IoTDB 监控工具:有效保障读写数据量与系统效率!
磁盘 I/O 负载过高的原因是什么?如何排查?
如何判断磁盘 I/O 是否成为系统瓶颈?
如何优化磁盘 I/O 读写性能?
在现代计算机系统和应用程序中,磁盘 I/O 性能是决定整体系统表现的关键因素之一。无论是数据库、文件服务器,还是各种应用程序,都依赖高效的磁盘 I/O 操作来确保数据的读写和处理速度。
本文将详细介绍 IoTDB 对磁盘 I/O 的完整监控机制,以及如何识别磁盘瓶颈并优化磁盘 I/O 性能。
01 磁盘 IO 如何观测?
(1)核心指标
在深入探讨磁盘 I/O 监控方法之前,我们首先需要了解一些核心性能指标,这些指标为分析监控结果提供了坚实的基础。常见的指标包括:
-
I/O 读写延迟:从发起 I/O 请求到接收响应之间的时间间隔。
-
IOPS:每秒处理的 I/O 请求数量。
-
吞吐量:每秒完成 I/O 操作的数据量。
-
使用率:磁盘处理 I/O 操作的时间比例。
-
饱和度:描述了磁盘处理 I/O 操作时的繁忙程度。
通过理解这些指标,使用者可以更好地监控和优化系统的磁盘 I/O 性能,确保系统在高效的状态下运行。
(2)常用工具
了解了磁盘 I/O 的基础性能指标后,让我们进一步探讨 Linux 操作系统中可用的监控工具。iostat 是一款广泛应用的工具,它能够提供详尽的磁盘 I/O 性能数据,包括磁盘使用率、IOPS、吞吐量等关键指标。这些数据来源于系统内核中的 /proc/diskstats 文件,该文件记录了磁盘的实时统计信息。
通过命令 iostat -dx 1,可以实时查看所有磁盘的 I/O 性能指标,并且每秒刷新一次数据,为用户提供连续的性能监控视图。如果需要深入了解 iostat 的用法和各项指标的含义,可以查阅其 man 手册,其中包含了详细的命令参数说明和使用示例,帮助用户根据具体需求定制监控方案。

在 iostat 显示的指标中,以下几项较为重要:

除了 iostat 之外,Linux 系统中还可以使用 iotop 和 pidstat 等工具来监控进程的 I/O 活动。
02 如何高效监控 IoTDB 的磁盘 IO?
(1)概述
IoTDB 为用户提供了全面的磁盘 IO 监控方案。通过自带的监控框架定期采集系统 I/O 性能指标,将其存入 Prometheus,并在上层支持监控指标与可视化工具 Grafana 的打通,最终达到系统指标全面监控、直观展示的效果,为用户提供更加全面的磁盘 I/O 可观测性。
