集合
- 集合
- 集合接口等级:
- Collection:单例集合接口,将数据一个一个存储,存储的是值。
- ArrayList类:泛型集合
- Linkedlist集合:
- Vector集合:
- Stack集合:Vetor的子类
- Set接口:存储是无序的,且集合中的元素不可重复
- Hashset集合:
- Linkedhashset:是有序不重复的set集合,继承于hashset
- Treeset:排序,去重的集合
- Map接口:键值对集合(可类比数学中的函数)
- 1.HashMap集合:map接口的实现类
- HashMap集合put元素时的底层原理:
- 总结
- 2.LinkedHashMap集合:强调有序且去重,底层多维护了一条双向链表,用于存储添加元素顺序的信息
- 3.Treemap集合:可排序的键值对集合,以key类型的默认排序规则排序,如果key为自定义类型,则必须要实现comparable接口定义排序规则,或者采用treemap的有参构造,传入排序规则参数(comparactor)
- 4. Hashtable接口:无序,key唯一,key和value不可为null,线程更加安全,无参构造初始化对象时,数组长度有默认值
- Collections集合算法工具类的一些方法:
- 面试问到的:
- Collection和Collections的区别
- ArrayList和LinkedList的区别
- HashMap扩容机制
- HashMap的put过程
集合
集合接口等级:
分类


(1):Collection接口:单例集合接口
(2):map接口:双链接口
Collection:单例集合接口,将数据一个一个存储,存储的是值。
(1)特点:Collection接口为单例集合接口,将数据一个一个存储,存储的是值。
(2)子接口:分为list接口,set接口和queue接口
2.list接口:集合中最基础的接口,行为和数组一致
《1》特点:
1.元素是有序的,即存储和取出的顺序一致
2元素存储是可以重复的
《2》实现类:
1.ArrayList类
2.LinkedList类
3.Vetor类
4.Stack类

