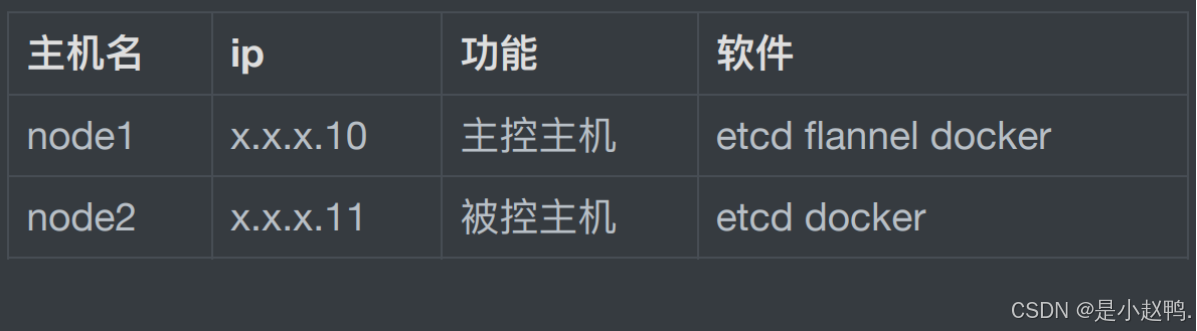
启动服务
import zdppy_api as api
import zdppy_cache
key1 = "admin"
key2 = "admin"
app = api.Api(routes=[
*zdppy_cache.zdppy_api.cache(key1, key2, api)
])
if __name__ == '__main__':
import zdppy_uvicorn
zdppy_uvicorn.run(app, host="0.0.0.0", port=8888)
基于用户的缓存隔离
测试代码:
import req
# 用户1设置缓存
headers = {
"key1": "zhangdapeng",
"key2": "zhangdapeng520",
}
resp = req.post("http://127.0.0.1:8888/zdppy_cache", json={
"key": "name",
"value": "张三"
}, headers=headers)
print(resp.json())
resp = req.get("http://127.0.0.1:8888/zdppy_caches", json={}, headers=headers)
print(resp.json())
resp = req.get("http://127.0.0.1:8888/zdppy_cache", json={"key": "name"}, headers=headers)
print(resp.json())
# 用户2设置缓存
headers2 = {
"key1": "zhangdapeng1",
"key2": "zhangdapeng521",
}
resp = req.post("http://127.0.0.1:8888/zdppy_cache", json={
"key": "name",
"value": "张三333"
}, headers=headers2)
print(resp.json())
resp = req.get("http://127.0.0.1:8888/zdppy_cache", json={"key": "name"}, headers=headers2)
print(resp.json())
resp = req.get("http://127.0.0.1:8888/zdppy_cache", json={"key": "name"}, headers=headers)
print("用户1相同的key", resp.json())
不同的用户,相同的key,得到的是不同的值。

超级管理员可以管理普通用户的缓存
测试代码:
import req
# 用户1设置缓存
headers = {
"key1": "zhangdapeng",
"key2": "zhangdapeng520",
}
resp = req.post("http://127.0.0.1:8888/zdppy_cache", json={
"key": "name",
"value": "张三"
}, headers=headers)
print(resp.json())
resp = req.get("http://127.0.0.1:8888/zdppy_cache", json={"key": "name"}, headers=headers)
print(resp.json())
# 通过管理员获取用户缓存
headers2 = {
"key1": "admin",
"key2": "admin",
"username": "zhangdapeng", # 指定要操作的用户
}
resp = req.get("http://127.0.0.1:8888/zdppy_cache/manage", json={
"key": "name",
}, headers=headers2)
print(resp.json())
# 通过管理员删除用户缓存
resp = req.delete("http://127.0.0.1:8888/zdppy_cache/manage", json={
"key": "name",
}, headers=headers2)
print(resp.json())
# 用户自己查询缓存
resp = req.get("http://127.0.0.1:8888/zdppy_cache", json={"key": "name"}, headers=headers)
print(resp.json())
输出结果: