零、文章目录
Python进阶05-多线程
1、进程
(1)单任务
- 单任务:指在同一时间内只执行单个任务。
import time
# 定义一个函数,用于实现听音乐
def music():
for i in range(3):
print('正在听音乐...')
time.sleep(0.2)
# 定义一个函数,用于实现写代码
def coding():
for i in range(3):
print('正在写代码...')
time.sleep(0.2)
# 定义一个程序执行的入口
if __name__ == '__main__':
music()
coding()
(2)多任务
- 多任务:指在同一时间内执行多个任务。
- 例如: 现在电脑安装的操作系统都是多任务操作系统,可以同时运行着多个软件。
-
多任务的两种表现形式
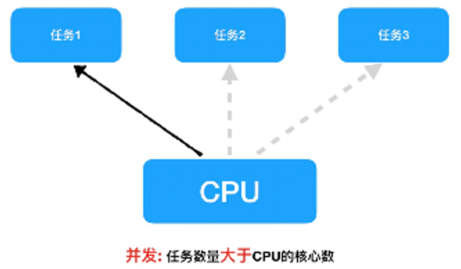
- 并发:在一段时间内交替去执行多个任务。
- 并行:在一段时间内真正的同时一起执行多个任务。
-
并发案例
- 对于单核cpu处理多任务,操作系统轮流让各个任务交替执行,假如:软件1执行0.01秒,切换到软件2,软件2执行0.01秒,再切换到软件3,执行0.01秒……这样反复执行下去 , 实际上每个软件都是交替执行的 . 但是,由于CPU的执行速度实在是太快了,表面上我们感觉就像这些软件都在同时执行一样 . 这里需要注意单核cpu是并发的执行多任务的。
-
并行案例
-
对于多核cpu处理多任务,操作系统会给cpu的每个内核安排一个执行的任务,多个内核是真正的一起同时执行多个任务。这里需要注意多核cpu是并行的执行多任务,始终有多个任务一起执行。
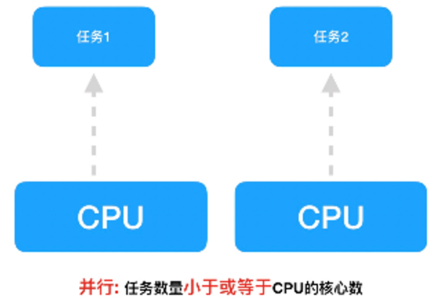
-
(3)进程
- 进程(Process)是资源分配的最小单位,它是操作系统进行资源分配和调度运行的基本单位。一个程序运行后至少有一个进程。
- 通俗理解:一个正在运行的程序就是一个进程 . 例如:正在运行的qq , 微信等 他们都是一个进程。
(4)多进程完成多任务
- 多进程是Python程序中实现多任务的一种方式,使用多进程可以大大提高程序的执行效率 。
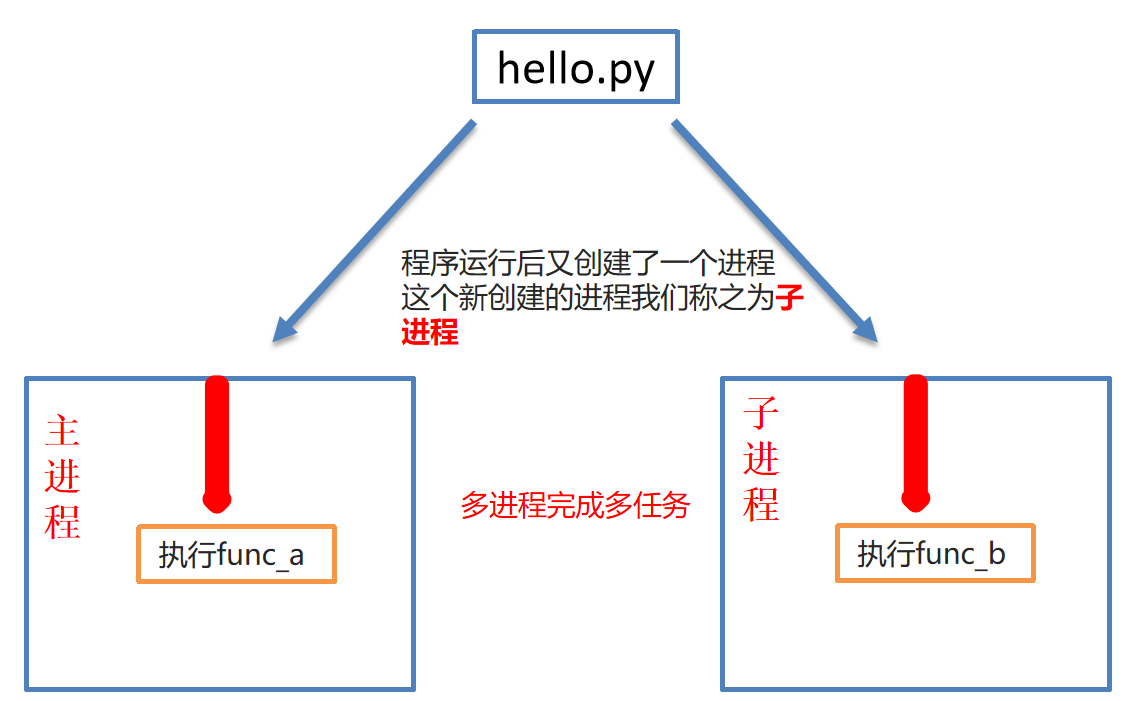
(5)进程创建
-
进程的创建步骤
- 导入进程包:import multiprocessing
- 通过进程类创建进程对象:进程对象 = multiprocessing.Process()
- 启动进程执行任务:进程对象.start()
-
通过进程类创建进程对象参数说明:进程对象 = multiprocessing.Process(target=任务名)
-
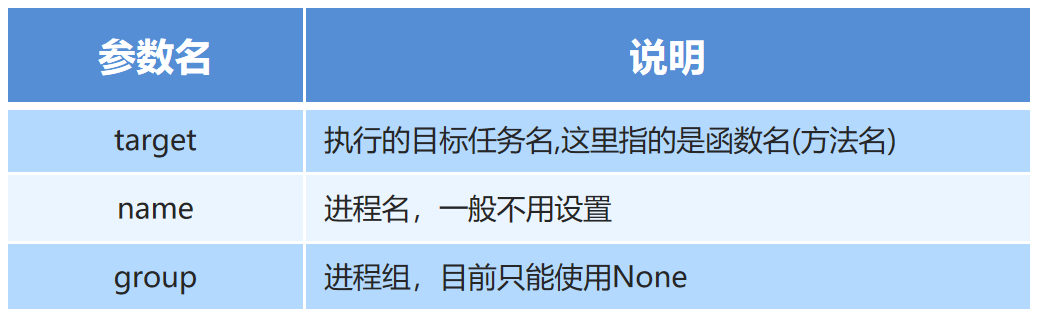
-
import time # 第一步:导入多进程包 import multiprocessing # 定义一个music()函数,用于实现听音乐功能 def music(): for i in range(3): print('正在听音乐...') time.sleep(0.2) # 定义一个coding()函数,用于实现写代码功能 def coding(): for i in range(3): print('正在写代码...') time.sleep(0.2) # 定义一个程序的执行入口 if __name__ == '__main__': # ... 主进程 # 第二步:在主进程中创建两个子进程 music_process = multiprocessing.Process(target=music) coding_process = multiprocessing.Process(target=coding) # 第三步:启动刚才创建的子进程 music_process.start() coding_process.start()
