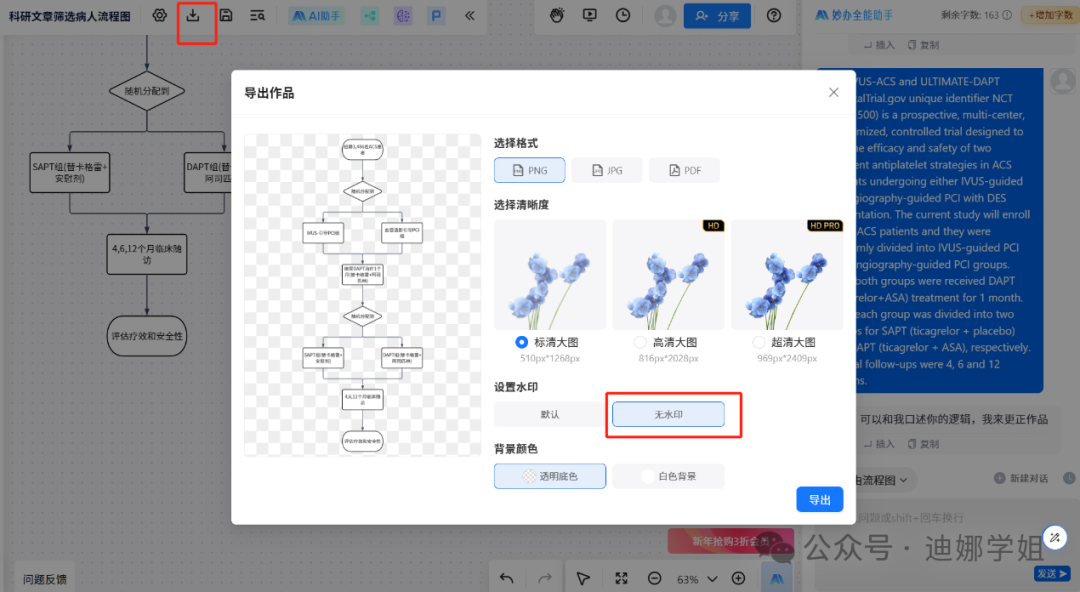
前情回顾
在第(1)节中,我们对于backtrader内置的评价指标一个接一个的进行了实践测试,其中第10个是金融投资组合分析库 - pyfolio,当时我们先去实践了Analyzer中的pyfolio指标(其实就是03,07,08,09四个评价指标的合集),也说到后续再去研究pyfolio库和quantstats库的使用。
这一节,我们就来做这件事情。
A_pyfolio实践
01_backtrader官方文档学习
- Analyzers - PyFolio - Backtrader
- Analyzers - PyFolio - Integration - Backtrader
上面2个页面就是backtrader关于Analyzers-PyFolio的官方文档说明,这里面最有意思的几句话我们用AI把它翻译过来
截至2017年7月25日,pyfolio的API已经发生了变化,
create_full_tear_sheet函数不再接受名为gross_lev的参数。因此,如果原来的代码中使用了
gross_lev参数,它将无法正常工作,因为该参数不再存在。由于上述变化,集成示例中的代码不再工作。
Backtrader在集成一个名为 pyfolio 的投资组合工具时,遇到了一些挑战,但也取得了一些进展。主要的障碍在于正确设置所需的依赖项。这在软件开发中很常见,尤其是在集成外部库时。
总的来说,将 pyfolio 与 Backtrader 集成是一个复杂的过程,涉及到管理依赖项、确保跨不同操作系统的兼容性,并进行彻底的测试。然而,有了正确的工具和资源,就可以克服这些挑战,创建一个强大的投资组合分析工具。
这里感觉就是跟pyfolio之间配合的不太好的意思,所以在这样的背景下,我们不会花费太多的精力在这个上面,不过该学习和实践的流程还是需要走的。
使用方法 usage
在第1个页面上有使用方法(usage)
Add the
PyFolioanalyzer to thecerebromix:cerebro.addanalyzer(bt.analyzers.PyFolio)Run and retrieve the 1st strategy:
strats = cerebro.run() strat0 = strats[0]Retrieve the analyzer using whatever name you gave to it or the default name it will be given to it:
pyfolio. For example:pyfolio = strats.analyzers.getbyname('pyfolio')Use the analyzer method
get_pf_itemsto retrieve the 4 components later needed forpyfolio:returns, positions, transactions, gross_lev = pyfoliozer.get_pf_items()!!! note
The integration was done looking at test samples available with `pyfolio` and the same headers (or absence of) has been replicatedWork with
pyfolio(this is already outside of the backtrader ecosystem)
02_实践过程
_关于pyfolio库的安装
参考文档:
- Backtrader快速入门——3. 使用pyfolio进行可视化分析-CSDN博客
- pyfolio工具结合backtrader分析量化策略组合,附源码+问题分析-CSDN博客
- empyrical、pyfolio工具介绍及在backtrader量化框架中使用-CSDN博客
首先,已经安装了backtrader的是否还需要安装pyfolio?这个第一个让我疑惑的问题,因为很明显的backtrader里Analyzer中就有pyfolio嘛。
验证它也非常简单,在notebook里直接
import pyfolio as pf然后就得到一个错误反馈
ModuleNotFoundError: No module named 'pyfolio'
这样就明白了,pyfolio是没有安装的,所以Analyzer中的pyfolio与pyfolio库本质上是二件事。
从参考文档上得到的信息是:直接install会报各式各样的错误,要用git拉开发版,但我在看到这些之前已经按下了按钮,所幸安装是成功了。
pip install pyfolio_第一部分的实践
根据官方文档以及参考文档,在使用pyfolio的时候,我们需要添加一些语句,我们先人为把它分成2个部分,先来看第一个部分的代码:
cerebro = bt.Cerebro()
#......
