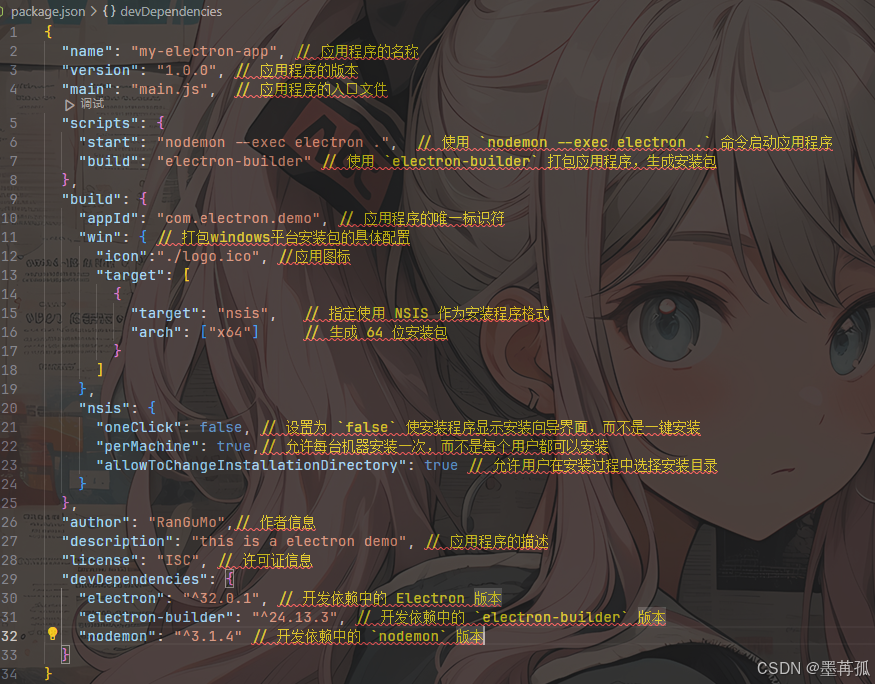
Graph analytics on AMD GPUs using Gunrock — ROCm Blogs

图和图分析是可以帮助我们理解复杂数据和关系的相关概念。在这种背景下,图是一种数学模型,用于表示实体(称为节点或顶点)及其连接(称为边或链接)。图分析是一种数据分析形式,它使用图结构和算法从数据中揭示见解。
图分析可以用于各种目的,例如社交网络分析、欺诈检测、供应链优化和搜索引擎优化。图分析还可以帮助我们衡量实体及其关系的重要性、影响力、相似性和结构。
那么,AMD GPU 是否能帮助进行图分析操作呢?我们将展示一些案例,在这些案例中,GPU 可以显著提升这些宝贵算法的性能。

图1:“切萨皮克”数据集的可视化,该图包含34个节点和340条边。
图算法的世界
既然我们已经知道图是非常出色的工具,那么我们如何分析这些复杂的数据和关系,从中找出有用的信息呢?这就是图算法派上用场的地方。图算法如同46种食谱,教我们如何从图中烹调出一些洞察。有许多类型的图算法可以做不同的事情,例如:
- 最短路径算法:这些算法帮助我们找到从一个节点到另一个节点的最快或最便宜的路径。
- 最小生成树算法:这些算法帮助我们找到连接图中所有节点且总权重最低的一组边。
- 最大流量算法:这些算法帮助我们找到网络中从源节点到汇节点可以发送的最大流量。
- 网络流算法:这些算法帮助我们在二分图中找到最佳的节点或资源匹配或指派方式。
- 连通性算法:这些算法帮助我们确定图中两个节点是否连接或可达,或者图中有多少个连通分量。
- 着色算法:这些算法帮助我们为图中的节点或边分配颜色,使得相邻的两个节点或边没有相同的颜色。
在本文中,我们将详细研究一种称为广度优先搜索(BFS)的搜索算法,通过这个案例研究学习更多关于图和图分析在GPU上的应用。

广度优先搜索,简介
广度优先搜索(BFS)是一种在树或图数据结构中搜索满足给定属性的节点的算法。
1. 它从根节点开始,探索所有相邻的节点。
2. 然后,它选择最近的节点,并探索所有未探索的节点。
3. 它通常使用队列数据结构来跟踪要访问的节点。
4. 它还标记每个节点是已探索还是未探索,以避免重复访问相同的节点。
5. BFS可以找到从根节点到图中任何其他节点的最短路径。

