该文首发于生信技能树,推文链接:https://mp.weixin.qq.com/s/W23Reg6Hi4XWxpMvfctP8g
明白了基因调控网络的基础知识之后,就可以尝试实际操作一下SCENIC分析。
基因调控网络的基础知识可见推文:https://mp.weixin.qq.com/s/sL_8YFulHsZ42L8G5DyY8w
由于R语言跑SCENIC流程实在是慢,还是决定尝试使用python版的SCENIC进行分析。
这次pySCENIC流程实践中出现了很多报错,花了很大时间和精力去解决。希望这个推文能够帮助到遇到同样问题的你。
同时十分感谢曾老师的鼎力相助!~
如果没有耐心读完报错和解决的过程,可以跳到文末。在文末处提供了完整流程和一些解决报错的小思考。
首先展示一下战友的情况:Macbook Pro, M2芯片,16GB内存,老爷车,但也够用。
分析前数据准备-R studio
1、导入数据
load("sce_epi.Rdata")
table(sce$location)
table(sce$seurat_clusters)
table(sce$celltype)
dim(sce)
# [1] 20930 2899
2、R语言中提取exp矩阵文件
library(Seurat)
library(SCopeLoomR)
# 将sce对象中的数据转置并保存为CSV
counts <- GetAssayData(sce, slot = "counts")
counts <- counts[,sample(1:ncol(counts), 100)]
# [1] 20930 100
## 保存为loom文件
library(loomR)
loom <- create(filename = "data/input_new.loom",
data = counts, overwrite = TRUE)
loom$close()
rm(loom)
后续都会用这个input_new.loom文件数据,如果loom经常出现被锁定的情况就用python语言去转换。
GRN分析报错情况及解决流程
环境配置—终端/linux (不在R studio了哈!!)
先跟着众多公众号的教程进行环境配置, 本次采用python 3.9
conda create -y -n pyscenic_3.9 python=3.9
conda activate pyscenic_3.9
pip install pyscenic
conda install numpy
conda install pandas
GRN分析—终端/linux (不在R studio了哈!!)
step1-基因调控网络的构建
输入:表达矩阵input_new.loom文件,转录因子文件 请注意需要把分析文件和工作路径均调整到同一个文件夹中,当然熟练之后也可以自己设定路径啥的。
# pyscenic grn方式
pyscenic grn \
--num_workers 10 \
--output step1out_grn.tsv \
--method grnboost2 \
input_new.loom \
allTFs_hg38.txt
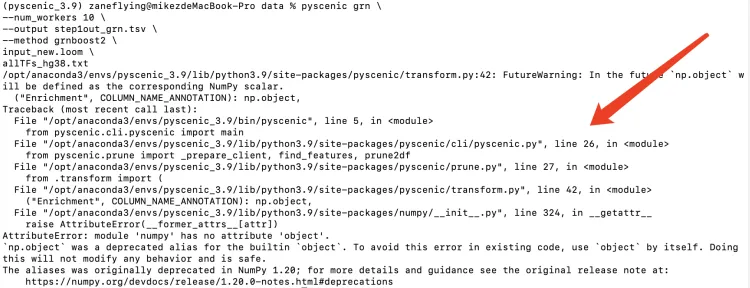
由于对python是真的非常不熟悉,就尝试依靠大模型。