与上述传统的监控工具相比,IoTDB 内置磁盘 IO 监控有以下优势:
-
更长周期的数据记录与趋势跟踪能力:虽然 iostat、iotop 等工具能够实时监控磁盘 I/O,但它们通常缺乏长期的数据记录与趋势分析功能。IoTDB 监控框架通过定期采集系统 I/O 性能指标并将其存入 Prometheus,从而使用户能够回溯历史数据,进行趋势分析与异常检测。
-
更丰富的 IO 观测指标:IoTDB 利用 /proc/[PID]/io 文件获取了进程级别的 I/O 信息,提供了更丰富的 IO 可观测性指标。这意味着 IoTDB 的磁盘监控方案不仅包含历史数据的存储,还在观测范围上超越了传统的 iostat 工具。
-
更友好的监控可视化:IoTDB 通过与可视化工具 Grafana 结合,将磁盘 I/O 数据以图表形式直观地展示给用户。这不仅提高了数据的可读性,还帮助用户快速识别性能瓶颈和优化方向(通过自带的采集 IO 指标,用户可以使用 Prometheus 进行拉取并在 Grafana 进行展示,也可使用企业版获取全套开箱即用监控方案)
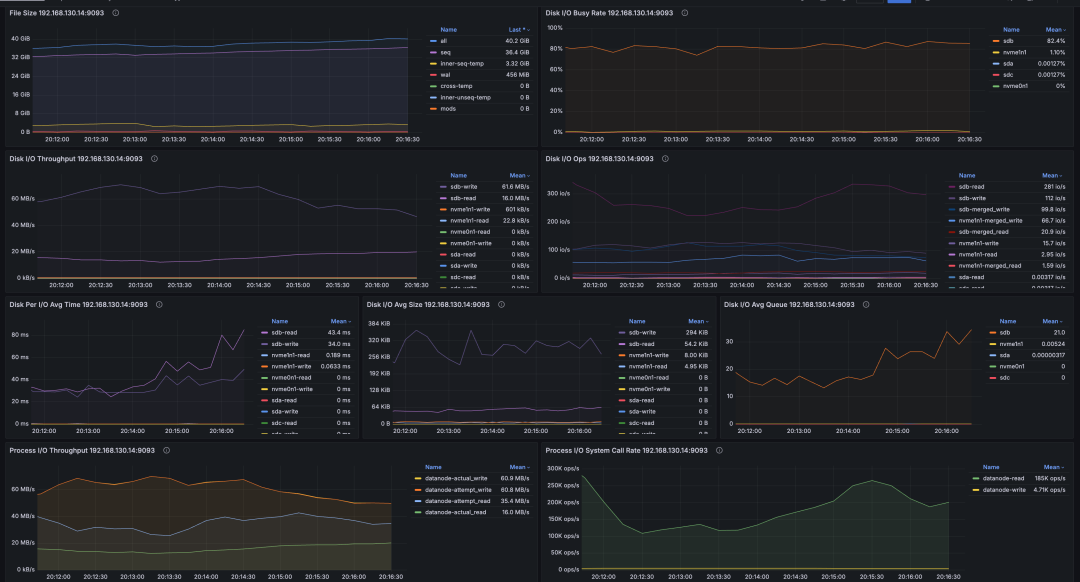
(2)IO核心监控指标详解
吞吐量
该指标衡量了节点中所有磁盘在单位时间内的读写数据量。
通常情况下,HDD 的顺序读写吞吐量约为 50-500MB/s,而 SSD 则可达到 200-5000MB/s。不论是 HDD 还是 SSD,随机读写的吞吐量通常显著低于顺序读写。用户可以参考磁盘厂商提供的理论吞吐量指标,或使用 fio 等工具测试磁盘的实际吞吐量,这些数据可以作为判断磁盘吞吐量是否达到瓶颈的重要依据。
当监控数据显示磁盘吞吐量接近其理论或实测性能上限时,通常意味着磁盘吞吐量可能成为系统性能的瓶颈。在这种情况下,系统管理员可能需要采取一系列措施,如增加存储设备的并行度或升级到更高效的存储接口,调整数据访问模式或采用压缩比更高但 CPU 占用较多的压缩算法,以缓解 I/O 吞吐量瓶颈,确保系统的稳定运行。
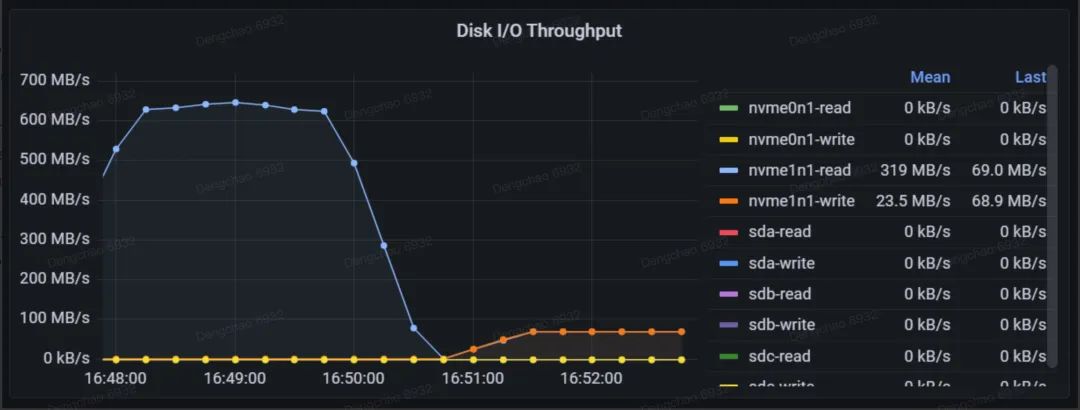
IOPS
全称为 "Input/Output Operations Per Second"(IOPS),该指标衡量了节点中所有磁盘在单位时间内执行的读写 I/O 请求数量。
