , y ) \hat{\mathbf{x}}_0=f_\theta(\mathbf{z}, y) x^0=fθ(z,y) 在时间步 t t t 添加噪声后的版本, w ( t ) w(t) w(t) 是损失的加权函数。另一方面,LoRA 教师模型是通过扩散损失 ∥ E t , ϵ , y [ ϵ ψ ( x t , t , y ) − ϵ ] ∥ 2 2 \left\|\mathbb{E}_{t, \epsilon, y}\left[\epsilon_\psi\left(\mathbf{x}_t, t, \mathbf{y}\right)-\epsilon\right]\right\|_2^2 ∥Et,ϵ,y[ϵψ(xt,t,y)−ϵ]∥22 进行训练的。SwiftBrush 在学生模型和 LoRA 教师模型的训练之间交替进行,直到收敛。
4 Proposed Methods
在本节中,我们首先深入分析代表性的基于扩散的文本到图像模型中的质量多样性权衡(第 4.1 节)。
随后,我们讨论结合 SwiftBrush 和 SD Turbo 优势的策略(第 4.2 节)。 最后,我们探索各种方法来增强蒸馏过程和训练后程序(第 4.3 至 4.5 节)。 图 2 概述了我们的方法。
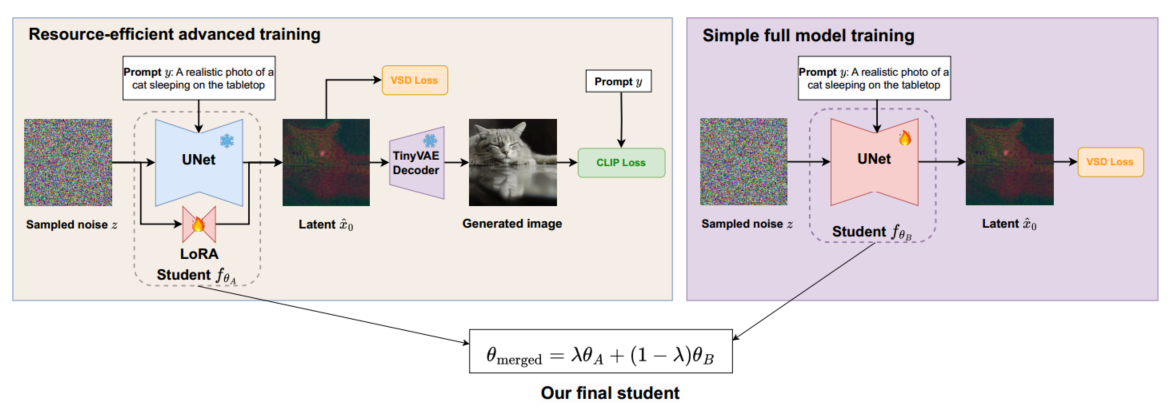
图 2:SwiftBrush v2 概览:两个版本的学生模型:一个使用变分得分蒸馏 (VSD) 损失训练的完全微调模型,以及一个使用 VSD 和 CLIP 损失训练的 LoRA 微调模型。最终模型是通过合并两个学生模型获得的,充分利用了两种训练方案的优势。
4.1 Quality-Diversity Trade-off in Existing Models
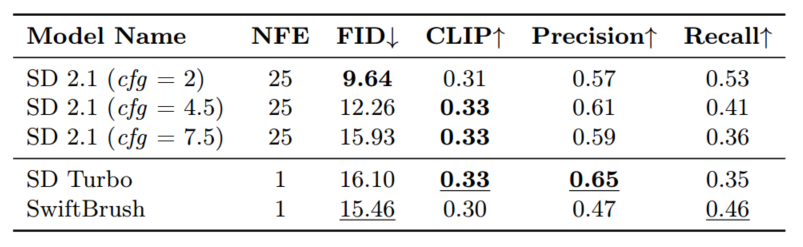
我们首先分析教师模型、SDv2.1 和现有的基于一步扩散的文本到图像模型的属性。对于教师模型,我们评估其在不同指导尺度上的表现。在这里,我们选择 SwiftBrush 和 SD Turbo,因为它们的质量和独特的训练程序。SwiftBrush 在其无图像训练中完全依赖于教师的分数蒸馏,而 SD Turbo 则在具有对抗性和蒸馏损失的真实图像上进行训练。我们对 COCO 2014 基准进行了分析,并在表 1 中报告了相关指标。
在评估多步教师的表现时,无分类器指导量表 (cfg) 起着至关重要的作用。低 cfg(例如,cfg = 2)产生低 FID 分数 9.64,这是由高输出多样性(召回率 = 0.53)驱动的。但是,此设置会导致图像和提示之间的对齐较弱(CLIP 分数 = 0.30)和图像质量较低(精度低)。相反,较大的 cfg(例如,cfg = 7.5)显着改善了文本图像对齐(CLIP 分数 = 0.33),但限制了多样性(召回率 = 0.36),导致 FID 得分较低,为 15.93。中等 cfg 值(例如,cfg = 4.5)达到更好的平衡,提供最高的精度分数。
