论文将多模态可靠反馈网络(
RFNet)结合到一个循环生成图片过程中,可以增加可用的广告图片数量。为了进一步提高生产效率,利用RFNet反馈进行创新的一致条件正则化,对扩散模型进行微调(RFFT),显著增加生成图片的可用率,减少了循环生成中的尝试次数,并提供了高效的生产过程,而不牺牲视觉吸引力。论文还构建了一个可靠反馈100万(RF1M)数据集,包含超过一百万张由人类标注的生成广告图片,帮助训练RFNet准确评估生成图片的可用性,准确地反映人类的反馈。来源:晓飞的算法工程笔记 公众号
论文: Towards Reliable Advertising Image Generation Using Human Feedback

- 论文地址:https://arxiv.org/abs/2408.00418
- 论文代码:https://github.com/ZhenbangDu/Reliable_AD
Introduction
一张引人注目的广告图片对电子商务的成功至关重要,因为它可以提高点击率(CTR)。手工创作需要显著的人力成本,因此自动广告图片生成的需求正在上升。然而,先前的方法往往导致产品与背景视觉上的不匹配。最新的扩散模型提供了一种解决方案,与ControlNet的结合显示出在保持产品细节不变的同时为产品创造和谐背景的潜力。

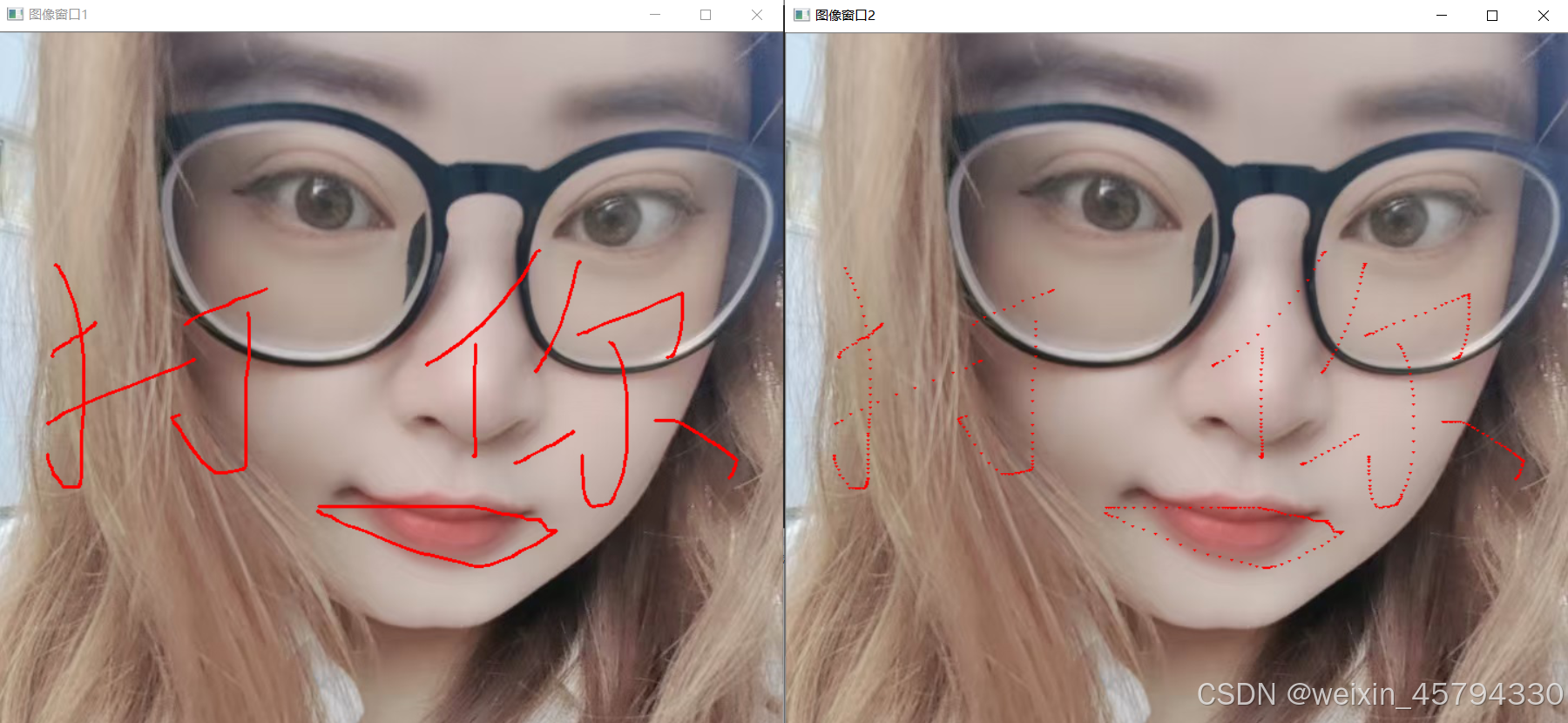
尽管生成模型在创造吸引人的背景方面有潜力,但存在如图1所示的频繁生成低质量广告图片的情况,包括空间和尺寸不匹配、模糊不清和形状错觉等多种情况。这些有缺陷的图片可能导致顾客对产品的误解,降低购物体验质量,因此需要大量人力成本来检查生成的图片,限制了生成模型在广告图片制作中的广泛应用。因此,核心问题在于可用图片的生成率低,即如何建立一个可靠的广告图片生成流水线,能够生产出高可用率的图片。
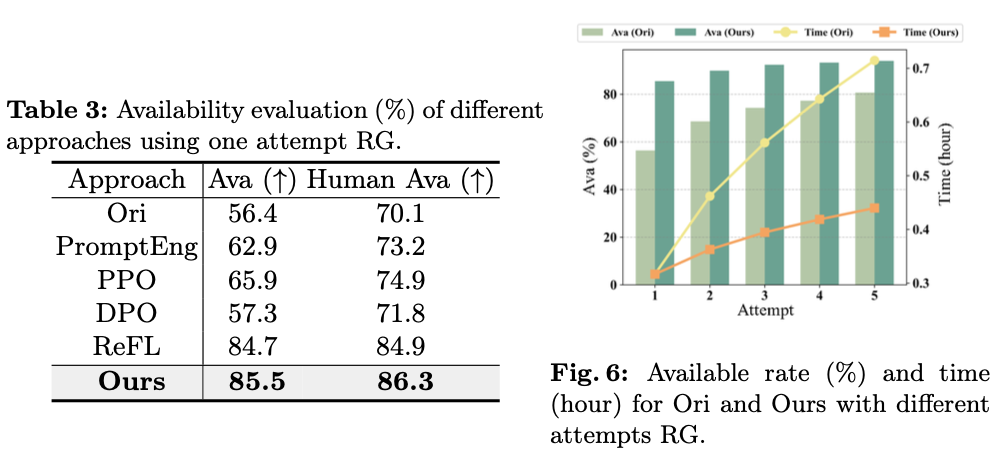
一种自然的解决方案是通过重复生成图像直到获得可用图像(循环生成),因为生成过程中存在随机性。为了替代在这一重复过程中的人工检查,论文引入一种新的可靠反馈网络(RFNet)作为人类检查员,评估生成的广告图片的可用性。由于仅依赖单一生成的图片,模型无法有效地获取关键信息,例如产品是什么以及产品在背景中的表现。因此,RFNet集成了多种辅助模态,提供关键信息来判断不同情况下的可用性。同时,论文构建了一个大规模数据集,称为可靠反馈百万数据集(RF1M),包括超过一百万张精心生成的广告图片,并配有丰富的人类注释,这对于准确训练RFNet以反映人类反馈起到了关键作用。