由于块设备通常配备有智能调度算法,这些算法可以在特定场景下优化 I/O 请求处理。"合并读"(merged-read)和"合并写"(merged-write)描述的正是这种优化过程中,将多个相邻的 I/O 请求合并为一次操作的情况和次数。这种合并操作能够减少磁盘的机械运动,特别是在处理大量小规模 I/O 请求时,显著提高整体性能。
对于该指标,有以下几点需要注意:
-
MergeRead 和 MergeWrite 通常发生在顺序读写时,而在随机读写场景下,由于数据分布较广,合并操作较少。合并操作可以提高 I/O 性能,这不仅与应用的 I/O 模式有关,也依赖于操作系统的 I/O Scheduler。如果调度器设置为 None,则不会进行合并操作。调整 I/O Scheduler 也可作为 I/O 调优的手段。
-
对于 SSD,即使在顺序读写时也不会发生合并操作,因为 SSD 的最小读写单位是 Page(通常为 4K 或 8K)。因此,Linux 对 SSD 的 I/O Scheduler 通常只使用 None 或 Noop。
无论是 HDD 还是 SSD,随机读写的性能都显著低于顺序读写。此外,IOPS 的性能上限与 I/O 请求的大小密切相关。通过观察 MergeRead 和 MergeWrite 的频率,可以评估系统当前的 I/O 模式是以顺序 I/O 为主,还是随机 I/O 为主,进而为进一步性能优化提供参考。
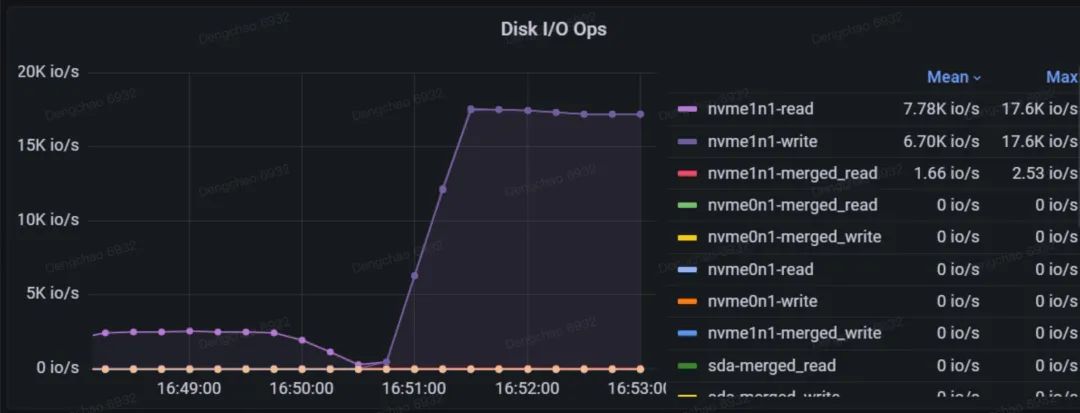
繁忙率
该指标记录了磁盘在每个时刻的繁忙程度,类似于 iostat 工具中的 %util 指标。右侧不同颜色的矩形块代表不同的磁盘,其中前缀 "nvme" 表示这些磁盘使用了 NVMe(非易失性内存快速存储)技术。"Mean" 和 "Last" 分别表示平均 I/O 繁忙比例和最近一次的 I/O 繁忙比例。
一个常见的误解是,当 DiskBusyRate 达到 100% 时,人们可能会认为磁盘已经饱和,性能无法进一步提升。然而,DiskBusyRate 的计算依赖于 /proc/diskstats 文件中的 io_ticks 字段,该字段记录了 I/O 队列中有请求的时间,但并不反映队列的长度。现代磁盘通常能够同时处理多个并发的 I/O 请求,因此,即使 DiskBusyRate 达到 100%,磁盘 I/O 性能仍可能有提升空间。