图 2:展示在图的不同层次上进行 BFS 迭代的可视化。
如何实现 BFS?
让我们首先从伪代码开始。下面的 BFS 伪代码通过将顶点放入队列 中,标记为“已访问”,并访问其所有邻居,以广度优先顺序访问图的所有顶点。每个访问过的顶点都会被标记为“已访问”,以避免再次处理同一顶点。这一过程会重复,直到所有顶点都被访问(并且队列为空)。非常简单!
BFS(graph, root):
create a queue Q
enqueue root onto Q
mark root as visited
while Q is not empty:
current_vertex = dequeue Q
for each neighbor of current_vertex:
if neighbor is not visited:
mark neighbor as visited
enqueue neighbor onto QBFS、图和梦想能实现什么?
BFS是一种用途广泛的算法,在不同领域有许多应用。它们包括:
- 在无权图中寻找最短路径和最小生成树,
- 在社交网络中从源节点找到给定距离内的所有节点,
- 通过探索所有可能的移动在游戏树中寻找最佳移动,
- 通过从源页面跟踪链接来抓取网页,
- 作为更复杂图算法的子程序!
在Python生态系统中,像NetworkX这样的框架提供了构建多种图应用的便捷接口。有关BFS算法,你可以查看NetworkX的Python实现 [这里](networkx/networkx/algorithms/traversal/breadth_first_search.py at main · networkx/networkx · GitHub)。既然我们已经定义了BFS算法的范围,让我们考虑在GPU上的实现。

我们可以做得更好:AMD GPU和Gunrock
在高性能计算(HPC)和人工智能中,广泛的应用已经通过GPU加速取得了显著成功。然而,将GPU应用于图分析问题仍然是一个显著挑战。虽然GPU在处理分散在单一指令集上的数据并行性(单指令多数据,即SIMD并行性)方面非常优秀,但图应用往往有多个分支条件和不规则的内存访问模式,这对GPU来说是一个严重的挑战。因此,GPU上的图应用通常会在GPU利用率和波前/波段之间的工作负载平衡方面表现不佳。如果这还不够的话,某些图算法需要线程之间昂贵的同步和通信,随着图的规模增加,这种情况会愈发严重。
图算法中不规则和不可预测的内存访问模式经常导致缓存未命中。由于共享内存和线程私有寄存器等快速芯片内存有限,为处理大图而适应所有必要数据是不切实际的,并且需要多次请求较慢的全局内存。这会产生延迟处罚,极大地超过GPU提供的高内存带宽,并大幅降低内核性能。为了解决这些挑战,图应用代码通常需要对计算内核进行复杂细致的修改以应对这些困难。
GPU加速的图分析变得简单且可编程
既然我们对GPU架构有了一个良好的了解,我们可以利用GPU内部的巨大并行性来进行图分析。具有数百万个或更多顶点和边的图非常适合现代GPU所提供的巨大并行性和内存带宽。研究人员提出了各种编程抽象,使实现图算法并全面思考并行图算法的过程变得更加容易。其中一些包括:块同步、异步、数据中心、基于稀疏线性代数等。
由于本文重点在BFS,我们强调在GPU上的并行广度优先搜索(BFS)是一个研究得很充分的主题,并且这些年来有了显著的进展。总结一些著名的工作:
- Harish和Narayanan提出了一种二次GPU BFS,将每个顶点的邻居列表映射到线程
- Hong等人通过使用虚拟波段改进了这一方法
- Merrill等人的自适应负载平衡的线性并行化产生了重大影响
- Beamer等人引入了一种混合BFS用于共享内存机器
- Enterprise优化了方向、负载平衡和状态检查
- BFS-4K改进了虚拟波段方法,使用动态并行性进行一个每迭代的动态分配,以改进负载平衡。
重要的是,大多数这些工作试图找到一种可能的方法,将BFS遍历中的可用计算并行化并负载平衡到GPU上。例如,一种可能的实现可以将所有活动顶点映射到单个线程,另一个则可以将所有活动边(或源、边、邻居元组)映射到单个线程。
Gunrock的图分析抽象