尝试了这三种方法,都失败了! 具体细节就不放出来了,真是"又臭又长"。
接下来找了一个新的环境配置教程,把python提升到3.10并对软件工具进行版本设定
conda create -y -n pyscenic_env python=3.10
conda activate pyscenic_env
pip install pyscenic==0.12.1
conda install numpy==1.23.5
conda install pandas==1.5.3
运行上述的同样代码,依旧报错。
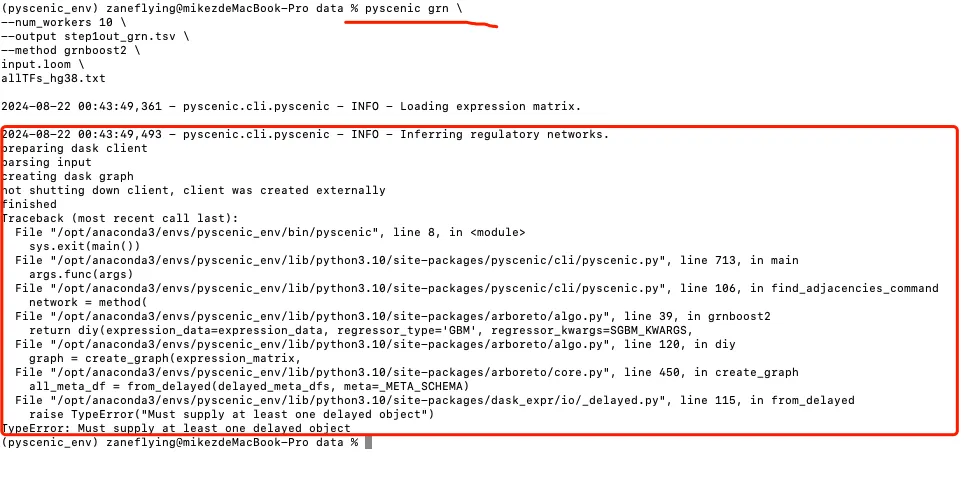
尝试把pyscenic grn改成arboreto_with_multiprocessing.py。
arboreto_with_multiprocessing.py \
--num_workers 10 \
--output step1out_grn.tsv \
--method grnboost2 \
input_new.loom \
allTFs_hg38.txt

可以运行了!
那为什么pyscenic grn改成arboreto_with_multiprocessing.py就可以运行了呢?


好吧,大模型给的解释其实是浅尝辄止。
step2-调控模块的识别
输入:起始位点的文件,motif和TFs映射关系文件和刚开始构建的loom文件
pyscenic ctx \
step1out_grn.tsv \
hg38_500bp_up_100bp_down_full_tx_v10_clust.genes_vs_motifs.rankings.feather \
hg38_10kbp_up_10kbp_down_full_tx_v10_clust.genes_vs_motifs.rankings.feather \
--annotations_fname motifs-v10nr_clust-nr.hgnc-m0.001-o0.0.tbl \
--expression_mtx_fname input.loom \
--mode "dask_multiprocessing" \
--output step2out_ctx.tsv \
--num_workers 10
第二步可以运行,唯一的小问题就是如果电脑不够给力的话,把--mode "dask_multiprocessing" \ 去掉。
step3-AUCell打分 输入: 一开始的loom文件和第二步得到的ctx文件。
pyscenic aucell \
input_new.loom \
step2out_ctx.tsv \
--output out_SCENIC.loom \
--num_workers 10