-
-
进程执行带有参数的任务
-

-
args参数的使用
-
# target: 进程执行的函数名 # args: 表示以元组的方式给函数传参 sing_process = multiprocessing.Process(target=music, args=(3,)) sing_process.start()
-
-
kwargs参数的使用
-
# target: 进程执行的函数名 # kwargs: 表示以字典的方式给函数传参 dance_process = multiprocessing.Process (target=coding, kwargs={“t": 0.2}) # 启动进程 dance_process.start()
-
-
注意点:
- 元组方式传参 :元组方式传参一定要和参数的顺序保持一致。
- 字典方式传参:字典方式传参字典中的key一定要和参数名保持一致。
-
import time # 第一步:导入多任务包 import multiprocessing # 定义一个music()函数,用于实现听音乐功能 # 参数n代表循环次数 def music(n): for i in range(n): print('正在听音乐...') time.sleep(0.2) # 定义一个coding()函数,用于实现写代码功能 # 参数t代表休眠时间 def coding(t): for i in range(3): print('正在写代码...') time.sleep(t) # 定义一个程序的执行入口 if __name__ == '__main__': # 第二步:创建子进程对象 music_process = multiprocessing.Process(target=music, args=(3,)) coding_process = multiprocessing.Process(target=coding, kwargs={'t':0.2}) # 第三步:启动子进程 music_process.start() coding_process.start()
-
(6)获取进程编号
-
进程编号的作用:当程序中进程的数量越来越多时 , 如果没有办法区分进程就无法进行有效的进程管理 , 为了方便管理使用进程编号。
-
获取进程编号的两种方式 :
-
os.getpid():获取进程编号
-
import os pid = os.getpid() print(pid) # 或者 import multiprocessing pid = multiprocessing.current_process().pid print(pid)
-
-
os.getppid():获取父进程编号
-
def work(): # 查看当前进程 current_process = multiprocessing.current_process() # 获取当前进程的编号 print(“work进程编号:”, current_process.pid, os.getpid()) # 获取父进程的编号 print(“work父进程的编号:”, os.getppid())
-
-
-
os.kill():杀死进程
-
''' import os os.kill(进程PID编号, 传递的信号) 信号: 9 : 强制杀掉PID进程 15 :通知PID进程,正常结束 ''' import os os.kill(12752, 9)
-
(7)多进程之间不共享全局变量

- 单任务中进程之间是可以共享变量的
'''
在单任务中,多个函数之间是可以共享全局变量的。
'''
import time
my_list = []
def write_data():
for i in range(3):
my_list.append(i)
print('add:', i)
print(my_list)
def read_data():
print(my_list)