为了简化并行图算法(例如 BFS)的编程复杂性,我们可以借助 Gunrock 等框架来利用 GPU 的强大计算能力解决复杂的图算法。Gunrock 是一个基于 C++ 的 GPU 图库,它采用了“批同步”(bulk-synchronous)和数据中心的编程模型和抽象。简而言之,这意味着与其将图转化为稀疏矩阵并使用稀疏线性代数来实现图算法,不如直接将图视为由边连接的顶点集合(数据中心视角)。在特定迭代中,所谓的“活跃”顶点(或边)就是那些准备被处理的顶点(或边),这些活跃集合被称为边界(frontiers)。边界内的所有活跃顶点或边都使用 GPU 线程并行处理(批同步视角)。在每一步并行计算后,系统/GPU 同步,迭代这一过程,直到算法收敛。我总结了 Gunrock 编程模型中的几个关键点:
- 图算法通常被表示为迭代收敛过程。
- 边界是特定迭代中正在处理的一组活跃顶点或边。
- 并行操作符在 GPU 上处理这些边界。
- 我们可以将并行操作符串联起来,以创建复杂的图算法。
Gunrock 的文档中可以找到可用并行操作符及其描述(Gunrock Operators — Gunrock Documentation)。在此,我们将重点关注实现 BFS 所需的一个关键操作,称为 advance_。_advance 操作符简单地通过访问当前边界的邻居,生成新的边界(新的活跃顶点或边集合)。下图演示了 advance_,其中当前边界包含顶点 1 和 4,输出边界(经过 _advance 后)包含了顶点 1 和 4 的所有邻居。
我们的第一个并行广度优先搜索!
为了实现我们的第一个并行广度优先搜索,我们参考上述的顺序实现并认识到 BFS 是以迭代方式执行的。第一轮迭代的边界实际上包含了算法的起点(源点),然后“推进”(_advance_)到活跃顶点的所有邻居。在下一轮迭代中,这些邻居成为新的活跃边界,继续访问他们的所有邻居,直到遍历整个图。我们修改伪代码以展示这种并行 BFS 方法:
PARALLEL_BFS(graph, root):
create input frontier I
create output frontier O
add root onto I
mark root as visited
while I is not empty:
[parallel] for all vertices in I:
for each neighbor of source:
if neighbor is not visited:
mark neighbor as visited
add neighbor onto O
swap(O, I)并行和顺序方法的关键区别在于并行访问的[parallel] for,现在访问前沿中的所有顶点 I,并循环遍历每个顶点 I 的邻居,生成输出前沿 O。
最难的部分:负载均衡
图形算法通常固有地具有工作负载不平衡问题,其中处理不同源顶点的相邻并行线程(如上伪代码中的并行 for)可能需要处理不同数量的工作。例如,如果我们正在处理一个社交网络图;图中的顶点是“用户”,如果两个“用户”在该社交网络中互为“关注者”,则两者之间存在一条边。如果两个具有截然不同数目“关注者”的“用户”被分配给相邻的线程,而这些线程需要在我们之前定义的批同步编程模型结束时进行同步;那么处理关注者非常少的线程会等待那些具有大量关注者的线程处理完。这种问题称为负载不平衡问题,是在并行(特别是在使用SIMD/SIMT模型的GPU上)进行图分析时最难解决的问题之一。
幸运的是,Gunrock隐藏了负载均衡和其他在并行图分析中的复杂实现细节,并曝光了操作符级接口(如 advance 操作符)来表达图算法。我们可以在 AMD GPU 上运行它,看看与最常见的基于 Python 的 networkx 图库相比性能上的差异。
理解编程栈
如前一节所述,Gunrock 的编程栈遵循“关注点分离”理念,将其核心编程模型(如前述的批同步编程模型)与使图算法在 GPU 上高效运行所需的低级实现细节分开。换句话说,Gunrock 是用比硬编码实现更高层次的抽象编写的,充分利用其基本操作符的重用覆盖不同的图基元。使用 Gunrock 的应用程序可以直接在 C++ 级别进行接口,或者通过 Python 接口(这里不讨论)。Gunrock 支持的图基元的概述可以在此找到 这里。