在评估单步学生时,我们注意到不同的行为。 SD Turbo 得益于对真实图像的对抗性训练,输出结果非常自然,准确率极高,甚至超过了多步教师模型。然而,这导致多样性较差,召回率低至 0.35。相反,SwiftBrush 采用无图像训练方法,允许灵活组合随机噪声潜伏和输入提示。这种宽松的监督使学生模型能够生成更多样化的输出,但质量却因此受到影响(表 1)。我们通过定性评估进一步验证了这一发现,如图 1 所示。当给出相同的输入提示时,SD Turbo 会生成逼真但相似的输出。相比之下,SwiftBrush 产生的结果范围更广,尽管存在严重扭曲的伪影。无论如何,两个一步式模型的 FID 分数都在 15-16 左右,明显高于教师模型的最佳分数。通过观察现有一步扩散模型(如 SD Turbo 和 SwiftBrush)中的质量多样性权衡,我们旨在将两者结合起来,以充分利用两者的优势。
表 1:多步教师模型 (SDv2.1)、SD Turbo 和 SwiftBrush 在零样本 MS COCO-2014 30K 基准上的比较。最佳得分以粗体显示,而单步模型中得分较高的模型则以下划线显示。
4.2 SwiftBrush and SD Turbo Integration
在本节中,我们探讨了有效合并 SwiftBrush 和 SD Turbo 以增强质量多样性权衡的策略。一种直接的方法是统一它们的训练程序,即结合 SD Turbo 的对抗性训练和 SwiftBrush 的变分分数蒸馏。然而,由于计算需求和潜在的失败,这种简单的方法被证明具有挑战性。
虽然 SwiftBrush 的无图像程序更容易实现,但重现 SD Turbo 的训练过程是复杂且资源密集型的。鉴别器的存在使训练变得复杂,需要大量的 VRAM 和数据集。此外,SD Turbo 的严格监督可能会限制 SwiftBrush 的松散指导,从而限制输出多样性。
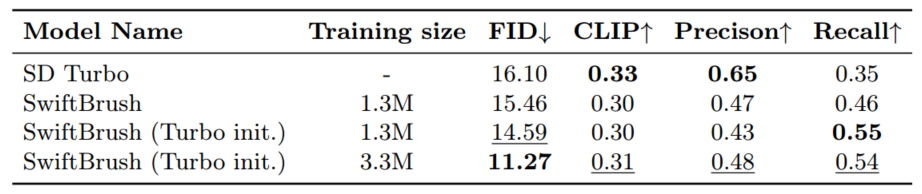
根据我们的讨论,我们选择不使用 SD Turbo 的对抗性训练。相反,我们利用其预训练权重在 SwiftBrush 的训练框架内初始化学生网络。这种简单的方法被证明非常有效。从表2中第二行和第三行的比较中可以看出。生成的模型提高了 FID 和召回率。通过采用 SD Turbo 的预训练权重,我们为训练模型保持高质量输出提供了坚实的基础,而 SwiftBrush 的无图像训练过程则逐步增强了生成多样性。
表 2:SD Turbo 初始化和数据集大小对 SwiftBrush 性能的影响,与零样本 COCO-2014 基准上的 SD Turbo 相比。
4.3 In-training Improvements
除了数据效率和多样性提升之外,SwiftBrush 的无图像训练仍有改进空间。首先,它提供了一种通过收集更多及时输入来扩展训练数据的简单方法。这项任务很简单,因为文本数据集丰富且有大型语言模型可用,而不像通常需要的收集图像-文本对数据那样成本高昂且劳动密集。
其次,通过不强制学生模型的输出与老师的输出相同,SwiftBrush 允许学生甚至超越老师的质量和能力。我们可以通过在 SwiftBrush 训练中添加额外的辅助损失函数来实现这一点。在本节中,我们将讨论这些改进想法的实施。
数据集大小的影响。SwiftBrush 的无图像方法允许不受限制地扩展训练数据集。为了探索数据集对 SwiftBrush 性能的影响,我们进行了补充实验,将来自 LAION 数据集 [47] 的额外 2M 提示添加到来自 JourneyDB 数据集 [36] 的原始 1.5M 重复数据删除提示中。
分析(表 2)显示扩展数据集的性能有所提高。