if __name__ == '__main__':
write_data()# [0, 1, 2]
time.sleep(1)
read_data()# [0, 1, 2]
- 多进程之间不共享全局变量
'''
在单任务中,多个函数之间是可以共享全局变量的。
在多进程多任务中,多个进程之间无法共享全局变量。
'''
import time
import multiprocessing
my_list = []
def write_data():
for i in range(3):
my_list.append(i)
print('add:', i)
print(my_list)
def read_data():
print(my_list)
if __name__ == '__main__':
# 创建子进程
write_process = multiprocessing.Process(target=write_data)
read_process = multiprocessing.Process(target=read_data)
# 启动子进程
write_process.start()#[0, 1, 2]
time.sleep(1)
read_process.start()#[]
(8)主进程和子进程的结束顺序
-
默认情况:主进程会等待所有的子进程执行结束再结束
-
import time import multiprocessing # 定义一个work任务 def work(): for i in range(10): print('working...') time.sleep(0.2) # 定义一个入口程序 if __name__ == '__main__': # 创建一个子进程(大约需要2s执行完毕) sub_process = multiprocessing.Process(target=work) sub_process.start() # 休眠1s time.sleep(1) print('主进程代码已经执行结束!') # 主进程代码执行结束后,整个程序并不会立即结束,而是等待子进程执行结束,当子进程执行结束后,整个主进程才能真正结束! # 结论:主进程默认会等待子进程的结束而结束
-
-
设置守护进程:主进程退出后直接销毁子进程,不再等待执行子进程
-
import time import multiprocessing # 定义一个work任务 def work(): for i in range(10): print('working...') time.sleep(0.2) # 定义一个入口程序 if __name__ == '__main__': # 创建一个子进程(大约需要2s执行完毕) sub_process = multiprocessing.Process(target=work) # 第一种解决方案:守护进程 sub_process.daemon = True sub_process.start() # 休眠1s time.sleep(1) print('主进程代码已经执行结束!')
-
-
手工销毁子进程:主进程退出后不再等待执行子进程
-
import time import multiprocessing # 定义一个work任务 def work(): for i in range(10): print('working...') time.sleep(0.2) # 定义一个入口程序 if __name__ == '__main__': # 创建一个子进程(大约需要2s执行完毕) sub_process = multiprocessing.Process(target=work) sub_process.start() # 休眠1s time.sleep(1) # 在主程序结束之前,强制销毁子进程 sub_process.terminate() print('主进程代码已经执行结束!')