ArrayList类:泛型集合
《1》对象创建:
ArrayList<泛型> list =new ArrayList<泛型>()
《2》泛型于jdk1.5添加,可帮助我们建立类型安全的集合,再进行调用时必须传入实际的类型,对于泛型我们可以简单的理解为数据类型的占位符(必须是引用数据类型),它的优点:提高代码安全性,增强代码的可读性。
《3》方法:以对象list为例
(1)加:
(1.1)list.add(元素)—添加元素到集合list末尾,返回值为boolean,添加成功则为true。
(1.2)list.add(int index,元素)—添加元素到集合list指定下标处,无返回值。
(1.3)list.addAll(collection c)添加单例集合c到list集合末尾,返回值为boolean,添加成功则为true。
(1.4)list.addAll(int index,collection c)添加单例集合c到list集合的指定下标处,返回值为boolean,添加成功则为true
(2)查:
(2.1)list.get(int index)获取指定下标元素,返回值为泛型
(2.2)iist.size()获取集合长度,返回值为int型
(2.3)list.indexOf(元素),查找元素下标,返回值为int型,如果不存在,返回-1.
(2.4)list.contains(元素)判断集合中是否包含此元素,返回值为boolean
(2.5)list.isEmpty()判断集合是否为空,返回值为boolean
(2.6)list.equals(list2)判断两个集合中元素是否相同,返回值为boolean
(2.7)遍历集合:
(2.7.1)for循环遍历
(2.7.2)foreach循环遍历
(2.7.3)获取普通迭代器遍历:
Iteractor<泛型> it=list.iteractor();
Whlie(it.hasNext()){ 判断有无下一个元素
It.next //获取下一个元素
}
(2.7.4)获取list迭代器遍历:
Iistiteractor<泛型> it=list.listiteractor();
//可传入开始遍历的下标,也可逆序遍历
Whlie(it.hasNext()){ //判断有无下一个元素
It.next() //获取下一个元素
}
Whlie(it.hasPrevious()){ //判断有无上一个元素
It.Previous() //获取上一个元素
}
(3) 改:list.set(int index ,元素)修改集合中指定下标的元素为修改后的元素
(4) 删:
(4.1)list.remove(int index)删除集合中指定下标的元素,返回值为删除的元素
(4.2)list.remove(Object o)删除指定元素,返回值为boolean,注意如果参数传入数字,则系统默认该数字为集合下标,如果要删除的元素为该数字,则要强调传入的参数为Integer型
(4.3)list.clear()清空集合的所有元素,注意集合仍然存在,但长度为0
(4.4)list.removeAll(collection c)删除集合list在集合c中相同的元素,即求集合list和集合c的差集,返回值为boolean
(4.5)list.retainAll(collection c)保留集合list在集合c中相同的元素,即求集合list和集合c的交集,返回值为boolean
(5)其他:
(5.1)list.subList(int formindex,int toindex)截取集合中从index下标到toindex下标(不包括toindex)的部分,返回值和list集合一致。
(5.2)list.clone()克隆集合list,返回值与list一致
(5.3)list.sort(定义规则)对集合进行排序,需要自定义排序规则,创建匿名内部类实现comparator接口,重写compare方法。
(5.4)list.toArray()将集合转成数组,返回值为Object型数组
(5.5)list.toArray(泛型[] a)将集合转成数组,返回值为泛型数组
《4》ArrayList的其他两种构造方法:
ArrayList<泛型> list =new ArrayList<泛型>(int x)自定义ArrayList底层数组的初始化长度
ArrayList<泛型> list =new ArrayList<泛型>(collection c)按照传入的集合c对Arraylist底层存储的数组的长度进行初始化
《5》Arraylist存储的扩容原理:Arraylist集合的底层存储方式为Object型的数组,采用无参构造创建对象时,开始object型数组长度初始化为0,当第一次添加元素时,数组长度初始化为10,当存储到第十一个元素时,开始进行扩容,扩容原理为原来数组长度的1.5倍。
Linkedlist集合:
双向链表,节点为node类型
E item
Node<E> next
Node<E> prev
使用场景:大量的删除和插入元素
尾插ArrayList和LinkedList时间复杂度为O(1)
中间插入ArrayList时间复杂度O(n),LinkedList时间复杂度为O(1)
《1》由于Linkedlist和Arraylist都是list接口的实现类,因此Linkedlist可以使用Arraylist的绝大部分方法。
《2》Linkedlist独有的方法:以对象list为例
(1)list.addFirst(元素)添加元素到集合第一位
(2)List.addLast()添加元素到集合最后一位
(3)list.getFirst()获取集合首位元素
(4)list.getLast()获取集合最后一个元素
(5)list.removeFirst()删除集合首位元素
(6)list.removeLast()删除集合最后一个元素
《3》遍历集合时不推荐使用for循环,其余三种方式可使用
《4》Linkedlist底层存储方式为双指向链表,因此不存在扩容问题
Vector集合:
《1》特点:基于Object[]数组 elementData来实现的,类似于Arraylist
《2》创建对象的三种方式:
(1)Vetor<泛型> v1=new Vetor<泛型>()默认数组长度初始化为10,扩容时按2倍扩容
(2)Vetor<泛型> v1=new Vetor<泛型>(int x)自定义数组初始化长度为x
(3)Vetor<泛型> v1=new Vetor<泛型>(int x,int y)自定义数组初始化长度为x,扩容值为x+y
《3》Vetor与Arraylist的对比:
(1)线程:Arraylist线程不安全,Vetor线程安全
(2)效率:Arraylist效率更高,Vetor效率相对较低
(3)初始化:Arraylist开始初始化为0,第一次添加元素时,初始化为10。Vetor开始初始化为10.
(4)扩容:Arraylist按之前的1.5倍扩容,Vetor按2倍或自定义扩容值进行扩容
Stack集合:Vetor的子类
《1》特点:先进后出FILO,即最先存入的元素最后被拿出
《2》方法:以s1为例:
(1)s1.push(元素)添加元素------入栈
(2)S1.pop(元素)获取栈顶元素,并弹出该元素(出栈)
(3)S1.peek(元素)获取栈顶元素,不弹出该元素(出栈)
Set接口:存储是无序的,且集合中的元素不可重复
《1》特点:存储是无序的,且集合中的元素不可重复
《2》实现类:
(1)hashset
(2)Linkedhashset
(3)Treeset