例如,如果每个请求需要 100 毫秒完成,而磁盘可以并发处理 10 个 I/O 请求,那么理论上磁盘在 1 秒内可以处理 100 个 I/O 请求。如果每 100 毫秒发出一个 I/O 请求,Disk IO Time 将等于 Total Time,但每秒实际处理的 I/O 次数只有 10 次,与 100 IO/s 的理论上限相比,仍有很大差距。
因此,当 DiskBusyRate 达到 100% 时,并不一定意味着磁盘性能已达到极限。我们需要结合磁盘队列长度,吞吐量和 IOPS 等性能指标进行综合判断,以更准确地评估磁盘的实际性能状况,避免过早得出磁盘性能饱和的结论。
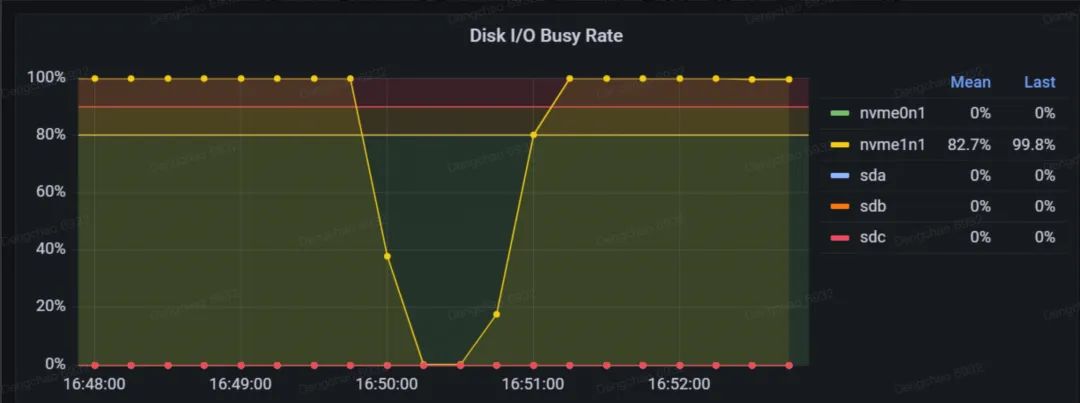
磁盘队列长度
该指标等同于 iostat 中的 avgqu-sz,即 I/O 请求队列的平均长度。通常情况下,I/O 请求队列越大,意味着 I/O 负载越繁忙。这个指标也与磁盘的 I/O 模式有关。如果相同数量的 I/O 请求以并发形式涌入请求队列,Avg Queue Size 会更大;而如果请求依次进入队列,Avg Queue Size 会相对较小。
当 DiskBusyRate 达到 100% 时,可以结合 Avg Queue Size 来更准确地判断磁盘是否真的达到了性能极限。
-
如果 Avg Queue Size 较小(例如持续在个位数范围内波动),则表明磁盘仍有一定的性能余地。
-
如果 Avg Queue Size 较大(例如在两位数范围内波动),则表明磁盘的剩余性能已经接近耗尽,系统可能已经进入了瓶颈状态。
一般情况下,当 DiskBusyRate 接近 100% 且磁盘队列中排队任务较多时,通常表明磁盘的吞吐量或 IOPS 已经达到了瓶颈。此时,可以结合吞吐量和 IOPS 等监控面板的数据,进一步评估具体是哪方面出现了瓶颈,从而根据实际负载对 IoTDB 进行有针对性的调优。例如,吞吐量达到瓶颈时可能需要减少批处理大小,而 IOPS 到达瓶颈时可能需要增加批处理大小。通过这种综合评估方法,可以更准确地识别性能问题,确保系统始终处于高效运行状态。
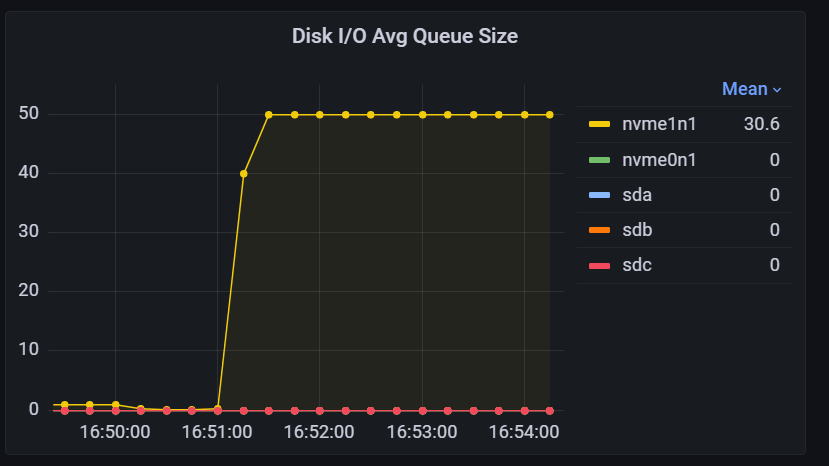
进程 I/O 系统调用频率