-
2、线程
(1)线程
- 线程:程序执行的最小单位 , 实际上进程只负责分配资源 , 而利用这些资源执行程序的是线程 , 也就说进程是线程的容器 , 一个进程中最少有一个线程来负责执行程序。
- 线程自己不拥有系统资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。这就像通过一个QQ软件(一个进程)打开两个窗口(两个线程)跟两个人聊天一样 , 实现多任务的同时也节省了资源。
(2)多线程完成多任务
- 多线程是Python程序中实现多任务的另一种方式。
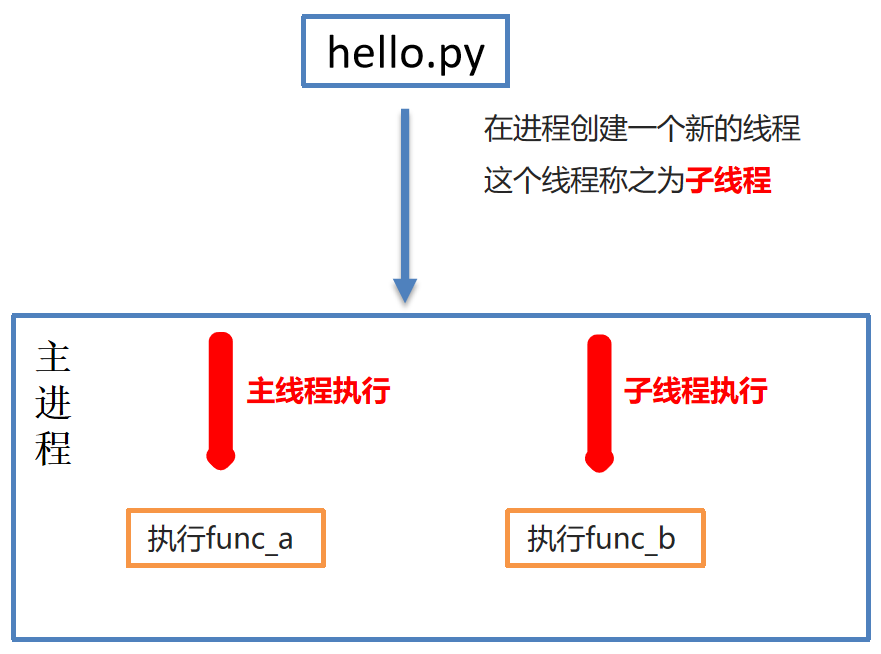
(3)线程创建
-
线程的创建步骤
- 导入线程模块:import threading
- 通过线程类创建线程对象:线程对象 = threading.Thread(target=任务名)
- 启动线程执行任务:线程对象.start()
-
通过线程类创建线程对象
-
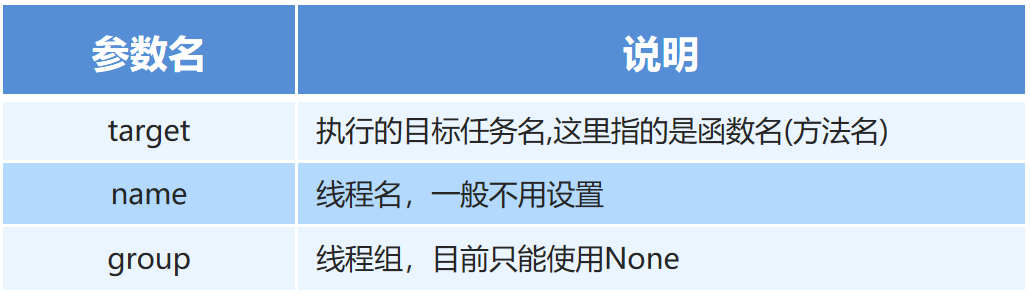
-
''' 在Python代码中,一个Python文件可以创建一个进程 => 创建多线程 线程包含在进程内部,一个进程理论上最少有一个线程 ① 进程资源分配最小单元 => 申请资源 ② 线程专门用于执行程序(干活的) ''' import time # 第一步:导入多线程模块 import threading def music(): for i in range(3): print('正在听音乐...') time.sleep(0.2) def coding(): for i in range(3): print('正在写代码...') time.sleep(0.2) if __name__ == '__main__': # 第二步:创建多线程对象 music_thread = threading.Thread(target=music) coding_thread = threading.Thread(target=coding) # 第三步:启动多线程 music_thread.start() coding_thread.start()
-
-
线程执行带有参数的任务
-

-
args参数的使用
-
# target: 线程执行的函数名 # args: 表示以元组的方式给函数传参 coding_thread = threading.Thread(target=coding, args=(3,)) coding_thread.start()
-
-
kwargs参数的使用
-
# target: 线程执行的函数名 # kwargs: 表示以字典的方式给函数传参 music_thread = threading.Thread(target=music, kwargs={”count": 3}) # 开启线程 music_thread.start()
-
-
注意点
- 元组方式传参 :元组方式传参一定要和参数的顺序保持一致。
- 字典方式传参:字典方式传参字典中的key一定要和参数名保持一致。
-