Hashset集合:
《1》创建对象:
(1)Hashset<泛型> hs=new Hashset<泛型>()
(2)Hashset<泛型> hs=new Hashset<泛型>(collection c)
《2》方法:以对象hs为例
(1)hs.add(元素)添加元素到集合末尾,返回值为boolean
如果添加重复元素,则返回false,即无法添加成功
(2)hs.addAll(collection c)添加一个集合
(3)Hs.contains(元素)判断元素是否存在
(4)Hs.clear()清空集合内的所有元素
(5)遍历集合:for each循环,(普通)迭代器
《3》用途:hashset集合可以帮我们去重
《4》hashset集合去重的原理:
《4.1》通过hashcode判断两个元素是否有相同的hashcode值,如果有,则进行下一步判断,如果没有则直接存放
《4.2》通过equals方法比较两个元素内容是否相同,如果相同则不进行存放,反之则存放。
注意:重写hashcode方法时,必须要同时重写equals方法,因为可能有hashcode冲突的现象,即不同的对象可能存在相同的hashcode值。
Linkedhashset:是有序不重复的set集合,继承于hashset
Treeset:排序,去重的集合
(1)默认排序规则:《1》Integer类默认升序排列
《2》String类默认使用字符+长度进行排序
(3)注意事项: 《1》泛型必须要是引用数据类型
《2》泛型如果是自定义类型,必须要重写hashcode放法和equals方法同时必须要实现comparable接口,且重写其中的compareto方法,定义排序规则,或者使用有参构造传入一个comparactor对象,即匿名内部类重写compare方法定义排序,注意:如果同时出现实现comparable接口和给定comparactor对象(排序规则),后者的优先级要大于前者,前者为类级别,后者为对象级别
(4)构造方法:《1》无参构造
《2》有参构造:即传入一个conparactor对象,定义排序规则,优先级高于类上定义的comparable接口,因为此处是对此对象特殊强调的比较规则
Map接口:键值对集合(可类比数学中的函数)
1.HashMap集合:map接口的实现类
(1)特点:《1》元素按一对一对进行存取(key-value)
《2》无序性
《3》key唯一,不可重复,value可重复
《4》key和value均可为null
(2)方法:以对象hsm为例
《1》添:《1.1》hsm.put(key,value)返回值为oldvalue,存放时如果key不存在,则返回null,并添加新的键值对,如果key值已存在,则返回原key对应的值,并覆盖掉原key对应的值
《1.2》hsm.putifabsent(key,value)返回值为oldvalue,存放时如果key不存在,则返回null,并添加新的键值对,如果key值已存在,则返回原key对应的值,不对原key对应的值做任何处理
《1.3》hsm.putAll(map m)将指定集合m中的键值对全部存入hsm集合中,如果原集合中已存在此key,则覆盖原key对应的value。此方法无返回值
《2》查:《2.1》hsm.get(key)通过key获取对应的value,如果key不存在,则返回null,返回值为value