该指标表示进程调用读写系统调用的频率,类似于 IOPS。由于操作系统中存在文件系统和页面缓存(Page Cache),进程发起的系统调用不一定会立即触发实际的 I/O 操作,因此 I/O System Call Rate 通常高于磁盘的实际 IOPS。虽然该指标的绝对值可能难以直接解读,但通过观察其历史数据波动,可以帮助分析 IoTDB 的 I/O 模式是否发生了变化,例如读写比例等方面的变化。
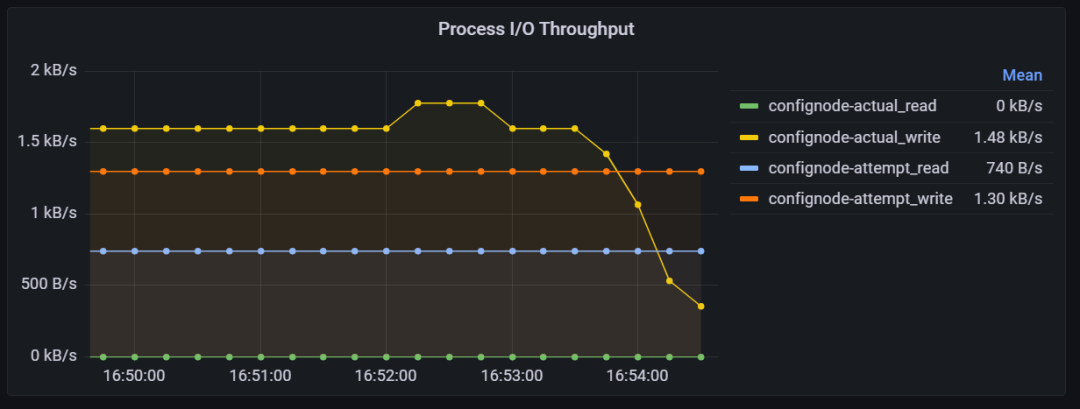
进程 I/O 吞吐量
该指标表示进程进行 I/O 的吞吐量,分为 actual_read/write 和 attempt_read/write 两类:
-
attempt read 和 attempt write 指的是进程尝试读取或写入的字节数,其中部分数据可能会被页面缓存(Page Cache)处理。
-
actual read 和 actual write 指的是进程实际触发块设备 I/O 的字节数,不包含被页面缓存处理的部分。
Actual read/write 与 Attempt read/write 之间的差异可以反映出当前 I/O 是否充分利用了页面缓存等缓存机制。如果差异较大,说明缓存机制有效地减少了直接与磁盘交互的 I/O 量。
03 总结
本篇文章深入探讨了 IoTDB 在磁盘 I/O 监控方面的独特优势。与 iostat 相比,IoTDB 不仅提供了更全面的进程级 I/O 指标,还实现了 I/O 监控数据的持久化存储,并通过 Grafana 进行可视化展示。这为用户评估 I/O 资源是否达到系统瓶颈,以及如何进行优化,提供了宝贵的参考依据。了解更多详情,请戳天谋科技官网-监控工具查看官方使用文档!
至此,IoTDB 与磁盘 I/O 监控的故事就告一段落了,读者们是否还有其他监控的故事想听呢?欢迎留言交流!
规上企业应用实例
能源电力:中核武汉|国网信通产业集团|华润电力|大唐先一|上海电气国轩|清安储能|某储能厂商|太极股份|绍兴安瑞思
航天航空:中航机载共性|北邮一号卫星
钢铁冶炼:宝武钢铁|中冶赛迪
交通运输:中车四方|长安汽车|城建智控|德国铁路
智慧工厂与物联:PCB 龙头企业|博世力士乐|德国宝马|京东|昆仑数据|怡养科技





![[000-002-01].第26节:MySQL对隔离级别的实现](https://i-blog.csdnimg.cn/direct/307515741a674f6cac48179416a80077.png)