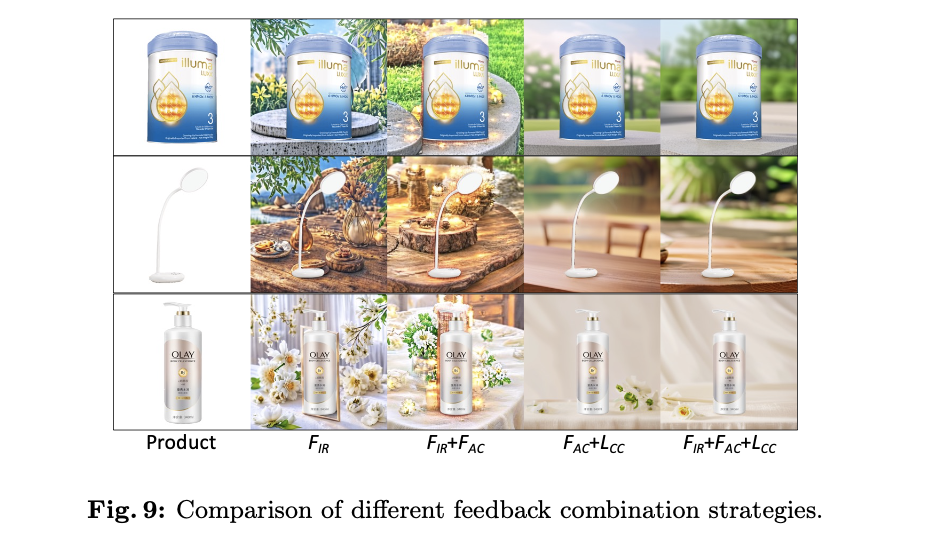
虽然循环生成显著增加了可用图像的数量,但由于生成模型固有的能力不足,多次尝试会显著延长生成过程。利用人类反馈来增强扩散模型的能力提供了一种可行的选择,能够成功提升了生成图像的视觉质量。然而,生成图像的视觉质量和可用性之间存在权衡关系,例如,具有重复和简单背景的产品虽然可用率高,但美观度低。为了解决这个问题,论文提出了一种新的损失项,一致性条件(CC)正则化
L
C
C
L_{CC}
LCC ,以抵消生成背景的统一性和退化,规避传统Kullback-Leibler(KL)正则化的对抗性质。通过利用这一正则化项,由RFNet评估生成图像偏离可用类型的反馈直接反向传播到微调扩散模型(RFFT),显著提升了生成广告图像的可用率,同时不影响其美学品质。这一方法为解决可靠广告图像生成的挑战提供了全面的解决方案。
论文的主要贡献包括:
- 一个广告图像生成解决方案,循环生成以及新型多模态模型
RFNet,模拟人类反馈并有效利用各种模态来帮助区分细粒度的问题类型。 - 一个直观而有效的方法
RFFT,利用人类反馈来精化扩散模型,同时采用创新的一致条件正则化来防止崩溃。 - 一个大规模多模态数据集
RF1M,包含超过一百万张生成的广告图像,并带有丰富的注释。
Dataset
通过精细的人类反馈构建的可靠反馈一百万(RF1M)数据集,作为检查和改进广告图像生成的关键资源。与当前的大规模图像生成数据集Laion-5B、DiffusionDB和Pick-a-Pic相比,RF1M专门为广告领域设计,解决了该领域对广泛数据资源的迫切需求。以下是对其构成、注释及其对社区潜在影响的深入分析。

该数据集使用京东商城广泛的产品收集而成。它包含1,058,230个样本,每个样本由多种组成部分组成,旨在全面理解广告图像生成:
-
生成的广告图像及相应的透明背景产品图像,并由专业设计师精心设计的提示。
-
由在电子商务数据上训练的密集预测变压器和
U2-Net创建的深度和显著性图像,以及产品标题,有助于检查生成的广告图像的可用性。 -
人工标注的标签,指示图像是否可用于广告目的。
这些元素共同为分析生成的广告图像提供了丰富的基础。图2展示了一些示例。
参与标注的人员精通广告,并对广告图像的标准有深入的理解。在数据集中,样本已进一步细分为五个细粒度类别,如图1所示:
- Available:适合用于广告目的的图像。
- Space Mismatch:产品与背景之间空间关系不合适的图像,例如产品的一部分漂浮着。
- Size Mismatch:产品大小与背景之间的差异,例如,按摩椅看起来比一个柜子小。