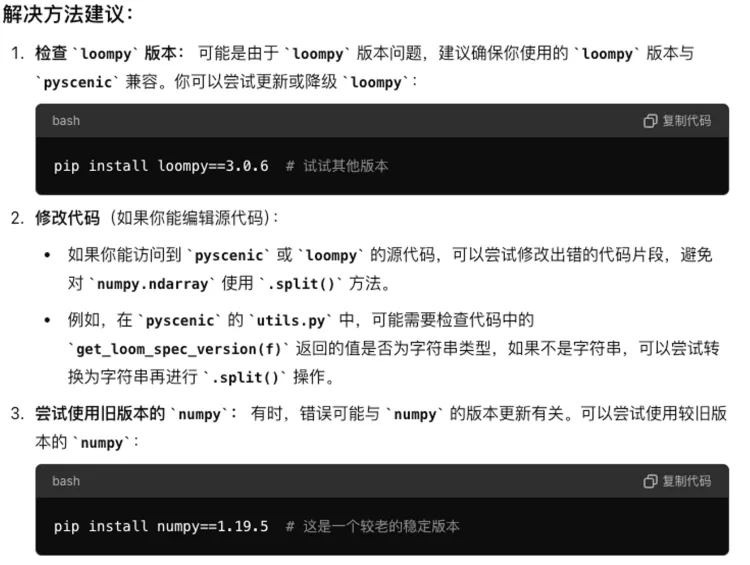
上述的方法都尝试了,然而还是没能成功!同时还尝试了更换python版本环境等,也未能成功。
突然想到最开始在配置环境的时候尝试的配置是python=3.7的环境(基于曾老师最初的推文),但电脑会提醒由于是基于osx-arm64的构架,所以不能配置python=3.7的环境。因此我在猜想会不会跟电脑的硬件构架的关?
查阅了osx-64 和 osx-arm64 相关的知识,发现确实有一些差异!
1. osx-64:
架构: 针对 x86_64 架构,也就是传统的 Intel 和 AMD 处理器架构。这是 Mac 电脑在 Apple Silicon (M1, M2) 之前使用的主流架构。
适用设备: 通常用于基于 Intel 处理器的 Mac 电脑(比如 MacBook、iMac、Mac Pro 等)。
软件兼容性: 针对 x86_64 架构编译的软件包,使用的是 Intel 指令集。
2. osx-arm64:
架构: 针对 ARM64 架构,也就是 Apple Silicon 芯片(如 M1, M2)。这些芯片基于 ARM 架构,与传统的 Intel x86_64 架构不同。
适用设备: 专为 Apple Silicon 处理器的 Mac 设备设计(如 M1/M2 MacBook Air, MacBook Pro, Mac mini, iMac 等)。
软件兼容性: 针对 ARM64 架构编译的软件包,使用的是 ARM 指令集。Apple Silicon 设备通常可以通过 Rosetta 2 运行 osx-64 编译的软件包,但 osx-arm64 的软件包会有更好的性能和优化。
接下来在构建环境的时候尝试使用osx-64的硬件构架。并且重新配置python3.7版本。
CONDA_SUBDIR=osx-64 conda create -n pyscenic_3.7 python=3.7
conda activate pyscenic_3.7
pip install pyscenic
conda install numpy
conda install pandas
pyscenic grn \
--num_workers 10 \
--output step1out_grn.tsv \
--method grnboost2 \
input_new.loom \
allTFs_hg38.txt
成功运行了!
pyscenic ctx \
step1out_grn.tsv \
hg38_500bp_up_100bp_down_full_tx_v10_clust.genes_vs_motifs.rankings.feather \
hg38_10kbp_up_10kbp_down_full_tx_v10_clust.genes_vs_motifs.rankings.feather \
--annotations_fname motifs-v10nr_clust-nr.hgnc-m0.001-o0.0.tbl \
--expression_mtx_fname input_new.loom \
--output step2out_ctx.tsv \
--mode "dask_multiprocessing" \
--num_workers 10 \
--mask_dropouts

pyscenic aucell \
input_new.loom \
step2out_ctx.tsv \
--output out_SCENIC.loom \
--num_workers 10
第三步的时候出现了loompy和pyscenic版本不兼容的问题,因此把loompy降级即可!
pip install loompy==2.0.17
然后重新运行第三步代码
在R studio中稍微试了一下
library(SCopeLoomR)
library(SCENIC)
scenicLoomPath='out_SCENIC.loom'
loom <- open_loom(scenicLoomPath)regulons_incidMat <- get_regulons(loom, column.attr.name="Regulons")regulons <- regulonsToGeneLists(regulons_incidMat)7 regulonAUC <- get_regulons_AUC(loom, column.attr.name="RegulonsAUC")

