目录
一、卷积神经网络的发展历程
二、简要介绍
三、代码实现
四、缺点和过时的地方
一、卷积神经网络的发展历程
- 早期理论基础阶段(20 世纪 60 年代 - 80 年代):
- 1968 年,Hubel 和 Wiesel 通过对猫视觉神经的研究,发现了视觉神经元对图像边缘的响应特性,提出了感受野的概念,为卷积神经网络的发展奠定了生物学基础 3。
- 1980 年,日本科学家福岛邦彦提出了 Neocognitron,它模拟了脑神经科学的结构,具备现代 CNN 的一些基本元素,如逐步的滤波器、使用 ReLU 提供非线性、平均池化下采样等,保证了网络的平移不变性,实现了稀疏交互,但无法进行有监督学习。
- 初步发展阶段(20 世纪 90 年代):
- 1990 年,Yann LeCun 将反向传播算法应用到类似 Neocognitron 的网络上,实现了一个用于手写数字识别的神经网络,简化了卷积操作以便于反向传播的应用,这是 CNN 用于有监督学习的早期重要实践。
- 1998 年,Yann LeCun 提出 LeNet - 5,这是具有里程碑意义的 CNN 架构。LeNet - 5 定义了 CNN 的基本框架,包括卷积层、池化层和全连接层,在手写数字识别任务上取得了良好效果。不过,当时受限于计算机算力和数据量,其应用范围相对有限。
- 沉寂阶段(2000 年 - 2011 年):这一时期,由于计算资源有限、数据集规模较小以及其他机器学习方法(如支持向量机)的竞争等原因,卷积神经网络的发展相对缓慢,处于沉寂状态。
- 复兴与突破阶段(2012 年 - 至今):
- 2012 年,AlexNet 诞生。它在当年的 ImageNet 大规模视觉识别挑战赛中以显著优势夺冠,标志着神经网络的复苏和深度学习的崛起。AlexNet 采用了更深的网络结构,使用 ReLU 激活函数、数据增强、mini - batch SGD 优化、在 GPU 上训练以及 Dropout 技术来避免过拟合等创新方法,极大地推动了 CNN 的发展,也让更多研究者关注到深度学习的潜力 。
- 2014 年,VGGNet 被提出,它通过增加网络深度(如 VGG - 16、VGG - 19),证明了增加网络深度可以提升模型性能,为后续研究提供了思路。
- 2015 年,ResNet 出现,它通过引入残差结构,有效解决了随着网络深度增加而导致的梯度消失问题,使得训练更深的网络成为可能,并且第一个在 ImageNet 图片分类上表现超过人类水准,将 CNN 的性能推向新高度。此后,各种基于 ResNet 的改进和衍生模型不断涌现。
- 2017 年,SENet 提出,通过引入注意力机制,让网络能够自适应地关注重要特征,进一步提升了模型的性能和表达能力。
- 近年来,CNN 不断与其他技术融合,如与生成对抗网络(GAN)结合用于图像生成、与强化学习结合用于智能决策等,同时在自动驾驶、医疗影像分析、智能安防等众多领域得到广泛应用,且随着硬件计算能力的持续提升和大规模数据集的不断丰富,其性能和应用场景还在不断拓展和深化。
二、简要介绍
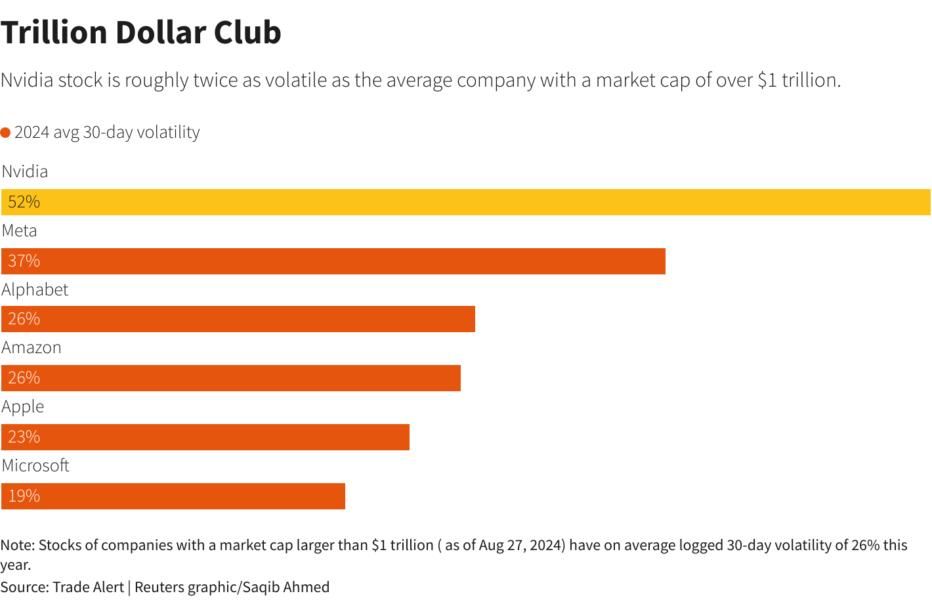
AlexNet 是一种深度卷积神经网络,在 2012 年的 ImageNet 大规模视觉识别挑战赛(ILSVRC)中取得了突破性的成果。
1. 网络结构

AlexNet 包含 8 层,其中前 5 层为卷积层,后 3 层为全连接层。具体结构如下:
- 第一层:卷积层,使用 96 个大小为 11×11×3 的卷积核,步长为 4。
- 第二层:最大池化层,池化窗口大小为 3×3,步长为 2。
- 第三层:卷积层,使用 256 个大小为 5×5 的卷积核。
- 第四层:最大池化层,池化窗口大小为 3×3,步长为 2。
- 第五层:卷积层,使用 384 个大小为 3×3 的卷积核。
- 第六层:卷积层,使用 384 个大小为 3×3 的卷积核。
- 第七层:卷积层,使用 256 个大小为 3×3 的卷积核。
- 第八层:全连接层,包含 4096 个神经元。最后两层全连接层也分别有 4096 个神经元,输出层则根据具体任务确定神经元数量。
2. 特点
非线性激活函数
使用 ReLU(Rectified Linear Unit)作为激活函数,相比传统的 sigmoid 和 tanh 函数,ReLU 能够加速训练过程,并且在一定程度上缓解了梯度消失问题。数据增强