cerebro.addanalyzer(bt.analyzers.PyFolio, _name='_PyFolio') # 加入pyfolio分析者
#......
result = cerebro.run() # 运行
strat = result[0]
pyfoliozer = strat.analyzers.getbyname('_PyFolio')
returns, positions, transactions, gross_lev = pyfoliozer.get_pf_items()
print(transactions)
amount price sid symbol value date 2023-03-23 00:00:00+00:00 9779.951100 4.09 0 601086 -40000.000000 2023-04-07 00:00:00+00:00 -9779.951100 3.89 0 601086 38044.009780 2023-05-04 00:00:00+00:00 10454.333757 3.75 0 601086 -39203.751589 2023-05-25 00:00:00+00:00 -10454.333757 4.37 0 601086 45685.438519 2023-06-07 00:00:00+00:00 8289.781377 5.04 0 601086 -41780.498138 2023-06-14 00:00:00+00:00 -8289.781377 4.42 0 601086 36640.833685 2023-07-11 00:00:00+00:00 8943.925785 4.44 0 601086 -39711.030483 2023-08-10 00:00:00+00:00 -8943.925785 6.27 0 601086 56078.414669 2023-09-28 00:00:00+00:00 8531.200243 5.42 0 601086 -46239.105319 2023-10-11 00:00:00+00:00 -8531.200243 5.27 0 601086 44959.425283 2023-10-26 00:00:00+00:00 8945.390516 5.11 0 601086 -45710.945537 2023-12-06 00:00:00+00:00 -8945.390516 5.39 0 601086 48215.654882 2024-01-05 00:00:00+00:00 8810.504154 5.30 0 601086 -46695.672016 2024-01-22 00:00:00+00:00 -8810.504154 5.25 0 601086 46255.146808 2024-02-26 00:00:00+00:00 11369.871599 4.09 0 601086 -46502.774838 2024-04-03 00:00:00+00:00 -11369.871599 4.74 0 601086 53893.191377 2024-04-09 00:00:00+00:00 9694.143360 5.10 0 601086 -49440.131138 2024-04-17 00:00:00+00:00 -9694.143360 4.37 0 601086 42363.406485 2024-05-09 00:00:00+00:00 10085.200068 4.62 0 601086 -46593.624312 2024-05-15 00:00:00+00:00 -10085.200068 4.50 0 601086 45383.400304 2024-06-17 00:00:00+00:00 11788.516590 3.91 0 601086 -46093.099867
有没有发现这里出来的东西感觉很熟悉?是不是在哪刚刚见过?我们从第(1)节的09_交易记录Transactions的输出再看一下
Date: 2023-03-23 00:00:00
[9779.9511002445, 4.09, 0, '601086', -40000.0]
Amount: 9779.9511002445, Price: 4.09, Sid: 0, Symbol: 601086, Value: -40000.0
Date: 2023-04-07 00:00:00
[-9779.9511002445, 3.89, 0, '601086', 38044.009779951106]
Amount: -9779.9511002445, Price: 3.89, Sid: 0, Symbol: 601086, Value: 38044.009779951106......
所以,这部分的功能就是前面我们已经实践过的,只不过它用了一个函数 get_pf_items()把4个评价指标都做成了pandas的格式,而前面我们仅仅是使用函数get_analysis()获取整个对象。
所以,我们也可以像前面一样,把这些东西写到我们的函数里去
def add_analyzer_all(cerebro):
# cerebro.addanalyzer(bt.analyzers.TimeReturn, _name='pnl') # 返回收益率时序数据
cerebro.addanalyzer(bt.analyzers.PyFolio, _name='_PyFolio')
def analyzer_output(result):
print('---------Pyfolio________________')
rets,pos,trans,level = result.analyzers._PyFolio.get_pf_items()
print(trans)然后输出的结果跟前面的是一样的。
第一部分的实践小结:
- 第一部分本质上还是添加了bt.analyzers.PyFolio这个内置的评价指标
- 在数据的格式上,并没有使用get_analysis()来获取,而是使用.get_pf_items()得到4个pandas的数据,分别赋给 returns, positions, transaction 和 gross_level了
_第二部分的实践
第二部分,见官方文档 Analyzers-PyFolio的 Sample Code部分中 pyfolio showtime的内容
# pyfolio showtime
import pyfolio as pf
pf.create_full_tear_sheet(
returns,
positions=positions,
transactions=transactions,
gross_lev=gross_lev,
live_start_date='2005-05-01', # This date is sample specific
round_trips=True)
# At this point tables and chart will show up看上去,只是运行了create_full_tear_sheet()这个函数,然后表格和图就会显示出来?从这个方向理解的话,pyfolio是不是一个画表格画图的库?然后我们需要的得到一些评价指标的计算在哪里?
pyfolio源码查询
任意新开一个py文件,输入 import pyfolio ,然后点击pyfolio跳转到__init__.py文件
# pyfolio\__init__.py
from . import utils
from . import timeseries
from . import pos
from . import txn
from . import interesting_periods
from . import capacity
from . import round_trips
from . import risk
from . import perf_attrib
from .tears import * # noqa
from .plotting import * # noqa
from ._version import get_versions
放到AI里去得到解析如下
from . import utilsutils子模块。可能包含一些通用的实用函数,如数据处理、字符串操作等。
from . import timeseriestimeseries子模块。可能提供了与时间序列分析相关的功能,如计算时间序列数据的各种统计指标。
from . import pospos子模块。可能与投资组合的持仓相关,可能包括持仓分析、持仓调整等功能。
from . import txntxn子模块。可能与交易相关,可能包括交易分析、交易成本计算等功能。
from . import interesting_periodsinteresting_periods子模块。可能与投资组合的关键时期相关,如牛市、熊市等,可能提供这些时期的识别和分析功能。
from . import capacitycapacity子模块。可能与投资组合的容量相关,包括容量限制、调整等功能。
from . import round_tripsround_trips子模块。这个子模块可能与投资组合的循环交易相关,提供循环交易的识别和分析功能。
from . import riskrisk子模块。可能与投资组合的风险相关,包括风险度量、风险管理等功能。
from . import perf_attribperf_attrib子模块。可能与投资组合的表现归因相关。
from .tears import *tears子模块。包含与可视化相关的功能,用于创建各种投资组合表现报告。
from .plotting import *plotting子模块。包含与数据可视化相关的功能,用于创建各种图表和图形。
from ._version import get_versions_version子模块中的get_versions函数。用于获取模块的版本信息。
初步看起来,估计与 utils, pref_*, tears这些模块会有些关系~
接着,我们看示例代码中使用的函数create_full_tear_sheet(),点击它会跳转到tears.py中,同上我们把函数的解释部分交给AI,得到一系列的解析:
这段代码定义了一个名为
create_full_tear_sheet的函数,它是pyfolio库的一部分,用于生成一系列投资组合表现分析报告。以下是对函数参数的解析:
returns: 策略的每日非累积回报率,是日期时间索引的Pandas Series。
positions: 每日净持仓价值,是日期时间索引的Pandas DataFrame,包含持仓和现金。
transactions: 执行的交易量与成交价格,是日期时间索引的Pandas DataFrame,每一行代表一次交易。......
set_context: 是否设置默认的绘图风格上下文。
factor_partitions: 指定因子应该如何在绩效归因、因子回报率和风险暴露图中分离的映射。该函数的主要目的是创建一系列分析报告,包括回报率、持仓分析、交易分析、贝叶斯分析和循环交易分析。这些报告有助于深入分析策略的性能,并提供了各种调整参数以适应不同的分析需求
然后,向下看,full_tear_sheet 调用了 create_returns_tear_sheet , interesting_times_tear, 并根据参数是否调用 position_tear, txn_tear, capacity_tear, risk_tear以及perf_atrrib_tear和bayesian_tear等。另外还有一个simple_tear_sheet与之相对应。
名为
create_simple_tear_sheet的函数,它是pyfolio库的一部分,用于生成一个更简单的投资组合表现分析报告。这个报告以单个图像的形式展示了汇总绩效统计数据和重要图表。这个函数的主要目的是创建一个简化的投资组合表现分析报告,它包含以下图表:
- 累积回报率
- 滚动贝塔值
- 滚动夏普比率
- 资金亏损图
- 暴露度
- 前10大持仓
- 总持仓
- 多头/空头持仓
- 每日周转率
- 交易时间分布
与
create_full_tear_sheet函数相比,create_simple_tear_sheet函数不接受market_data和sector_mappings输入,不执行bootstrap分析,不在前10大持仓图中隐藏持仓符号名称,并总是使用默认的cone_std值。
代码实践与问题
大概了解了pyfolio上要做点什么,我们就来进行代码的实践了。首先,与官方文档用相同的函数进行测试,
#..................
pyfoliozer = strat.analyzers.getbyname('pyfolio')
returns, positions, transactions, gross_lev = pyfoliozer.get_pf_items()
pf.create_full_tear_sheet(
returns,
positions=positions,
transactions=transactions,
live_start_date='2023-01-11')IndexError: single positional indexer is out-of-bounds
虽然不知道哪里出错了,但可以试一下改变参数,因为从下面的源码上看,当position为None以及transactions为None会有些函数不运行,这样或许就可以把问题锁定到更小的范围内
create_returns_tear_sheet(
returns,
positions=positions,
transactions=transactions,
live_start_date=live_start_date,
cone_std=cone_std,
benchmark_rets=benchmark_rets,
bootstrap=bootstrap,
turnover_denom=turnover_denom,
header_rows=header_rows,
set_context=set_context)
create_interesting_times_tear_sheet(returns,
benchmark_rets=benchmark_rets,
set_context=set_context)
if positions is not None:
create_position_tear_sheet(returns, positions,
hide_positions=hide_positions,
set_context=set_context,
sector_mappings=sector_mappings,
estimate_intraday=False)
if transactions is not None:
create_txn_tear_sheet(returns, positions, transactions,
unadjusted_returns=unadjusted_returns,
estimate_intraday=False,
set_context=set_context)# pf.create_full_tear_sheet(
# returns,
# positions=positions,
# transactions=transactions,
# live_start_date='2023-01-13')
pf.create_full_tear_sheet(returns,live_start_date='2023-01-13')这次仍然报错,但已经有部分的数据输出了。
Start date 2023-01-16 End date 2024-07-16 In-sample months 0 Out-of-sample months 17 In-sample Out-of-sample All Annual return nan% 7.9% 7.9% Cumulative returns nan% 11.6% 11.6% Annual volatility nan% 17.6% 17.6% Sharpe ratio NaN 0.52 0.52 Calmar ratio NaN 0.56 0.56 Stability NaN 0.61 0.61 Max drawdown nan% -14.2% -14.2% Omega ratio NaN 1.16 1.16 Sortino ratio NaN 0.84 0.84 Skew NaN 1.10 1.10 Kurtosis NaN 8.44 8.44 Tail ratio NaN 0.90 0.90 Daily value at risk nan% -2.2% -2.2% --------------------------------------------------------------------------- AttributeError: 'Series' object has no attribute 'iteritems'
AttributeError 'iteritems'
这个问题下列几个参考文档都有提供解决方案
- pyfolio工具结合backtrader分析量化策略组合,附源码+问题分析-CSDN博客
- Backtrader 试用,empyrical、pyfolio、quantstats记录-CSDN博客
"pyfolio\plotting.py", line 648
直接改pyfolio源码,将648行改为:
#for stat, value in perf_stats[column].iteritems():
for stat, value in perf_stats[column].items():
这个改掉后,注意要重启Notebook的Kernel,否则之前的.py已经Load进内核了,不重启它不会改变的。然后,这个问题不报了,还会出现其他的问题。根据参考文档的提示,可能需要更改好多个.py文件,这些就变成了额外的工作量。我们现在是在backtrader的主线上走一个更多评价指标的分支,太多的额外工作量让我们的实践脱离了正轨,所以我们准备对pyfolio说"No"了。
使用simple_tear
在say No之前,各种方法都再试用一下,前提是不用花费太多的时间,根据前面看到的,simple_tear会生成更简洁的分析报告,那就试一下。
pf.create_simple_tear_sheet(returns,live_start_date='2023-01-13')
--------------------
IndexError: index -1 is out of bounds for axis 0 with size 0结果,首先表格出来了,其次,出来3张图的背景,cumulative returns还显示了红色的线,但仍然报错没有走完。
仔细想一下,我们之前想要的就是pyfolio来计算一些评价指标而已,并不是需要炫酷的图像输出,因为那一支股票一个策略的一堆图像在大量股票和多策略的大数据下,起不到太大的作用,我们要的是大量数据的统计,而不是一支的各维度的图像显示。
_另一个方向的实践
之前的目标是用pyfolio来计算评价指标,比如阿尔法收益,MAR率,Omega等,而且我问AI得到的代码说就是用pyfolio来计算的,但事实证明这次AI又错了(错误示例见下面代码)。好几次了,AI辅助编程,平时能带给你一些小的省事,关键的时候却是误导你出大的错误。这些像不像一些股评家,平时听他们的可能有一点小的盈利,关键的时候来一个杀猪盘......
from pyfolio import alpha_beta
# 假设你有backtrader的回测结果
# 这里我们使用一个假设的收益率序列作为示例
cumulative_returns = [0.02, 0.03, 0.04, 0.05, 0.06]
benchmark_returns = [0.01, 0.02, 0.03, 0.04, 0.05]
# 计算阿尔法和贝塔
alpha, beta = alpha_beta.alpha_beta(cumulative_returns, benchmark_returns)
print(f"阿尔法(Alpha): {alpha}")
print(f"贝塔(Beta): {beta}")
----------------------------------
ImportError: cannot import name 'alpha_beta' from 'pyfolio'而现在我们虽然卡在了绘图上,但是一些评价指标已经出来了,以表格的形式。也就是说在报错之前,我们已经可以从另一个方向上获取到评价指标的计算了。
我们需要从源码上一点一点去搜索,先从simple_tear的函数上看,除了returns是必须的外,其他基本上默认都是None,这样很多代码类似 xx is not None 的判断语句块就可以直接跳过不看。
def create_simple_tear_sheet(returns,
positions=None,
transactions=None,
benchmark_rets=None,
slippage=None,
estimate_intraday='infer',
live_start_date=None,
turnover_denom='AGB',
header_rows=None):
#.........
于是得到的第一个执行的函数是
plotting.show_perf_stats(returns,
benchmark_rets,
positions=positions,
transactions=transactions,
turnover_denom=turnover_denom,
live_start_date=live_start_date,
header_rows=header_rows)我们在自己的程序里调用它,然后得到了表格的输出

这就说明了上面表格里的一堆评价指标已经完成计算了。因此,一步一步撸源码,从plotting.show_perf_stats里的perf_stats到 timeseries中的perf_stats,然后从大写的SMIPLE_STST_FUNCS看到list里有一堆ep.开头的、非常像评价指标计算的函数调用。接着再点进去跳到empyrical\stats下的例如 def omega_ratio()函数,这就是我们一直想找的评价指标的计算部分了。
注意,我们找到了评价指标计算的部分,但它已经不在pyfolio里面,

从另一方向,我们发现了pyfolio可能主要是来绘制表格和图形的,而评价指标的计算并不在它里面,而是调用的empyrical库进行的。因此,我们的实践又跳转到empyrical了。
B_empyrical的实践
或许是前面安装了pyfolio的原因,empyrical的库直接就可以使用了。
01_几个评价指标的计算示例
首先,我们用help(), dir()来学习一下empyrical的基础
import empyrical as ep
help(ep.stats)
# .........略
dir(ep.stats)
# .........略# 得到的一些指标如下:
from .stats import (
aggregate_returns, alpha, alpha_aligned, alpha_beta, alpha_beta_aligned,
annual_return, annual_volatility, beta, beta_aligned, cagr,
beta_fragility_heuristic, beta_fragility_heuristic_aligned, gpd_risk_estimates,
gpd_risk_estimates_aligned, calmar_ratio, capture, conditional_value_at_risk,
cum_returns, cum_returns_final, down_alpha_beta, down_capture, downside_risk,
excess_sharpe, max_drawdown, omega_ratio, roll_alpha, roll_alpha_aligned,
roll_alpha_beta, roll_alpha_beta_aligned, roll_annual_volatility, roll_beta,
roll_beta_aligned, roll_down_capture, roll_max_drawdown, roll_sharpe_ratio,
roll_sortino_ratio, roll_up_capture, roll_up_down_capture, sharpe_ratio,
simple_returns, sortino_ratio, stability_of_timeseries, tail_ratio, up_alpha_beta,
up_capture, up_down_capture, value_at_risk
)
看起来有不少,我们就挑几个进行实践,这里继续通过AI来生成示例代码
001_夏普率
import pandas as pd
from empyrical import *
# 假设你有Backtrader的回测结果
# 这里我们使用一个假设的收益率序列作为示例
cumulative_returns = [0.02, 0.03, 0.04, 0.05, 0.06]
returns1 = pd.Series(cumulative_returns)
# 计算夏普比率
sharpe_ratio = sharpe_ratio(returns1,risk_free=0)
print(f"夏普比率: {sharpe_ratio}")
------------------------
夏普比率: 40.15968127363563从示例代码上看,大多数的评价指标都以日收益率进行计算的,并且要求为pandas.Series类型。
002_Calmar 比率
import empyrical
import pandas as pd
# 假设您有一个包含每日收益率的 pandas Series
daily_returns = pd.Series([0.01, -0.02, 0.03, 0.04, -0.05, 0.06])
# 计算 Calmar 比率
calmar_ratio_value = empyrical.calmar_ratio(daily_returns)
print(f"Calmar Ratio: {calmar_ratio_value}")
-------------------
Calmar Ratio: 293.20185460273103003_计算MAR率
前面我们已经学习到MAR率是年化收益率/ 最大回撤率得到的,empyrical中没有直接的MAR率,但我们可以通过简单的除法运算得到
import empyrical
import pandas as pd
# 假设您有一个包含每日收益率的 pandas Series
daily_returns = pd.Series([0.01, -0.02, 0.03, 0.04, -0.05, 0.06])
# 计算 最大回撤
max_drawdown = empyrical.max_drawdown(daily_returns)
# 计算 累计收益
cumulative_returns = empyrical.cum_returns(daily_returns)
max_cumulative_return = cumulative_returns.max()
# 计算 MAR 比率
mar_ratio = max_cumulative_return / -max_drawdown
print(f"MAR Ratio: {mar_ratio}")
--------------------
MAR Ratio: 1.3539135264004_计算年化波动率和标准离差
从示例代码上,我们也看到了年化波动率有函数直接得出,而标准离差需要再计算其方差和开根号操作才能间接得到,我们的实践也从直接调用评价指标函数慢慢升级到调用2个函数并做简单乘除,再升级到调用函数后做std()和sqrt()等较复杂的计算,这里还使用了numpy。
import empyrical
import pandas as pd
import numpy as np
# 假设您有一个包含每日收益率的 pandas Series
daily_returns = pd.Series([0.01, -0.02, 0.03, 0.04, -0.05, 0.06])
# 计算 年化波动率
annual_volatility_value = empyrical.annual_volatility(daily_returns)
# 计算 年化波动标准离差
# 假设一年有252个交易日
trading_days = 252
annualized_standard_deviation = np.std(daily_returns) * np.sqrt(trading_days)
print(f"Annual Volatility: {annual_volatility_value}")
print(f"Annualized Standard Deviation: {annualized_standard_deviation}")
----------------------------
Annual Volatility: 0.6461269225160022
Annualized Standard Deviation: 0.5898304841223451005_计算阿尔法-贝塔收益
简单的引用参考文档中关于阿尔法-贝塔的说明
阿尔法(alpha、α值)
投资者获得与市场波动无关的回报,也叫超额收益。 比如投资者获得了15%的回报,其基准获得了10%的回报,那么Alpha或者价值增值的部分就是5%
10. 贝塔(beta、β值)反映了策略对大盘变化的敏感性。例如一个策略的Beta为1.5,则大盘涨1%的时候,策略可能涨1.5%,反之亦然。
具体计算方法为:策略每日收益与参考标准每日收益的协方差/参考标准每日收益的方差。
Beta coefficient = Covariance(Re, Rm)/Variance(Rm)
其中:Re为单一股票的回报, Rm为整体市场的回报,Covariance为股票收益相对整体市场收益的变化情况, Variance为市场数据远离平均值的幅度
从说明上看,这些评价指标不是用一个策略的returns就能计算的,它必须还有一个市场收益率的数据,两者做比较才能得出结果。示例代码仍然非常简单,多生成一个Series数据即可:
import empyrical
import pandas as pd
# 假设您有一个包含每日投资组合收益率的 pandas Series
portfolio_returns = pd.Series([0.01, -0.02, 0.03, 0.04, -0.05, 0.06])
# 假设您有一个包含每日市场基准收益率的 pandas Series
benchmark_returns = pd.Series([0.005, -0.01, 0.02, 0.03, -0.04, 0.05])
# 计算 Alpha 和 Beta
alpha, beta = empyrical.alpha_beta(portfolio_returns, benchmark_returns)
print(f"Alpha: {alpha}")
print(f"Beta: {beta}")
-----------------------------
Alpha: -0.008330392443637757
Beta: 1.276348547717842202_放回到backtrader中进行计算
001_有returns就能计算的
backtrader自身的Analyzer中就有TimeReturn,由于大部分的评价指标有returns就能计算,这个部分的测试就比较轻松,我们以夏普比率和之前backtrader出不了值的Calmar率做个简单的应用
def add_analyzer_all(cerebro):
# 需要通过数据记录进行计算
cerebro.addanalyzer(bt.analyzers.TimeReturn, _name='pnl') # 返回收益率时序数据 # 03
import empyrical
import pandas as pd
import numpy as np
def analyzer_output(result):
dic1 = {}
sout03 = result.analyzers.pnl.get_analysis()
daily_returns = pd.Series(sout03)
# 计算 Calmar 比率
calmar_ratio_value = empyrical.calmar_ratio(daily_returns) # 之前backtrader 14_calmar是NaN
print(f"Calmar Ratio: {calmar_ratio_value}")
# 计算夏普比率
sharpe_rat = empyrical.sharpe_ratio(daily_returns,risk_free=0)
print(f"夏普比率: {sharpe_rat}")
----------------------------
Calmar Ratio: 0.5598883363715573
夏普比率: 0.5211845089137789002_需要基准收益的
什么是基准日收益
我们还是直接问AI
包含市场基准日收益率的 benchmark_returns,请问是具体指什么,例如是上证指数,沪深300指数吗?
是的,benchmark_returns 通常指的是市场基准的日收益率,这可以是一个广泛认可的市场指数,如上证指数、沪深300指数、标普500指数等。市场基准是一个被广泛用作投资表现比较标准的指数,它代表了一个特定的市场或市场部门的表现。
在计算 Alpha 和 Beta 时,市场基准的收益率被用来衡量投资组合相对于市场的表现。
Alpha 衡量的是投资组合相对于基准的超额收益,而 Beta 衡量的是投资组合收益与基准收益的同步波动性。Beta 值大于 1 意味着投资组合的波动性大于市场,而 Beta 值小于 1 意味着波动性小于市场。
获取基准日收益
我们已经在backtrader里探索了一段时间了,从一开始我们就要下载数据,制作成feeddata接受的格式,然后已经很长时间没有去回顾这个操作了。这几天的Analyzer的实践,已经习惯了从.run()之后取数据,突然要多一个基准日收益,反而有些不知所措了。
其实,在我们的K线数据文件夹下面,就有指数的.csv文件,我们可以直接读取这个文件来获取数据然后计算出日收益。
fname = 'dayData/999999_raw.csv'
df = pd.read_csv(fname, index_col='trade_date')
df
trade_date open high low close volume openinterest 2022-10-25 2969.16 3001.72 2944.26 2976.28 255554160.0 0 2022-10-26 2977.56 3028.35 2977.56 2999.50 268689504.0 0 2022-10-27 3005.04 3017.26 2981.69 2982.90 265608256.0 0 2022-10-28 2967.02 2974.24 2908.98 2915.93 292531296.0 0 2022-10-31 2893.20 2926.02 2885.09 2893.48 301994208.0 0 ... ... ... ... ... ... ... 2024-07-10 2949.03 2958.86 2935.33 2939.36 301549440.0 0 2024-07-11 2957.25 2971.36 2947.40 2970.39 328372416.0 0 2024-07-12 2965.61 2977.14 2963.30 2971.30 303713024.0 0 2024-07-15 2963.85 2977.31 2959.13 2974.01 268992608.0 0 2024-07-16 2963.90 2977.36 2959.67 2976.30 260783632.0 0 420 rows × 7 columns
计算出日收益率
拿到了DataFrame的数据,心里有个简单的概念,用(今天收盘-昨天收盘)/昨天收盘就得到了日收益率,第一反应是做一个函数让pandas去apply。 然后第二反应是问下AI怎么做。这次AI给了一个不错的回答, dataframe可以直接用.pct_change()得到日收益率。
df['pct_change'] = df['close'].pct_change()
获取起止范围内的日收益率
在简单测试的时候,我们直接创建2个Datetime即可,
# d1,d2均为datetime类型
date1_str = "2023-01-11"
date2_str = "2024-07-18"
d1 = datetime.strptime(date1_str, "%Y-%m-%d")
d2 = datetime.strptime(date2_str, "%Y-%m-%d")
filtered_df = df.loc[d1:d2]制作函数并在analyzer_output中调用
def my_get_benchmark_returns(datestart,dateend):
fname = 'dayData/999999_raw.csv'
df = pd.read_csv(fname)
df['pct_change'] = df['close'].pct_change() # 计算出日收益率
# 将 'trade_date' 列转换为日期格式,并将其设置为索引
df['trade_date'] = pd.to_datetime(df['trade_date'])
df.set_index('trade_date', inplace=True)
filtered_df = df.loc[datestart:dateend]
ret1 = filtered_df['pct_change']
return ret1
def analyzer_output(result):
sout03 = result.analyzers.pnl.get_analysis()
daily_returns = pd.Series(sout03)
# 通过daily_returns获取 起、止日期
datestart = daily_returns.index[0]
dateend = daily_returns.index[-1]
bench_returns = my_get_benchmark_returns(datestart,dateend)
# print(bench_returns)
# 计算 Alpha 和 Beta
alpha, beta = empyrical.alpha_beta(daily_returns, bench_returns)
print(f"Alpha: {alpha}")
print(f"Beta: {beta}")
------------------------------------
Alpha: 0.10868566697398885
Beta: 0.2365168968524076C_Quantstats实践
参考文档
- Backtrader 量化回测实践(6)——量化回测评价工具Quantstats-CSDN博客
- 量化策略——准备3 数据、Backtrader回测框架与quantstats评价指标_backtrader 模版-CSDN博客
- 【从零开始玩量化13】quantstats:分析你的量化策略-CSDN博客
- Backtrader 试用,empyrical、pyfolio、quantstats记录-CSDN博客
Quantstats主要功能
仍然把英文的说明交给AI解析:
QuantStats主要由以下三个模块组成:
quantstats.stats:这个模块用于计算各种绩效指标,如夏普比率(Sharpe ratio)、胜率(Win rate)、波动率(Volatility)等。这些指标对于评估交易策略的风险与收益特性至关重要。
quantstats.plots:此模块专注于可视化,提供图表以展示策略的绩效、回撤、滚动统计、月度回报等。这有助于直观理解策略的表现和潜在风险。
quantstats.reports:这个模块用于生成绩效报告,批量绘图,并创建可以保存为HTML文件的详细分析表(tear sheets)。这对于整理和分享策略的全面分析结果非常有用。这些模块共同构成了
QuantStats,使其成为量化交易策略分析和报告生成的强大工具。
其中,.stats模块就是各种评价指标计算的模块,也是我们这次实践的主要目的;不过在尝试了plots模块后,发现有惊喜~
stats模块实践
首先是确定是否需要安装 quantstats,很明显目前是没有安装的。
import quantstats as qs
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[125], line 1
----> 1 import quantstats as qs
ModuleNotFoundError: No module named 'quantstats'安装命令
pip install quantstats
001_夏普率
df = pd.DataFrame({
'returns': [0.01, -0.02, 0.03, 0.04, -0.05, 0.06] # 示例数据
})
# 计算夏普比率
sharpe_ratio = qs.stats.sharpe(df['returns'], rf=0.02)
print(f"Sharpe Ratio: {sharpe_ratio}")
----------------------------
Sharpe Ratio: 4.519540190723975我们看到,如果只是运行示例代码会非常简单,它与前面的empyrical的调用方式差不多
在backtrader中使用时,还是在analyzer_output()函数中,先获取 03_TimeReturn的数据,然后调用qs.stats.XXX()来进行评价指标计算。
002_calmar率 与003_MAR率
我们还是把代码放回到backtrader的Analyzer中进行实践
import quantstats as qs
import pandas as pd
def add_analyzer_all(cerebro):
cerebro.addanalyzer(bt.analyzers.TimeReturn, _name='pnl') # 返回收益率时序数据 # 03
def analyzer_output(result):
dic1 = {}
sout03 = result.analyzers.pnl.get_analysis()
returns = pd.Series(sout03)
# 夏普率
sharp_qs = qs.stats.sharpe(returns,rf=0)
dic1['qs_夏普率'] = sharp_qs
# calmar率
calmar_qs = qs.stats.calmar(returns)
dic1['qs_calmar'] = calmar_qs
# MAR率
max_drawdown = qs.stats.max_drawdown(returns) # 计算最大回撤(Maximum Drawdown)
average_return = qs.stats.avg_return(returns) # 计算平均收益率(Average Return)
mar_ratio = -max_drawdown / average_return # 计算 MAR 比率
dic1['qs_MAR'] = mar_ratio
print(dic1)
-------------------------------
{'qs_夏普率': 0.5211845089137789,
'qs_calmar': 0.3653708565550549,
'qs_MAR': 173.7097122199193}004_年化波动率
我们在notebook中直接借用刚才得到的returns的数据,可以看到包括年化波动率计算也是直接调用写好的函数进行的,函数内容从源码中也能看得到。
# "年波动率":
volat = qs.stats.volatility(ret1)
volat
'''
def volatility(returns, periods=252, annualize=True, prepare_returns=True):
"""Calculates the volatility of returns for a period"""
if prepare_returns:
returns = _utils._prepare_returns(returns)
std = returns.std()
if annualize:
return std * _np.sqrt(periods)
return std
'''