从 Python 到 C++/HIP
下面的代码实现了高性能的 BFS(减去了样板代码),两个关键函数是设置阶段的 prepare_frontier 和循环阶段的 loop。
// Set-up the starting frontier.
void prepare_frontier(frontier_t* f,
gcuda::multi_context_t& context) override {
auto P = this->get_problem();
f->push_back(P->param.single_source);
}
// Execute this loop (on CPU) in a bulk-synchronous fashion
// till we have traversed the entire graph (output frontier is empty.)
void loop(gcuda::multi_context_t& context) override {
// User-provided root node to begin BFS.
auto single_source = P->param.single_source;
// Distances array to keep track of distances from root.
auto distances = P->result.distances;
// Visited array to mark vertices visited.
auto visited = P->visited.data().get();
// Define what should happen to each source, neighbor, edge and weight tuple
// on every step of the advance. This condition is applied in parallel.
auto search = [distances, single_source, iteration] __host__ __device__(
vertex_t const& source, // ... source
vertex_t const& neighbor, // neighbor
edge_t const& edge, // edge
weight_t const& weight // weight (tuple).
) -> bool {
// If the neighbor is not visited, update the distance. Returning false
// here means that the neighbor is not added to the output frontier, and
// instead an invalid vertex is added in its place. These invalides (-1 in
// most cases) can be removed using a filter operator or uniquify.
auto old_distance =
math::atomic::min(&distances[neighbor], iteration + 1);
return (iteration + 1 < old_distance);
};
// Launch advance operator on the above lambda function "search".
operators::advance::execute<operators::load_balance_t::block_mapped>(
G, E, search, context);
}开始在 AMD GPU 上使用 Gunrock
在构建 Gunrock 的 HIP 版本之前,请确保系统已正确安装 ROCm。任何高于 5 的版本都应该绰绰有余。我们建议读者参考博客文章 installing ROCm 来获得全面的概述。安装 ROCm 堆栈也将确保库依赖项(如 rocPRIM 和 rocThrust)可用,因为这些是构建 Gunrock 的 HIP 版本所需的框架。
除了安装 ROCm 之外,你还需要 CMake 3.20.1 或更高版本来进行配置和构建。一旦这些关键依赖项在系统上可用,你就可以开始了。这里的构建说明假设您使用的是 Linux 发行版,例如 Ubuntu。下面是一个克隆 Gunrock 仓库并为消费级显卡(如 Radeon 6800XT 或 6900XT)编译的示例。在我们的示例中,我们专门制作了一个可执行文件来运行 Gunrock 的 BFS 算法。
git clone -b hip-devel https://github.com/gunrock/gunrock.git
cd gunrock
mkdir build && cd build
cmake .. -DCMAKE_HIP_ARCHITECTURES=gfx1030 # change arch depending on the target device
make bfs # or for all algorithms, use: make -j$(nproc)Gunrock 附带了各种 graph datasets,可以开箱即用进行实验。要构建所有数据集,只需在 Gunrock 项目的 datasets 子目录中执行 make:
cd ../datasets
make数据集解压后,可以在 build/bin 子目录中运行 bfs 可执行文件并提供生成的 .mtx 数据文件:
cd ../build
bin/bfs ../datasets/chesapeake/chesapeake.mtx要获取 bfs 可执行文件的完整参数选项列表,只需运行 bin/bfs --help。
加速 BFS:NetworkX 与 Gunrock
NetworkX 是一个用于图分析的 Python 包,它易于安装、使用和实验。这是数据科学家在 Python 中使用的最受欢迎的图框架之一,并巧妙地利用了蓬勃发展的 Python 生态系统进行数值线性代数和数据可视化。然而,通过使用诸如 Gunrock 之类的框架在 GPU 上执行,即使是简单的图遍历算法(如 BFS),也常常会在处理较大图数据集时带来显著的性能提升。
为了说明使用 AMD GPUs 加速图工作负载的影响,我们对比了在各种数据集上使用 NetworkX(Python 实现)和 Gunrock(HIP 实现)执行 BFS 算法的性能。在 Gunrock 仓库 中可以找到此次对比使用的完整数据集列表。使用 Gunrock 收集的结果是在 ROCm 5.7.1 版本和 Radeon 6900XT 游戏 GPU 上运行得出的。NetworkX 的计算结果是在 AMD EPYC 7742 64 核处理器上获得的,但这些实验中并未利用并行化。
对于所有数据集,每次调用 BFS 时选择一个随机起始节点(在 NetworkX 和 Gunrock 结果中相同),并且时间取 25 次迭代的平均值。下表展示了选定数据集的结果。
| Dataset | Nodes | Edges | NetworkX (ms) | Gunrock (ms) |
|---|---|---|---|---|
| chesapeake | 39 | 340 | 0.097646 | 0.544522 |
| webbase-1M | 1,000,005 | 3,105,536 | 10,975.20 | 2.94 |
| hollywood-2009 | 1,139,905 | 113,891,327 | 64,862.21 | 9.93 |
| roadNet-CA | 1,971,281 | 5,533,214 | 21,996.39 | 41.28 |
| delaunay_n21 | 2,097,152 | 12,582,816 | 27,857.40 | 41.19 |
| kron_g500-logn21 | 2,097,152 | 182,082,942 | 166,905.78 | 22.45 |
| indochina-2004 | 7,414,866 | 194,109,311 | 146,979.89 | 1.17 |
| delaunay_n24 | 16,777,216 | 100,663,202 | 251,753.90 | 116.38 |
| road_usa | 23,947,347 | 57,708,624 | 309,478.87 | 328.47 |
表 1: 使用 NetworkX 和 Gunrock 在不同图数据集上完成 BFS 平均时间(毫秒)的比较。提供了数据集名称以及节点/边的数量。
观察到的加速在这种比较中是典型的,不应泛化到使用并行 CPU 实现的 BFS 框架中。对于小型数据集,例如 chesapeake 图,使用 GPU 没有真正的优势。然而,对于有数百万个节点和边的图数据集,性能差异非常显著,只需切换到 Gunrock 的 GPU 实现即可实现数个数量级的加速。

结论
图分析是复杂数据分析的重要工具,图在各种应用中无处不在。如果您是一名处理有趣的图问题和数据集的数据科学家,在本文中我们展示了使用 Gunrock 利用系统中的 AMD GPU,在通过并行图分析处理大型图时可以获得可观的性能提升。如果您有任何问题或意见,请在 GitHub 上的 Discussions 联系我们。