- Indistinctiveness:由于背景复杂或颜色相似,产品未能突出的图像。
- Shape Hallucination:背景错误地延伸了产品形状,增加了像底座或腿这样的元素。
RF1M凭借其多模态设计和全面功能,是RFNet训练和RFFT的基石,并将进一步显著影响电子商务广告领域及更广泛的领域,具有以下三个亮点:
- Large scale:凭借其广泛的产品类别和图像类型,
RF1M超越了以往的广告数据集BG60k、PPG30k和人类反馈数据集ImageRewardDB、RichHF-18K,同时与Pick-a-Pic数据集规模相当,为RFNet在多样化的广告图像生成任务中准确反映人类反馈提供了坚实的基础。 - Scalability:
RF1M的多模态性质为RFNet提供了充足的信息,使其能够精确地进行判断。除了生成可靠的广告图像外,它还支持高级图像理解和图像抠图等任务。这种灵活性确保了数据集能够满足不断变化的需求,并可以在广告以及其他领域广泛应用。 - Visual appeal:论文精心设计了针对产品特征的提示和生成模型,因此生成的图像具有令人满意的美学效果,能够吸引顾客的注意力。我们在京东进行了为期一周的在线A/B测试,从超过
6000万次曝光中获得了2.2%的点击率增长,凸显了这些图像的高质量,准确捕捉了用户的偏好。
Methodology
Preliminaries
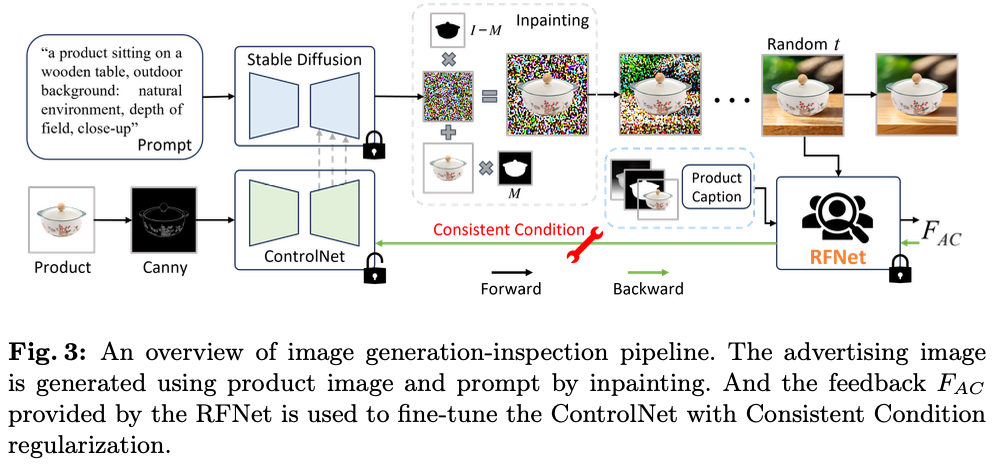
论文生成广告图像的方法如图3所示,从描述所需背景的文本提示和带有透明背景的产品图像 (
I
o
I_o
Io ) 开始。文本提示被输入到Stable Diffusion中,而 (
I
o
I_o
Io ) 在输入ControlNet之前经过cannny边缘检测预处理。采用DDIM作为去噪调度,第 ( t ) 步的潜在表示 ( x ) 计算如下:
KaTeX parse error: Undefined control sequence: \label at position 223: …}, t+1\right), \̲l̲a̲b̲e̲l̲{eq1} \end{alig…
其中, ϵ θ \epsilon_{\theta} ϵθ 表示预测添加噪声的模型, { α ˉ } \{\bar{\alpha}\} {αˉ} 是控制前向添加噪声过程的系数集合。为了保持产品的完整性并确保背景的连贯性,采用修补技术,将潜在表示 x t x_{t} xt 经过以下处理:
KaTeX parse error: Undefined control sequence: \label at position 69: …\otimes x_{o}, \̲l̲a̲b̲e̲l̲{eq2} \end{alig…