''' 在Python代码中,我们可以在多任务中使用args或kwargs进行传参 args:以元组方式传递参数 kwargs:以字典方式传递参数 ''' import time # 第一步:导入多线程模块 import threading # 参数n代表循环次数 def music(n): for i in range(n): print('正在听音乐...') time.sleep(0.2) # 参数t代表休眠时间 def coding(t): for i in range(3): print('正在写代码...') time.sleep(t) if __name__ == '__main__': # 第二步:创建多线程对象 music_thread = threading.Thread(target=music, args=(3,)) coding_thread = threading.Thread(target=coding, kwargs={'t':0.2}) # 第三步:启动多线程 music_thread.start() coding_thread.start()
-
(4)线程间共享全局变量
-
多个线程都是在同一个进程中 , 多个线程使用的资源都是同一个进程中的资源 , 因此多线程间是共享全局变量
-
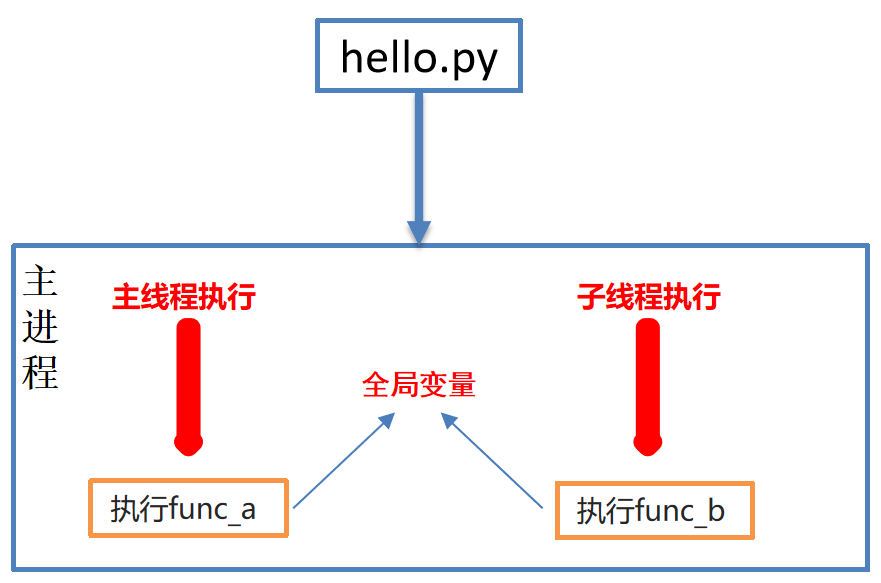
-
''' 多进程实现多任务:无法共享全局变量 多线程实现多任务:因为所有线程都位于同一个进程中,所以不仅资源共享,而且全局变量也是共享的 ''' import time import threading my_list = [] # 定义一个write_data()任务 def write_data(): for i in range(3): my_list.append(i) print('add:', i) print(my_list) # 定义一个read_data()任务 def read_data(): print(my_list) if __name__ == '__main__': # 创建两个子线程 write_thread = threading.Thread(target=write_data) read_thread = threading.Thread(target=read_data) write_thread.start() # [0, 1, 2] time.sleep(1) read_thread.start() # [0, 1, 2]
-
(5)主线程和子线程的结束顺序
-
默认情况:主线程会等待所有的子线程执行结束后主线程再结束
-
import time import threading def work(): for i in range(10): print('working...') time.sleep(0.2) if __name__ == '__main__': # 创建一个子线程 sub_thread = threading.Thread(target=work) # 启动子线程 sub_thread.start() time.sleep(1) print('主线程代码执行结束!')
