1,本文介绍
MSBlock 是一种分层特征融合策略,用于改进卷积神经网络中的特征融合效果。它通过分层次地融合不同尺度的特征图来提高网络的表达能力和性能。MSBlock 采用多尺度特征融合的方法,确保网络能够有效地捕捉不同层次和尺度的信息,从而增强模型对复杂场景和细节的识别能力。这种策略在各种计算机视觉任务中,如目标检测和图像分割,通常能带来显著的性能提升。
关于MSBlock的详细介绍可以看论文:https://arxiv.org/pdf/2308.05480.pdf
本文将讲解如何将MSBlock融合进yolov8
话不多说,上代码!
2, 将MSBlock融合进yolov8
2.1 步骤一
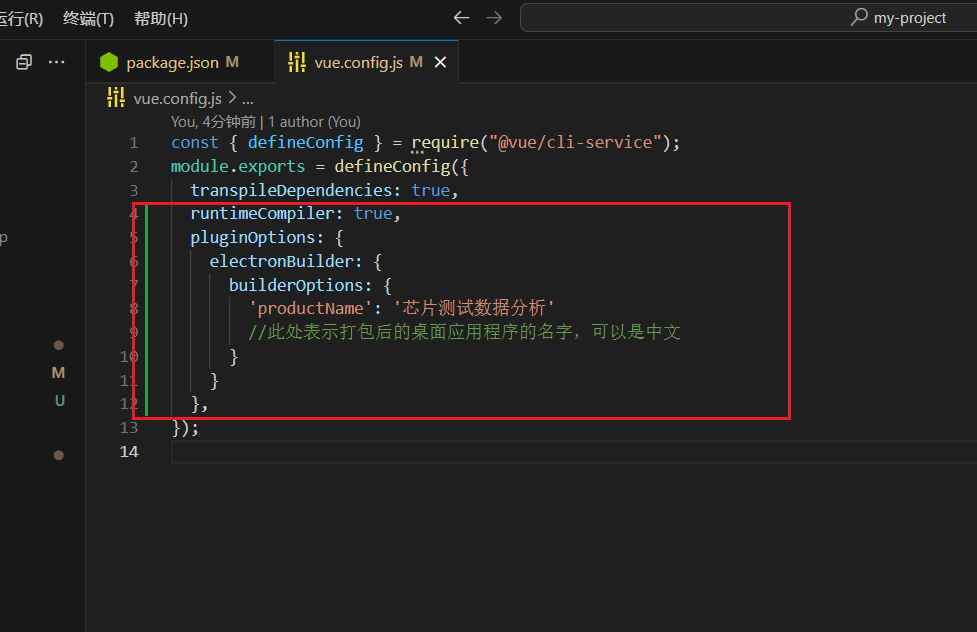
找到如下的目录'ultralytics/nn/modules',然后在这个目录下创建一个MSBlock.py文件,文件名字可以根据你自己的习惯起,然后将MSBlock的核心代码复制进去
######################################## MS-Block start by AI&CV ########################################
import torch
import torch.nn as nn
import torch.nn.functional as F
def autopad(k, p=None, d=1): # kernel, padding, dilation
# Pad to 'same' shape outputs
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
class MSBlockLayer(nn.Module):
def __init__(self, inc, ouc, k) -> None:
super().__init__()
self.in_conv = Conv(inc, ouc, 1)
self.mid_conv = Conv(ouc, ouc, k, g=ouc)
self.out_conv = Conv(ouc, inc, 1)
def forward(self, x):
return self.out_conv(self.mid_conv(self.in_conv(x)))
class MSBlock(nn.Module):
def __init__(self, inc, ouc, kernel_sizes, in_expand_ratio=3., mid_expand_ratio=2., layers_num=3,
in_down_ratio=2.) -> None:
super().__init__()
in_channel = int(inc * in_expand_ratio // in_down_ratio)
self.mid_channel = in_channel // len(kernel_sizes)
groups = int(self.mid_channel * mid_expand_ratio)
self.in_conv = Conv(inc, in_channel)
self.mid_convs = []
for kernel_size in kernel_sizes:
if kernel_size == 1:
self.mid_convs.append(nn.Identity())
continue
mid_convs = [MSBlockLayer(self.mid_channel, groups, k=kernel_size) for _ in range(int(layers_num))]
self.mid_convs.append(nn.Sequential(*mid_convs))
self.mid_convs = nn.ModuleList(self.mid_convs)
self.out_conv = Conv(in_channel, ouc, 1)
self.attention = None
def forward(self, x):
out = self.in_conv(x)
channels = []
for i, mid_conv in enumerate(self.mid_convs):
channel = out[:, i * self.mid_channel:(i + 1) * self.mid_channel, ...]
if i >= 1:
channel = channel + channels[i - 1]
channel = mid_conv(channel)
channels.append(channel)
out = torch.cat(channels, dim=1)
out = self.out_conv(out)
if self.attention is not None:
out = self.attention(out)
return out
class C2f_MSBlock(C2f):
def __init__(self, c1, c2, n=1, kernel_sizes=[1, 3, 3], in_expand_ratio=3., mid_expand_ratio=2., layers_num=3,
in_down_ratio=2., shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
MSBlock(self.c, self.c, kernel_sizes, in_expand_ratio, mid_expand_ratio, layers_num, in_down_ratio) for _ in
range(n))
######################################## MS-Block end by AI&CV########################################2.2 步骤二
在task.py导入我们的模块

2.3 步骤三
在task.py的parse_model方法里面注册我们的模块
注意,共需要在二个位置进行添加


到此注册成功,复制后面的yaml文件直接运行即可
此处我有二种添加方式,大家可以参考,具体关于每个数据集位置不同,效果不同,大家可以自行调试
yaml文件一
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, MSBlock, [1024,[1, 9, 9]]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)yaml文件二
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f_MSBlock, [128, [1, 3, 3]]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f_MSBlock, [256, [1, 5, 5]]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f_MSBlock, [512, [1, 7, 7]]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f_MSBlock, [1024, [1, 9, 9]]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)不知不觉已经看完了哦,动动小手留个点赞收藏吧--_--