《2.2》hsm.getOrDefault(key,default)通过key获取对应的value,如果key不存在,则返回default,返回值为value
《2.3》hsm.containskey(key),判断key是否存在,返回值为boolean
《2.4》hsm.containsvalue(value),判断value是否存在,返回值为boolean
《2.5》hsm.isEmpty(),判断集合是否为空,返回值为boolean
《2.6》hsm.size(),获取集合中键值对的个数,即集合的长度,返回值为int
《3》改:《3.1》hsm.replace(key,value),根据key,替换对应的value,返回原value。如果key不存在,返回null,返回值为oldvalue。
《3.2》 hsm.replace(key,oldvalue,newvalue)根据key和对应的value,替换value,只有key和value都对应上才能替换成功,返回值为boolean
《4》删: 《4.1》hsm.remove(key)通过key删除对应的键值对,返回key对应的value,如果key不存在,则返回null
《4.2》 hsm.replace(key,value)根据key和对应的value,删除对应的键值对,只有key和value都对应上才能删除成功,返回值为boolean
《4.3》hsm.clear()清空集合中的键值对,
《5》遍历:《5.1》hsm.keyset()获取集合中所有的key,返回值为set类集合。遍历所有的key,再通过hsm.get(key)可获取到所有key对应的value
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("apple", 123);
map.put("pear", 456);
map.put("banana", 789);
for (String key : map.keySet()) {
Integer value = map.get(key); // 根据key,获取value
System.out.println(key + " = " + value);
}
}
}
《5.2》hsm.values()直接获取所有的value,返回值为collection集合
Map<String, Integer> map = new HashMap<>();
map.put("apple", 123);
map.put("pear", 456);
map.put("banana", 789);
Collection<Integer> values = map.values();
for (Integer val : values) {
System.out.println("value值= " + val);
}
《5.3》hsm.entryset()获取所有的键值对。每个key-value键值对都通过Entry类型的对象封装(可理解为每个key-value都成为了Entry类型对象的成员变量),通过对象名.getkey和对象名.getvalue,获取所有的键值对
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("apple", 123);
map.put("pear", 456);
map.put("banana", 789);
for (Map.Entry<String, Integer> entry : map.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key + " = " + value);
}
}
}
《5.4》for-each进行遍历
Map<String, Integer> map = new HashMap<>();
map.put("apple", 123);
map.put("pear", 456);
map.put("banana", 789);
map.forEach(new BiConsumer<String, Integer>() {
@Override
public void accept(String key, Integer value) {
System.out.println(key + " = " + value);
}
});
HashMap集合put元素时的底层原理:
(1)使用hash计算元素存储到数组的位置i=(数组长度-1)%hash,如果此处没有位置,则直接存储
(2)如果此处有元素,判断key地址或内容是否相同,如果是则覆盖原元素中的value值
(3)如果key不同则说明发生了hash冲突,此时元素已node节点形式连接到原位置元素的后面
先判断是否为树形,如果是,则按照树形结构添加,
如果不是则按照单向链表添加,已p==null作为判断,将新增元素添加到链表末尾
(4)扩容问题:
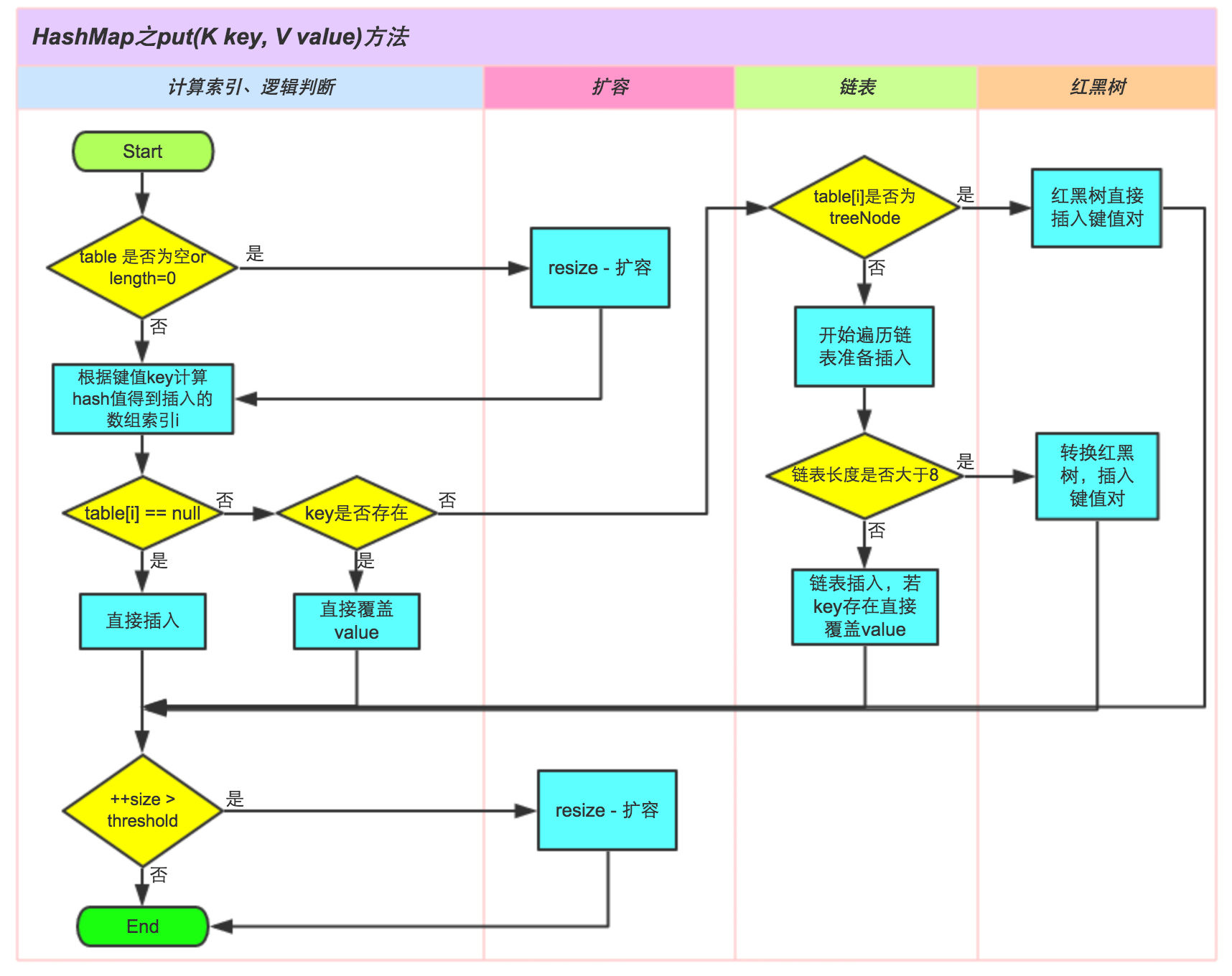
《1》首次添加元素,数组长度0—16,扩容阈值0—12.
《2》链表长度>8,数组长度<64,数组长度和扩容阈值都按两倍扩容
《3》数组中元素大于扩容阈值,扩容机制同上
总结
最常用的一种Map实现是HashMap;(无序,key唯一)
●HashMap的数据结构采用数组+链表+红黑树
●HashMap的按照key的hash值计算数组中的存储位置下标,计算方式:(n-1)&hash。
●如果在该下标位置已经存在元素,代表产生哈希冲突,则采用链地址法处理,以单向链表的形式,将新元素存储在链表的尾部(尾插法)。
●当链表中Node节点的数量大于8并且数组的长度大于64时,链表会转换成一个红黑树,有利于查找搜索。
●HashMap的默认容量为16,加载因子为0.75f,当集合元素个数超过扩容阈值(容量*加载因子)时,HashMap会将底层数组容量按照2倍进行扩容。
2.LinkedHashMap集合:强调有序且去重,底层多维护了一条双向链表,用于存储添加元素顺序的信息
3.Treemap集合:可排序的键值对集合,以key类型的默认排序规则排序,如果key为自定义类型,则必须要实现comparable接口定义排序规则,或者采用treemap的有参构造,传入排序规则参数(comparactor)
4. Hashtable接口:无序,key唯一,key和value不可为null,线程更加安全,无参构造初始化对象时,数组长度有默认值
Collections集合算法工具类的一些方法:

(1)public static boolean disjoint(Collection<?> c1, Collection<?> c2)判断两个集合中是否存在相同元素,如果存在,返回false,不存在返回true
(2)public static <T> void fill(List<? super T> list, T obj)将集合中的所有元素进行填充(修改),如果集合中没有元素,则不填充
(3)public static int frequency(Collection<?> c, Object o)获取集合中指定元素的出现次数,返回值为int
(4)public static T max(Collection<? extends T> coll)获取集合中的最大值,如果没有特别强调比较规则,则按照泛型默认的比较规则给出最大值
(5)public static T min(Collection<? extends T> coll)获取集合中的最小值,如果没有特别强调比较规则,则按照泛型默认的比较规则给出最小值
(6)public static void sort(List<T> list)对集合进行排序,如果没有特别强调排序规则,则按照泛型的默认排序规则进行排序
(7)public static void reverse(List<?> list)将集合中的元素逆序(反转)
(8)public static void shuffle(List<?> list)将集合中的元素打乱
(9)public static void swap(List<?> list, int i, int j)将集合中两个位置的元素进行交换
(10)public static int binarySearch(List<?> list, T key) 二分查找指定元素下标,要求集合必须有序(排序)
面试问到的:
Collection和Collections的区别
Collection 是一个接口,定义了所有集合类的通用行为和方法。
Collections 是一个工具类,包含了对集合进行操作的静态方法,如排序、查找等。
Collection:
Collection 是 Java 中表示一组对象的接口。它是所有集合类的根接口,定义了集合框架的通用行为和方法。Collection 接口继承自 Iterable 接口,提供了对集合中元素进行基本操作的方法,添加、查找、修改、删除、遍历
Collection 接口的子接口包括 List、Set 和 Queue。
Collections:
Collections 是 Java 中一个实用类,位于 java.util 包中。它包含了一些静态方法,用来操作各种集合类,比如 List、Set 和 Map
Collections 类提供了对集合进行排序、搜索、线程安全化等操作的静态方法。例如,sort() 方法用于对列表进行排序,synchronizedCollection() 方法用于返回一个线程安全的集合。
ArrayList和LinkedList的区别
①数据结构:ArrayList为数组,随着元素的增加而动态扩容。
LinkedList为双向链表,随着元素的增加,创建新的Node节点并进行分配空间。
②扩容方式:
ArrayList无参构造初始化为0,第一次添加元素时,扩容的大小为10。如果容量不足,则按原容量1.5倍扩容进行增长。
LinkedList由于采用链表结构,每次添加元素,都在创建新的Node节点进行分配空间,所以不存在扩容
③使用场景
ArrayList类:适用于数据连续的遍历,读多写少的场景。
查询效率高,增加和删除效率较低,需要大量移动元素。
LinkedList类:适合数据频繁的添加和删除操作,写多读少的场景。
插入、删除元素效率高,遍历和随机访问效率低下。
④安全性
ArrayList 和 LinkedList 都不是线程安全的。
HashMap扩容机制

扩容问题:
1.首次无参初始化添加元素进行扩容,resize()—16
2.链表>=8 并且数组长度<64 扩容—2倍扩容
3.存放的元素已经达到扩容阈值(加载因子*数组长度) — 2倍扩容

HashMap的put过程

HashMap put过程
初始化
HashMap有4个构造器,其他构造器如果用户没有传入initialCapacity 和loadFactor这两个参数,会使用默认值一般如果new HashMap() 不传值,默认大小是16,负载因子是0.75, 如果自己传入初始大小k,初始化大小为 大于k的 2的整数次方,例如如果传10,大小为16。
put()过程
判断数组是否为空,为空进行初始化;
不为空,计算 key的 hash 值,通过(n - 1) & hash(记不住就直接说哈希算法)计算应当存放在数组中的下标 index;查看 table[index] 是否存在数据,没有数据就构造一个Node节点存放在 table[index] 中;存在数据,说明发生了hash冲突(存在两个节点key的hash值一样), 继续判断key是否相等,相等,用新的value替换原数据(onlyIfAbsent为false);
如果不相等,判断当前节点类型是不是树型节点,如果是树型节点,创造树型节点插入红黑树中;(如果当前节点是树型节点证明当前已经是红黑树了)
如果不是树型节点,创建普通Node加入链表中;判断链表长度是否大于 8并且数组长度大于64, 大于的话链表转换为红黑树;
插入完成之后判断当前节点数是否大于阈值,如果大于开始扩容为原数组的2倍。
HashMap的底层原理分析
- 关键成员变量/常量:
(1)Node<k,v>[] table:HashMap底层存储数组
(2)Float loadfactor :加载因子,无参初始化时为默认加载因子
(3)Int threshold:扩容阈值,一般为table数组的长度*加载因子(0.75)
(4)Int Size:集合的长度(kv键值对的个数)
(5) final int DEFAULT_INITIAL_CAPACITY = 1 << 4; 默认数组长度16
(6)final int MAXIMUM_CAPACITY* = 1 << 30;最大数组长度
(7)final float DEFAULT_LOAD_FACTOR = 0.75f;默认加载因子
(8)final int TREEIFY_THRESHOLD = 8;转树形时链表的最小长度
(9)final int MIN_TREEIFY_CAPACITY = 64;转树形时数组的最小长度
- put元素时底层原理:
(1)通过扰动函数计算所存放元素中key的hash值


(2)添加元素前判断之前的数组table是否为空,如果是,则进行扩容

具体扩容原理如下:

扩容后:table数组长度由开始的0,变成16,扩容阈值从0变成了12
(3)通过table数组长度-1&hash的方法,确定要添加元素所存放的位置,并判断此位置是否已有元素,如果没有则可直接存放

(4)如果此位置已经有元素,通过hash和equals判断要添加元素的key值和已经在此位置元素的key值是否相同,如果key值不同,则对原位置元素的value进行覆盖

(5)如果key值相同,则说明发生了hash冲突,此时将要添加的元素以node节点的形式连到原位置元素的后面,先判断是否为树形节点,如果不是则按单向链表的形式进行连接

(6)后续添加元素,如果仍然在此位置发生哈希冲突,就继续往最后添加的元素后面连接,用p.next==null判断,在此过程中重复(4)的过此,即判断后续添加的元素与前面的元素的key值是否相同,相同则覆盖原元素的value,不相同则进行连接
(7)如果同一个位置的连接的元素超过8个,同时table数组的长度小于64,则需进行扩容,当同一个位置的连接的元素超过8个同时数组长度超过64,则改为红黑树的形式连接要添加的元素


此时的扩容机制为数组长度按两倍扩容,扩容阈值也按两倍扩容

(8)还有一种情况也需要扩容,即数组中的元素个数大于扩容阈值,此时会进行扩容

此时的扩容机制和上面相同,即数组长度和扩容阈值都按两倍扩容!
总结:
1.使用hash计算元素存储到数组的位置i = (n-1)&hash,如果此位置没有元素,直接存储
2.如果当前的存储位置有元素,并且key地址相等,或者key的内容相同--》key同,则覆盖value
3.如果当前存储的位置有元素,并且key不相同,产生hash冲突
way1:判断是否为树形节点,如果是树形节点,采用树形创建方式,将元素进行添加
way2:不是树形节点,则是链表: p.next == null 放新的元素(判断每个节点是否和新增的节点的key是否相同)
链表>=8 并且数组长度<64 扩容
链表>8 并且数组长度>64 转树形节点