具体而言,这导致 FID 和精度方面的显著提高,表明数据集大小与生成输出的质量呈正相关。然而,召回率略有下降,表明图像多样性和整体质量之间存在潜在的权衡。此外,尽管与之前的版本相比 CLIP 得分有所提高,但在文本对齐方面仍有改进空间。
解决文本对齐问题。为了改进文本提示与视觉输出之间的一致性,我们在蒸馏过程中集成了额外的 CLIP 损失。然而,直接在学生模型的预测与原始文本提示之间应用这种损失会带来挑战,因为过度优化 CLIP 得分可能会降低图像质量。我们观察到的问题包括模糊、色彩饱和度增加以及生成图像中出现文本伪影。
为了解决这些问题,我们提出在训练过程中使用 ReLU 激活来对 CLIP 值进行截断。这旨在平衡文本对齐与保持图像质量之间的关系,确保模型保持视觉完整性。此外,我们引入动态调度来控制 CLIP 损失的影响,在蒸馏结束前逐渐将其权重减少为零。这种平衡的方法有效地融合了视觉文本对齐和图像保真度。我们的截断 CLIP 损失公式如下:
L CLIP = max ( 0 , τ − ⟨ E image ( D ( f θ ( z , y ) ) ) , E text ( y ) ⟩ ) ( 5 ) \mathcal{L}_{\text{CLIP}} = \max \left(0, \tau - \left\langle \mathcal{E}_{\text{image}}\left(\mathcal{D}\left(f_\theta(\mathbf{z}, \mathbf{y})\right)\right), \mathcal{E}_{\text{text}}(\mathbf{y})\right\rangle \right) \quad(5) LCLIP=max(0,τ−⟨Eimage(D(fθ(z,y))),Etext(y)⟩)(5)
其中, E image \mathcal{E}_{\text{image}} Eimage 和 E text \mathcal{E}_{\text{text}} Etext 分别表示 CLIP 的图像和文本编码器。 D \mathcal{D} D 是用于将潜变量映射回图像的 VAE 解码器。 τ \tau τ 引入了图像和文本嵌入之间期望余弦相似度 ⟨ ⋅ , ⋅ ⟩ \langle\cdot, \cdot\rangle ⟨⋅,⋅⟩ 的阈值,从而防止模型过度强调文本对齐而牺牲图像质量。
4.4 Resource-efficient training schemes
尽管我们的 CLIP 损失非常有用,但它带来了内存和计算成本的问题。特别是 CLIP 图像编码器只能在图像空间上工作,这需要通过图像解码器 D \mathcal{D} D 将预测的潜变量解码为图像,如公式 (5) 所示。我们发现,将 CLIP 损失整合到 SwiftBrush 的全模型蒸馏过程中显著降低了训练速度,尤其是在显存有限的 GPU 上。这促使我们设计了一种资源高效的训练方案,以便在受限环境中充分利用所提出的 CLIP 损失。
在 LoRA 框架 [17] 下进行微调时,仅需训练一组低秩参数,这可以显著减少内存需求。此外,为了计算 CLIP 损失,预测的潜变量需要通过一个大型的 VAE 解码器,这增加了训练时间和内存消耗。为了解决这个问题,我们集成了 TinyVAE [4],这是 Stable Diffusion 的 VAE 的紧凑变体。TinyVAE 在图像的细节上做出了一些妥协,但保留了与原始 VAE 相当的整体结构和物体识别。这种方法在保持接近原始全微调模型的训练效率的同时,如表 6 和第 5.3 节所示,也减少了训练资源的消耗。
