大模型分布式训练并行
一般有 tensor parallelism、pipeline parallelism、data parallelism 几种并行方式,分别在模型的层内、模型的层间、训练数据三个维度上对 GPU 进行划分。三个并行度乘起来,就是这个训练任务总的 GPU 数量。
1.数据并行
数据并行是最常见的并行形式,因为它很简单。在数据并行训练中,数据集被分割成几个碎片,每个碎片被分配到一个设备上。这相当于沿批次(Batch)维度对训练过程进行并行化。每个设备将持有一个完整的模型副本,并在分配的数据集碎片上进行训练。在反向传播之后,模型的梯度将会聚合(All Reduce),以便在不同设备上的模型参数能够保持同步。典型的数据并行实现:PyTorch DDP。每个 GPU 分别计算不同的输入数据,计算各自的梯度(也就是模型参数的改变量),再把梯度汇总起来,取个平均值,广播给各个 GPU 分别更新。

下面是一个使用PyTorch实现数据并行的简单示例。假设我们有一个简单的神经网络模型,并且我们有多个GPU可用。我们将展示如何使用torch.nn.DataParallel来实现数据并行。
首先,确保你安装了PyTorch,并且系统配置了至少两个GPU。
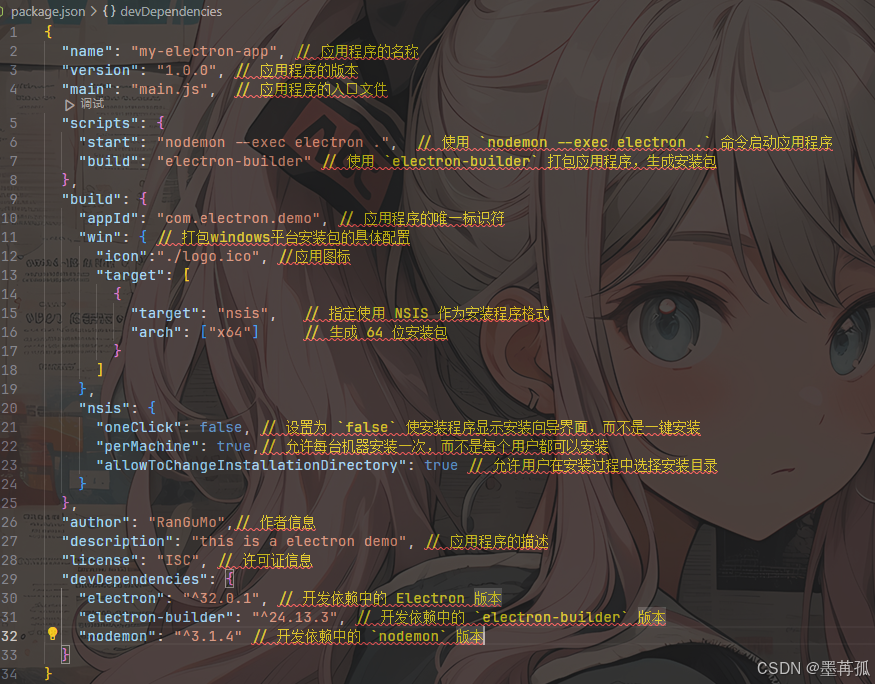
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import deepspeed
# 定义一个简单的模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(10, 5)
self.fc2 = nn.Linear(5, 2)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 创建模型实例
model = SimpleModel()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 创建一些随机数据作为示例
inputs = torch.randn(100, 10) # 假设输入数据是 100 个样本,每个样本有 10 个特征
labels = torch.randint(0, 2, (100,)) # 假设标签是二分类问题
# 创建数据加载器
dataset = TensorDataset(inputs, labels)
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)
# 配置 DeepSpeed
ds_config = {
"fp16": {
"enabled": True, # 启用 FP16 训练
"initial_scale_power": 8
},
"zero_optimization": {
# ZeRO 配置
"stage": 2, # 使用 ZeRO 第二阶段
"allgather_partitions": True,
"allgather_bucket_size": 5e8,
"reduce_scatter": True,
"reduce_bucket_size": 5e8
},
"gradient_accumulation_steps": 2, # 动态梯度累积步数
"steps_per_print": 2000, # 打印间隔
"wall_clock_breakdown": False # 是否显示每个操作的时间分解
}
# 初始化 DeepSpeed
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
optimizer=optimizer,
config=ds_config
)
# 训练模型
num_epochs = 5
for epoch in range(num_epochs)