其中, x o x_{o} xo 是 I o I_o Io 的潜在表示, M M M 是产品的掩模, ⊗ \otimes ⊗ 表示逐元素乘法。在获得 x 0 x_0 x0 后,该潜在表示被转换为生成的图像 I g I_g Ig 。
Recurrent Generation with RFNet
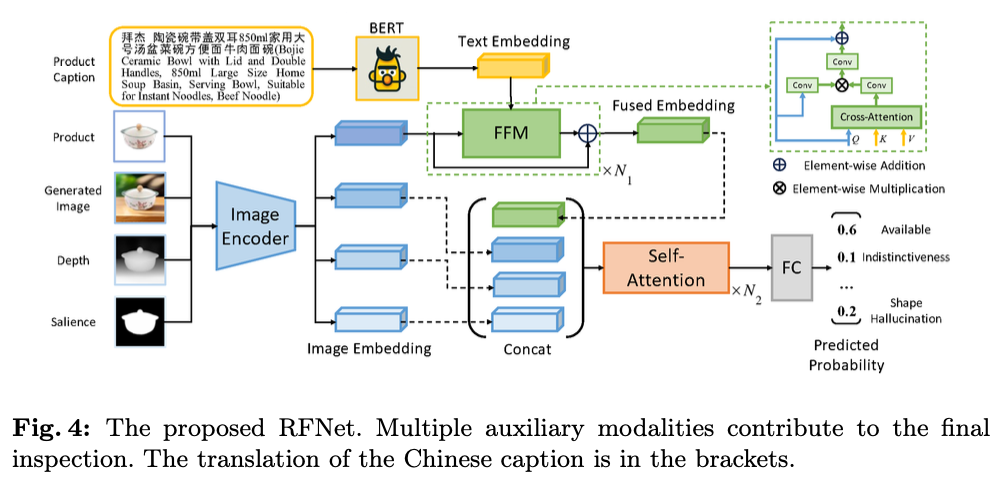
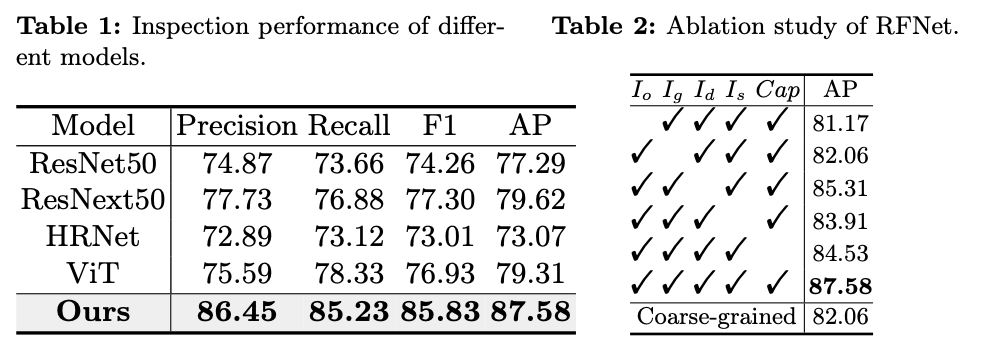
由于固有的随机性,重复生成可以显著扩展可用图像的数量。为了自动化检查过程并消除人类参与,引入了一个多模型RFNet用于精确确定生成的图像是否可用,如图4所示。除了
I
o
I_o
Io 和
I
g
I_g
Ig ,RFNet还结合了来自辅助模态的信息:
-
由深度估计模型生成的 I g I_g Ig 的深度图像 I d I_d Id ,突出显示了产品相对于背景的位置;
-
由显著性检测模型生成的 I g I_g Ig 的显著性图像 I s I_s Is ,勾画出产品的轮廓;
-
产品标题 C a p Cap Cap ,提供有关产品属性的见解。
I
o
I_o
Io ,
I
g
I_g
Ig ,
I
d
I_d
Id 和
I
s
I_s
Is 被送入图像编码器以获取各自的图像嵌入
{
e
o
,
e
g
,
e
d
,
e
s
}
\{\mathbf{e_o}, \mathbf{e_g}, \mathbf{e_d}, \mathbf{e_s}\}
{eo,eg,ed,es} 。同时,
C
a
p
Cap
Cap 被输入到BERT中,以获取文本嵌入
e
c
\mathbf{e_c}
ec ,有助于识别产品的属性。
由于产品标题通常包含大量信息,例如品牌,从标题中可以提炼与视觉相关的属性。因此,首先采用了
N
1
N_1
N1 个特征过滤模块(FFM),每个模块包括一个交叉注意力层和若干卷积层。FFM的输出被表述为:
e f = Conv ( Conv ( CrossAttention ( e o , e c ) ) ⊗ Conv ( e o ) ) + e o , \begin{align} \mathbf{e_f} = \text{Conv}\left(\text{Conv}(\text{CrossAttention}(\mathbf{e_o}, \mathbf{e_c})) \otimes \text{Conv}(\mathbf{e_o})\right)+ \mathbf{e_o}, \end{align} ef=Conv(Conv(CrossAttention(eo,ec))⊗Conv(eo))+eo,