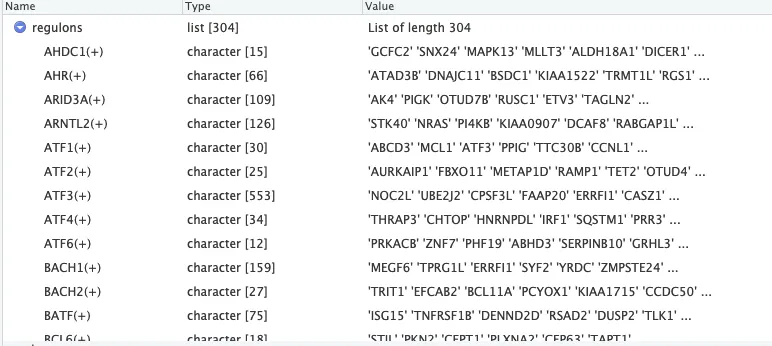
运行成功~
完整流程:
1、数据准备-R studio
load("sce_epi.Rdata")
table(sce$location)
table(sce$seurat_clusters)
table(sce$celltype)
dim(sce)
# [1] 20930 2899
library(Seurat)
library(SCopeLoomR)
# 将sce对象中的数据转置并保存为CSV
counts <- GetAssayData(sce, slot = "counts")
counts <- counts[,sample(1:ncol(counts), 100)]
# [1] 20930 100
## 保存为loom文件
library(loomR)
loom <- create(filename = "data/input_new.loom",
data = counts, overwrite = TRUE)
loom$close()
rm(loom)
2、环境配置及GRN运行-终端/linux
请注意把需要的文件放到同一个文件夹中,或者设置文件路径。
# 环境配置
# 当然如果没有遇到这样问题的,只需要按照常规方法配置环境!!
# conda create -n pyscenic_3.7 python=3.7
CONDA_SUBDIR=osx-64 conda create -n pyscenic_3.7 python=3.7
conda activate pyscenic_3.7
pip install pyscenic
conda install numpy
conda install pandas
# GRN-step1 (两种方式)
pyscenic grn \
--num_workers 10 \
--output step1out_grn.tsv \
--method grnboost2 \
input_new.loom \
allTFs_hg38.txt
# arboreto_with_multiprocessing.py \
# --num_workers 10 \
# --output step1out_grn.tsv \
# --method grnboost2 \
# input_new.loom \
# allTFs_hg38.txt
# step2
pyscenic ctx \
step1out_grn.tsv \
hg38_500bp_up_100bp_down_full_tx_v10_clust.genes_vs_motifs.rankings.feather \
hg38_10kbp_up_10kbp_down_full_tx_v10_clust.genes_vs_motifs.rankings.feather \
--annotations_fname motifs-v10nr_clust-nr.hgnc-m0.001-o0.0.tbl \
--expression_mtx_fname input_new.loom \
--output step2out_ctx.tsv \
--mode "dask_multiprocessing" \
--num_workers 10 \
--mask_dropouts
# step3
pip install loompy==2.0.17
pyscenic aucell \
input_new.loom \
step2out_ctx.tsv \
--output out_SCENIC.loom \
--num_workers 10
得到了out_SCENIC.loom文件之后就可以放到R stduio中进行处理了!
小思考:
1、计算机是极其"理性"的,它不会以人或者物的意志而随意变化。也就是说如果它出现了报错,一定是能够追根溯源的,之前能运行的代码,只要按照相应条件一定也是能够运行的。因此遇到报错不要害怕,追根溯源即可!
2、尽量不要遗漏每一个报错并努力去理解每一个报错,解决之道就在“其”中。
3、熟悉基础知识和善用辅助工具这两者是并重的,大模型有它独到的优势,但始终不是万能,可能更多的时候我们还是需要靠自己去学习一些计算机/计算机语言基础知识,在这个基础之上更好的使用辅助工具。如果笔者自己能够更加熟悉硬件/计算机语言/分析框架等基础知识的话,应该能更快的做出调整吧。
参考资料:
1、生信技能树/生信随笔:
https://mp.weixin.qq.com/s/IqtNTMb4Jet0VF2-CzgrfA https://mp.weixin.qq.com/s/pN4qWdUszuGqr8nOJstn8w https://mp.weixin.qq.com/s/mBR3IwWvQDcTOXNwM_YCEg https://mp.weixin.qq.com/s/eRFUFPvNDfcU2kW6RkuLSw https://mp.weixin.qq.com/s/ncSW8EXrpzqD-3b7uXy5Mg
2、生信菜鸟团:
https://mp.weixin.qq.com/s/2czUaSzDWrkMF-p8FKDKqg
3、Ks科研分享与服务:
https://mp.weixin.qq.com/s/PS-iI3gtLhMpiM_09pk6sQ https://www.bilibili.com/video/BV1Yj411r7dE/?spm_id_from=333.999.0.0&vd_source=05b5479545ba945a8f5d7b2e7160ea34
4、科研小徐:
https://www.jianshu.com/p/f92e5a063e7a
5、arboreto_with_multiprocessing.py
https://github.com/aertslab/pySCENIC/blob/master/src/pyscenic/cli/arboreto_with_multiprocessing.py
致谢:感谢曾老师以及生信技能树团队全体成员。
注:若对内容有疑惑或者有发现明确错误的朋友,请联系后台(欢迎交流)。更多内容可关注公众号:生信方舟
- END -










![图表检测检测系统源码分享 # [一条龙教学YOLOV8标注好的数据集一键训练_70+全套改进创新点发刊_Web前端展示]](https://i-blog.csdnimg.cn/direct/6a5693b8d2104029863455b0d63c7a96.png#pic_center)