-
-
设置守护进程:主进程退出后直接销毁子线程,不再等待执行子进程
-
import time import threading def work(): for i in range(10): print('working...') time.sleep(0.2) if __name__ == '__main__': # 创建一个子线程 # 方案一:守护主线程 # sub_thread = threading.Thread(target=work, daemon=True) # 方案二:通过方法设置守护主线程 sub_thread = threading.Thread(target=work) sub_thread.setDaemon(True) # 启动子线程 sub_thread.start() time.sleep(1) print('主线程代码执行结束!')
-
(6)线程间的执行顺序
- 线程之间执行是无序的,是由CPU调度决定某个线程先执行的。
- 同时启动多个线程
'''
要用到的知识点:获取进程的信息
# 通过current_thread方法获取线程对象
current_thread = threading.current_thread()
# 通过current_thread对象可以知道线程的相关信息,例如被创建的顺序
print(current_thread)
'''
import time
import threading
def get_info():
time.sleep(0.2)
current_thread = threading.current_thread()
print(current_thread)
if __name__ == '__main__':
# 创建10个子线程 => 按顺序创建
for i in range(10): # 0 1 2 3 4 5 6 7 8 9
sub_thread = threading.Thread(target=get_info)
sub_thread.start()
- 输出是乱序的
<Thread(Thread-3 (get_info), started 10936)>
<Thread(Thread-2 (get_info), started 4516)>
<Thread(Thread-1 (get_info), started 15400)>
<Thread(Thread-8 (get_info), started 10928)>
<Thread(Thread-7 (get_info), started 7676)>
<Thread(Thread-6 (get_info), started 13376)>
<Thread(Thread-4 (get_info), started 3344)>
<Thread(Thread-5 (get_info), started 4912)>
<Thread(Thread-10 (get_info), started 12508)>
<Thread(Thread-9 (get_info), started 7908)>
3、进程VS线程
(1)关系对比
-
① 线程是依附在进程里面的,没有进程就没有线程。
-
② 一个进程默认提供一条线程,进程可以创建多个线程。
(2)区别对比
-
① 进程之间不共享全局变量
-
② 线程之间共享全局变量
-
③ 创建进程的资源开销要比创建线程的资源开销要大
-
④ 进程是操作系统资源分配的基本单位,线程是CPU调度的基本单位
(3)优缺点对比
-
① 进程优缺点
-
优点:可以用多核,适合CPU密集型应用
-
缺点:资源开销大
-
-
② 线程优缺点
-
优点:资源开销小,适合IO密集型应用(文件、网络)
-
缺点:不能使用多核
-
4、TCP服务器端开发七步走(多任务版本)
'''
TCP服务器端开发七步走 => ① 创建套接字对象 ② 绑定IP和端口 ③ 设置监听 ④ 接收客户端连接请求 ⑤ 接收消息
⑥ 发送消息 ⑦ 关闭套接字对象
'''
import socket
import threading
class WebServer(object):
# 3、定义一个__init__()魔术方法
def __init__(self):
self.tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置端口复用(让服务器端占用的端口在执行结束可以立即释放,不影响后续程序的使用)
self.tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
self.tcp_server_socket.bind(('', 9000)) # 注意:参数必须是一个元组
self.tcp_server_socket.listen(128)
# 5、定义一个handle_request()方法,用于接收消息与发送消息
def handle_request(self, new_socket, ip_port):
# 接收某个客户端发送过来的消息
content = new_socket.recv(1024).decode('gbk') # 1024代表什么意思 => 1024字节 => 1kb = 实际工作中,一条数据大小在1~1.5k之间
print(f'{ip_port}客户端发送消息:{content}')
# 返回数据给客户端
new_socket.send('信息已收到,over!'.encode('gbk'))
# 关闭套接字对象
# new_socket.close()
# 4、定义一个start()方法
def start(self):
while True:
new_socket, ip_port = self.tcp_server_socket.accept()
# 来一个客户,我们就为其创建一个线程,调用自身的handle_request()方法,用于接收消息与发送消息
sub_thread = threading.Thread(target=self.handle_request, args = (new_socket, ip_port))
# 启动线程
sub_thread.start()
# 定义一个程序的执行入口
if __name__ == '__main__':
# 1、实例化对象
ws = WebServer()
# 2、调用对象中的相关方法 => 启动TCP服务
ws.start()