其中, e o \mathbf{e_o} eo 充当交叉注意力层中的 Q u e r y Query Query ,而 e c \mathbf{e_c} ec 同时作为 K e y Key Key 和 V a l u e Value Value 。 Conv() \text{Conv()} Conv() 表示具有 1 × 1 1\times1 1×1 核的卷积层, ⊗ \otimes ⊗ 表示逐元素乘法。该过程确保从标题中提取的关键信息有效地与图像嵌入集成,增强了模型对产品的理解能力。
通过融合嵌入 e f \mathbf{e_f} ef ,不同的特征进一步通过 N 2 N_2 N2 个自注意力层整合,
f = SelfAttention ( Concat ( e f , e g , e d , e s ) ) , \begin{align} \mathbf{f} = \text{SelfAttention}(\text{Concat}(\mathbf{e_f}, \mathbf{e_g}, \mathbf{e_d}, \mathbf{e_s})), \end{align} f=SelfAttention(Concat(ef,eg,ed,es)),
其中, Concat() \text{Concat()} Concat() 表示拼接操作。这些堆叠层捕获了嵌入中的关键特征。最后,一个全连接分类器确定了生成图像每个案例的概率。
在大规模RF1M数据集上训练的RFNet,通过考虑全面的视觉和文本特征,并提供细致的反馈,准确评估生成的广告图片的可用性。这种能力与递归生成策略相结合,显著增加了可用于广告的生成图像数量,实现了自动化生成。
RFFT with Consistent Condition regularization
尽管递归生成能够总体上生成更多可用的图像,但生成模型本身的能力较差导致生产过程冗长且低效,给应用带来了巨大挑战。论文的端到端生成-检测流水线允许来自RFNet的反馈梯度直接对扩散模型进行微调,增强其能力。具体而言,论文提出的RFFT在40-step去噪过程中选择最后10-step中的随机step
t
t
t 来生成
x
^
0
t
=
x
t
+
1
−
1
−
α
ˉ
t
+
1
ϵ
θ
(
x
t
+
1
,
t
+
1
)
α
ˉ
t
+
1
\hat{x}_0^t=\frac{x_{t+1}-\sqrt{1-\bar{\alpha}_{t+1}} \epsilon_\theta\left(x_{t+1}, {t+1}\right)}{\sqrt{\bar{\alpha}_{t+1}}}