通过对图像进行随机裁剪、水平翻转等操作,增加了数据的多样性,提高了模型的泛化能力。Dropout
在训练过程中随机将一些神经元的输出置为 0,有效地减少了过拟合。多 GPU 训练
由于网络规模较大,训练数据也很多,AlexNet 采用了多 GPU 并行训练的方式,加快了训练速度。
3. 影响
AlexNet 的出现极大地推动了深度学习在计算机视觉领域的发展。它证明了深度神经网络在图像识别等任务上的强大能力,为后续的研究提供了重要的参考和启示。此后,各种深度神经网络架构不断涌现,性能也不断提升。总之,AlexNet 是深度学习发展历程中的一个重要里程碑,它的创新之处和优异性能对计算机视觉领域产生了深远的影响。
三、代码实现
AlexNet 网络特点 它在多方面使用了创新性的结构 ; (1)提出了 非饱和神经元 ReLU 减小 梯度下降 的训练时间; (2)提用了 多GPU并行卷积操作 实现模型训练 加速 ; (3)提用了 LRN(Local Response Normalization) 实现局部响应 归一化 ; (4)提出了 Overlapping Pooling 使用 stride=2,kernal_size=3 使池化重叠,优于之前的 stride=2,kernal_size=2 ; (5)引入了 dropout 正则化方法减少 全连接层中的 过拟合 ; (6)此外,还采用 数据增强 的方法扩充数据集用以减小 过拟合 线性; 论文中 数据增强 采用的方式 :1、图像的平移和水平旋转;2、改变图像RGB通道的强度;
实现代码:
import torch
import torch.nn as nn
from torchinfo import summary
# 定义 AlexNet 类,继承自 nn.Module
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
# 调用父类的初始化方法
super(AlexNet, self).__init__()
# 定义特征提取部分的网络结构
self.features = nn.Sequential(
# 第一个卷积层,输入通道数为 3(彩色图像),输出通道数为 48,卷积核大小为 11x11,步长为 4,填充为 2
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2),
# 使用 ReLU 激活函数,inplace=True 表示在原张量上进行操作,节省内存
nn.ReLU(inplace=True),
# 第一个最大池化层,池化核大小为 3x3,步长为 2
nn.MaxPool2d(kernel_size=3, stride=2),
# 第二个卷积层,输入通道数为 48,输出通道数为 128,卷积核大小为 5x5,填充为 2
nn.Conv2d(48, 128, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
# 第二个最大池化层,池化核大小为 3x3,步长为 2
nn.MaxPool2d(kernel_size=3, stride=2),
# 第三个卷积层,输入通道数为 128,输出通道数为 192,卷积核大小为 3x3,填充为 1
nn.Conv2d(128, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# 第四个卷积层,输入通道数为 192,输出通道数为 192,卷积核大小为 3x3,填充为 1
nn.Conv2d(192, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# 第五个卷积层,输入通道数为 192,输出通道数为 128,卷积核大小为 3x3,填充为 1
nn.Conv2d(192, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# 第三个最大池化层,池化核大小为 3x3,步长为 2
nn.MaxPool2d(kernel_size=3, stride=2),
)
# 定义分类器部分的网络结构
self.classifier = nn.Sequential(
# 第一个全连接层,输入维度为 128*6*6,输出维度为 2048
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