---------------------
0.12866840859812584
005_阿尔法-贝塔收益
最后,我们又来到alpha-beta这个评价指标上了,前面在empyrical里已经知道了,对于部分指标它需要添加市场benchmark的日收益率做为基准才能进行计算,我们又可以借用刚才制作的函数。
def my_get_benchmark_returns(datestart,dateend):
fname = 'dayData/999999_raw.csv'
df = pd.read_csv(fname)
df['pct_change'] = df['close'].pct_change() # 计算出日收益率
# 将 'trade_date' 列转换为日期格式,并将其设置为索引
df['trade_date'] = pd.to_datetime(df['trade_date'])
df.set_index('trade_date', inplace=True)
filtered_df = df.loc[datestart:dateend]
ret1 = filtered_df['pct_change']
return ret1
def add_analyzer_all(cerebro):
cerebro.addanalyzer(bt.analyzers.TimeReturn, _name='pnl') # 返回收益率时序数据 # 03
def analyzer_output(result):
dic1 = {}
sout03 = result.analyzers.pnl.get_analysis()
returns = pd.Series(sout03)
# alpha-beta
datestart = returns.index[0] # 通过daily_returns获取 起、止日期
dateend = returns.index[-1]
bench_returns = my_get_benchmark_returns(datestart,dateend)
alphabeta = qs.stats.greeks(returns, bench_returns)
dic1['qs_alpha'] = alphabeta.alpha
dic1['qs_beta'] = alphabeta.beta
print(dic1)
---------------------------
{'qs_alpha': 0.10319635410459166,
'qs_beta': 0.23651689685240762}从以上的实践可以看到,使用quantstats与使用empyrical做评价指标计算的时候,它们的用法非常近似:
- 大多数只需要returns就可以进行计算的,一般都是调用函数就可以
- 部分需要添加基准日收益率的,其他过程的程序代码和函数都可以不用变化,只需要对应的函数调用不同即可
我们看到,alpha-beta的计算,两者结果是一致的,但是某些指标结果并不相同,这里我们暂时不去深究为什么了,empyrical和quantstats这两个库如果只是作为backtrader的Analyzer的辅助额外评价指标的计算,任选其一即可。
plot模块-绘图功能实践
到这里,其实本节的实践内容已经结束了,pyfolio的确如很多的参考文档写的不那么容易用起来,但我们通过它调用发现了empyrical库,然后能用empyrical库去快速得到一些backtrader没有的评价指标;然后我们又实践了quantstats库的评价指标计算功能,看起来与empyrical算是英雄所见略同吧。
在实践quantstats的过程中,尝试了绘图的功能,又带来一些额外的惊喜,所以这个部分继续。
有哪些绘图功能
#
from quantstats._plotting import wrappers
dir(wrappers)
-------------------------
把dir出来的内容再次交给AI进行整理,有19个函数:
daily_returns: 计算每日收益率。distribution: 绘制收益率分布。drawdown: 计算最大回撤。drawdowns_periods: 列出最大回撤发生的日期。earnings: 计算累计收益。histogram: 绘制收益率直方图。log_returns: 计算对数收益率。monthly_heatmap: 绘制月收益率热力图。monthly_returns: 计算月收益率。plotly: 生成 Plotly 图表。returns: 计算收益率。rolling_beta: 计算滚动贝塔值。rolling_sharpe: 计算滚动夏普比率。rolling_sortino: 计算滚动 Sortino 比率。rolling_volatility: 计算滚动波动率。snapshot: 创建快照。to_plotly: 将 DataFrame 转换为 Plotly 图表。warnings: 显示警告。yearly_returns: 计算年收益率。
001_日收益,回撤,累计收益与Snapshot
如标题,快照snapshot直接把日收益(daily_returns),回撤(drawdown)和累计收益(earnings)一起进行了绘图输出
qs.plots.snapshot(returns=ret1)
002_月热力分布图
qs.plots.monthly_heatmap(ret2,ret1)
开启亮眼模式,从这个热力分布图。注意国际上都是红跌绿涨跟我们大A是反着的,所以图也要反着颜色看,这张图让你知道每年大概哪几个月会赚钱~
003_直方图-histogram
直方图和正态分布图都能比较好的显示你的盈亏分布,如下图黄色代表上证指数有11次都在0%,赚8%的次数2次,其他外包装是0~-4%之间,而蓝色的这支股票,有2次-20%......
qs.plots.histogram(ret2,ret1)
004_分布图 distribution
qs.plots.distribution(returns=ret2)
在完成绘图模块的实践之后,我又冒出来很多的念头,比如说我们做个窗口程序来回测backtrader,然后把策略的日收益(有阶段不交易收益率为0)和基准的日收益存在self.xx里面,后面看多个股票多个策略的评价列表的时候,选择想看的那一行,然后再让quantstats进行绘图,这样就更有针对性,而且是建立在对大体评分已经有数的情况下,我觉得对于选股、选策略甚至择时都会有帮助......
report报告模块
报告就是把一堆评价指标的数据以表的形式,然后一些与时间相关的画成图,在一起显示。这里与我们的主线任务关系并不大,简单看下:
qs.reports.basic(returns=ret2, benchmark=ret1,rf=0.01, prepare_returns=False)basic会生成表格和几张图,表格里的基本上就是我们前面一直在研究的评价指标,它这里很贴心地也加上了类似基本近x期的涨幅指标,如图:

report模块里还有很多的函数,先把它们列在这里,但我们先不去实践了。
basic: 用于生成基本的性能指标。full: 用于生成完整的性能指标。html: 用于生成 HTML 格式的报告。iDisplay: 用于在 Jupyter Notebook 中显示数据。iHTML: 用于生成交互式 HTML 报告。metrics: 用于计算各种性能指标。plots: 用于绘制各种图表。relativedelta: 用于计算两个日期之间的相对差异。
本节小结
- 从backtrader内置的pyfolio到外部的pyfolio库的应用
- pyfolio目前用起来容易出现一些错误,影响主线进度,实践中发现评价指标的计算是调用empyrical进行的
- 对empyrical的评价指标函数的调用进行了实践,总体而言使用是很方便的
- 对quantstats的stats模块进行了实践,这个与empyrical的功能很近似,使用也很方便
- 对quantstats的绘图功能进行了尝试,某些图(例如热力图,直方图等)为我们分析选择股票提供了实用的可视化信息