x^0t=αˉt+1xt+1−1−αˉt+1ϵθ(xt+1,t+1) 。生成的
x
^
0
t
\hat{x}_0^t
x^0t 经过后处理成
I
^
g
t
\hat{I}_g^t
I^gt ,然后通过RFNet进行检查以确定其可用性,其反馈计算如下:
F A C = − 1 N ∑ i = 1 N y d log ( o ^ i ) , \begin{align} F_{AC} = -\frac{1}{N}\sum_{i=1}^{N} \mathbf{y}_d\text{log}(\mathbf{\hat{o}_i}), \end{align} FAC=−N1i=1∑Nydlog(o^i),
其中,
y
d
\mathbf{y}_d
yd 是表示所需的“可用”类别的one-hot向量,向量
o
^
i
\mathbf{\hat{o}_i}
o^i 包含每个生成图像案例的概率,
N
N
N 是样本总数。然后,梯度
∇
F
A
C
\nabla F_{AC}
∇FAC 被反向传播,以引导模型生成更高概率可用的图像。

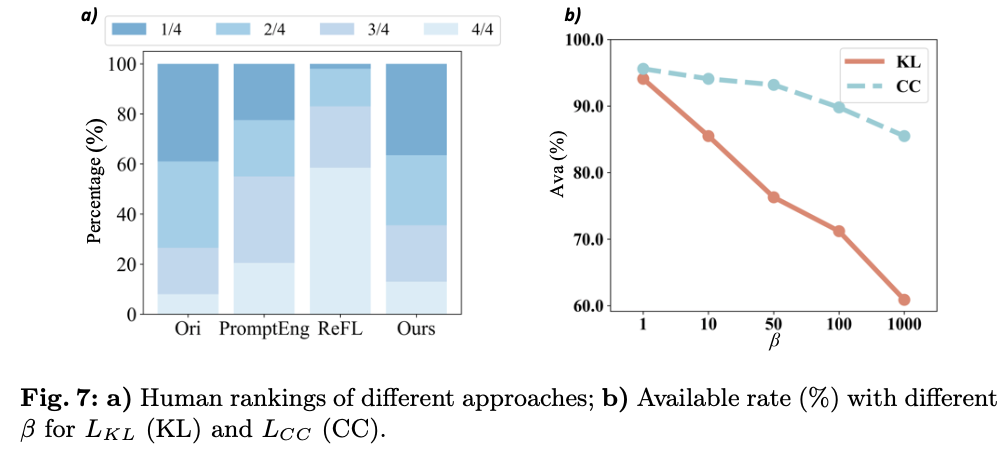
然而,训练模型可靠性的目标与模型生成的图像美学相矛盾,例如,重复且简单的背景可以完全避开前面提到的不良情况。因此,如图5.a所示,随着训练的进行,模型实现了极高的可用率,但产生了同质化且美学上崩溃的输出。因此,需要一种训练方法来提高图像可用性的同时保持其美学稳定性。一种常见的解决方案涉及Kullback-Leibler(KL)正则化,这是一个损失项,确保修改后的模型不会显著偏离期望的分布,从而保持多样性,防止收敛到次优且重复的结果。该损失项可以表述为:
L K L = KL ( p θ ( x ^ 0 t ∣ x t , z , c ) ∥ ( p r e f ( x ^ 0 t ∣ x t , z , c ) ) , \begin{align} L_{KL} = \text{KL}(p_{\theta}(\hat{x}_0^t|x_t,z,c)\Vert(p_{ref}(\hat{x}_0^t|x_t,z,c)), \end{align} LKL=KL(pθ(x^0t∣xt,z,c)∥(pref(x^0t∣xt,z,c)),
其中,
c
c
c 和
z
z
z 是图像和文本的控制条件,
p
θ
p_{\theta}
pθ 和
p
r
e
f
p_{ref}
pref 分别表示当前模型和参考模型的分布。然而,反馈梯度努力将图像生成引向更高的可用率,而KL正则化则致力于保持生成的图像不变。这种对立反映了对抗训练的原则,并且对于实现双赢解决方案提出了挑战。
为此,论文打算不再专注于保持图像不变,而是致力于保持视觉质量。对于文本到图像的生成,视觉输出与输入文本条件 z z z 密切相关,以无需分类器的方式,通过从模型的隐式分类器中提取文本指导信息:
∇ x t log p θ t ( z ∣ x t , c ) ≈ − 1 1 − α ˉ t ( ϵ θ ( x t , z , c ) − ϵ θ ( x t , c ) ) , \begin{align} \nabla_{x_t}\text{log}p_{\theta}^t(z|x_t, c) \approx - \frac{1}{\sqrt{1-\bar{\alpha}_{t}}}\Big(\epsilon_{\theta}(x_t, z, c) - \epsilon_{\theta}(x_t, c)\Big), \end{align} ∇xtlogpθt(z∣xt,c)≈−1−αˉt1(ϵθ(xt,z,c)−ϵθ(xt,c)),
这表明文本条件影响图像生成的方向。为了确保图像可用性的提高不会损害核心条件,论文引入了一致条件(CC)正则化项
L
C
C
L_{CC}
LCC ,如下所示:
L C C = ∥ ∇ x t log p θ t ( z ∣ x t , c ) − ∇ x t log p r e f t ( z ∣ x t , c ) ∥ 2 . \begin{align} L_{CC} = \Vert \nabla_{x_t}\text{log}p_{\theta}^t(z|x_t, c) - \nabla_{x_t}\text{log}p_{ref}^t(z|x_t, c)\Vert_{2}. \end{align} LCC=∥∇xtlogpθt(z∣xt,c)−∇xtlogpreft(z∣xt,c)∥2.
图5.b展示了
L
C
C
L_{CC}
LCC 相对于
L
K
L
L_{KL}
LKL 的优势。虽然
L
K
L
L_{KL}
LKL 通过限制来自
∇
F
A
C
\nabla F_{AC}
∇FAC 的更新,可能导致刚性,但
L
C
C
L_{CC}
LCC 提供了一种双赢的方法。它保持条件的方向,使模型能够被精调以生成更多可用的图像。因此,用于在RFFT中微调扩散模型的最终反馈是:
F t o t a l = F A C + β L C C , \begin{align} F_{total} = F_{AC}+\beta L_{CC}, \end{align} Ftotal=FAC+βLCC,
Experiments

如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】