4.5 Post-training improvements
最近的文献 [25] 显示出对模型融合技术日益增长的兴趣,这些技术旨在将执行不同子任务的模型整合为一个统一的多任务模型 [ 21 , 53 ] [21,53] [21,53],或将微调后的迭代版本结合起来,创建一个增强版本 [ 10 , 19 , 50 ] [10,19,50] [10,19,50]。我们的研究重点是后者,特别是在一步文本生成图像扩散模型的背景下。这些模型虽然设计用于相同的任务,但在训练目标上有所不同,每个模型都有其独特的优势。通过融合这些模型,我们旨在创建一个新模型,既能捕捉每个模型的优势,又不增加模型大小或推理成本。给定两个一步扩散模型,它们的权重分别为 θ A \theta_A θA 和 θ B \theta_B θB,以及一个插值权重 λ \lambda λ,我们通过对权重进行简单线性插值来融合它们:
θ merged = λ θ A + ( 1 − λ ) θ B \theta_{\text{merged}} = \lambda \theta_A + (1-\lambda) \theta_B θmerged=λθA+(1−λ)θB
我们通过 SD Turbo 和原始 SwiftBrush 的实验实证了这种插值方案的优势。SD Turbo 以其精确度和强大的文本对齐能力而著称,而 SwiftBrush 在多样性方面表现优异。在我们的实证分析中(参见图 3),我们观察到通过从一个模型插值到另一个模型,所有评估的指标(除了 CLIP 得分外)在某个最佳点都有所改善。这表明,融合模型可能会超越原始模型。这些发现强调了模型融合技术在提升模型效能方面的潜力,正如指标分析所显示的那样。
如第 4.4 节所讨论,我们提出了两种训练方案。我们可以使用 LoRA 和 TinyVAE 结合 VSD 和 CLIP 损失来训练学生模型,或者只使用 VSD 损失对学生模型进行全微调。这两种训练方案产生了两种具有不同行为的一步模型,使其成为理想的融合成分。通过融合这些模型,我们获得了我们提出的 SwiftBrush v2 框架的最终模型输出。
总结:v2有效的点:
- 引入SD Turbo初始化,做权重正则(SD Turbo训练依赖大量图文对)(涨一个点左右)
- 扩大文本数据规模,扩大了大约三倍(涨三个点左右)
- 引入CLIP损失,权衡图文对齐和生成图像的质量(涨一个点左右)
- 模型权重的ensemble,多模型融合性能涨点显著(涨大约三个点左右)







![[SimCLR v2] Big Self-Supervised Models are Strong Semi-Supervised Learners](https://i-blog.csdnimg.cn/direct/4cc9701420354cecb5eba7197a705453.png)


![HLS报错之:Export RTL报错 “ERROR: [IMPL 213-28] Failed to generate IP.“](https://i-blog.csdnimg.cn/direct/bb2ba2deb94f415081196fa462de6837.png)