# Dropout 层,用于防止过拟合
nn.Dropout(),
# 第二个全连接层,输入维度为 2048,输出维度为 2048
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
# 第三个全连接层,输入维度为 2048,输出维度为 num_classes(分类的类别数)
nn.Linear(2048, num_classes),
)
def forward(self, x):
# 前向传播过程,将输入 x 通过特征提取部分
x = self.features(x)
# 将特征图展平为一维向量
x = torch.flatten(x, 1)
# 将展平后的向量通过分类器部分得到输出
out = self.classifier(x)
return out
# 定义测试函数
def test():
# 创建一个 AlexNet 实例
net = AlexNet()
# 生成一个随机输入张量,形状为 (1, 3, 224, 224),表示一个批量大小为 1 的彩色图像,尺寸为 224x224
y = net(torch.randn(1, 3, 224, 224))
# 打印输出张量的大小
print(y.size())
# 使用 torchinfo 库的 summary 函数打印网络结构和参数信息
summary(net, (1, 3, 224, 224))
# 如果当前文件作为主程序运行
if __name__ == '__main__':
# 调用测试函数
test()输出:


四、缺点和过时的地方
- 缺点:
- 计算资源需求大:AlexNet 包含大量的参数,例如中间两个全连接层有很大的 4096 个神经元,这导致计算量庞大,对硬件要求非常高,需要大量的训练数据和计算资源,在训练和部署时成本较高。
- 过拟合风险:尽管使用了一些方法如 Dropout 来减少过拟合,但在某些情况下仍可能存在过拟合问题。例如在数据量不够丰富或模型复杂度相对数据规模过高时,容易出现对训练数据过度拟合,而对新数据的泛化能力不足。
- 缺乏对多尺度特征的有效融合:主要依赖固定大小的卷积核和池化操作来提取特征,对于不同尺度的物体,可能不能很好地自适应地提取到最有效的特征,在处理多尺度目标方面的能力相对有限。
- 过时的地方:
- 网络结构设计:随着技术发展,后续出现了许多更高效、更精巧的网络结构。比如 VGGNet 通过重复使用简单的卷积层堆叠,构建了更深层且性能更优的网络;GoogleNet/Inception 引入了 Inception 模块,通过不同尺寸的卷积和池化层并行处理,提高了计算效率和准确率;ResNet 引入了残差学习框架,解决了深层网络训练困难的问题,能构建极深的网络并取得更好的性能等。相比之下,AlexNet 的结构设计显得相对简单和基础 1。
- 激活函数:虽然 AlexNet 使用 ReLU 激活函数在当时是一个重要创新,解决了传统激活函数(如 Sigmoid 和 Tanh)在训练时的梯度消失问题,加快了训练速度。但后续又出现了如 Leaky ReLU、PReLU、ELU 等改进的激活函数,它们在某些方面能更好地处理负值或解决神经元 “死亡” 问题,进一步提升了网络的性能和稳定性。
- 训练方法和优化技术:在训练过程中,AlexNet 使用的随机梯度下降(SGD)及其一些基本的优化策略,在当下看来也较为简单。现在有许多更先进的优化算法,如 Adagrad、Adadelta、RMSProp、Adam 等,它们能够自适应地调整学习率,更好地处理复杂的损失函数曲面,加快收敛速度并提高训练效果。
- 缺乏对硬件的进一步优化:如今的硬件平台(如 GPU、TPU 等)不断发展,新的神经网络架构设计会更充分地考虑如何与硬件特性相结合,以实现更高效的计算和推理。而 AlexNet 在设计时主要基于当时的硬件条件,没有充分利用后续硬件发展带来的新特性和优势进行针对性优化
参考:
http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
https://blog.csdn.net/weixin_45084253/article/details/124228396
https://www.cnblogs.com/VisionGo/p/17975756