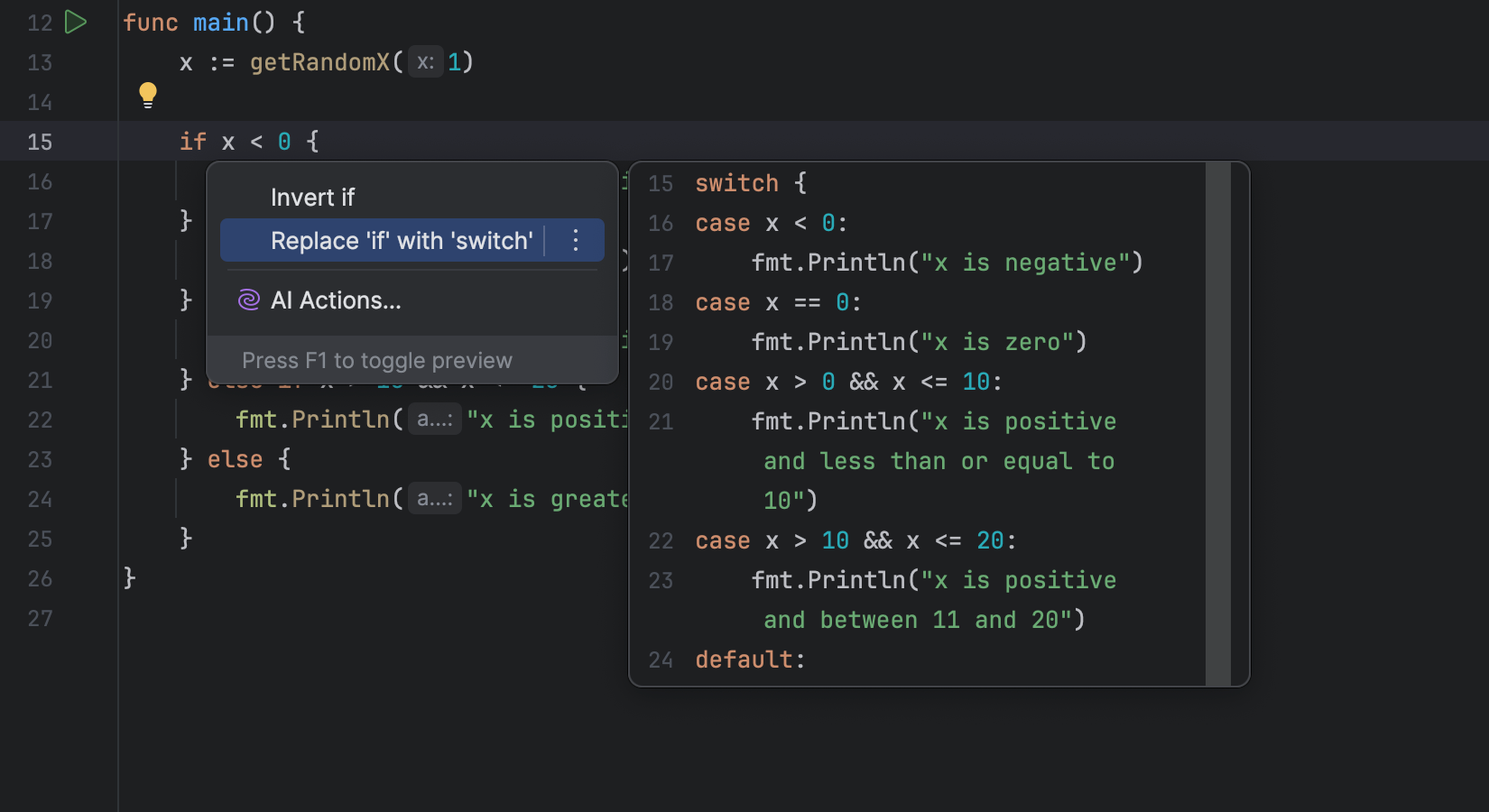
今天咱们来聊聊在 Python 中如何优雅地实现列表去重。
这是一个非常经典的问题,虽然很多人都会,但如何更优雅的实现呢?这里有不少有趣的解决方法。话不多说,咱们直奔主题。
方法一:用 set 去重
先来看个最简单的方法,用 set。set 是 Python 的一个数据类型,具有去重功能。代码非常简洁,直接一行就搞定了:

这段代码运行后会输出:
✨ 优点:简单高效,代码量少,性能好。
⚠️ 缺点:可能会改变原始数据的顺序。如果你对顺序很在意,那这个方法可能就不适合你了。
💡 小贴士:其实在大多数情况下,顺序不重要时,这个方法是非常实用的。如果要保留顺序,我们需要看其他方法。
方法二:用列表推导式
如果你希望保留原始数据的顺序,可以试试列表推导式。虽然代码稍长,但依然是可以在一行内实现的。

这段代码运行后会输出:

✨ 优点:保留了原始顺序。
⚠️ 缺点:效率较低,尤其是列表很大的时候,性能就不太理想了。因为每次都要检查 unique_list 是否已经包含该元素,时间复杂度是 O(n^2)。
💡 小贴士:在小数据集上这个方法还是不错的,代码也比较直观。
方法三:用 collections.Counter
如果你既想保留原始顺序,又想要高效的方法,collections.Counter 是个不错的选择。Counter 是 collections 模块里的一个类,用于计数,这里我们可以利用它的特性来实现去重。

这段代码运行后会输出:

✨ 优点:保留原始顺序,效率高,一行代码搞定。
⚠️ 缺点:需要引入 collections 模块,不过这个模块是标准库的一部分,所以不用担心额外安装问题。
💡 小贴士:这是个很优雅的方法,既考虑了效率又保留了顺序,推荐使用。
方法四:用 dict.fromkeys
其实,还有一种高效保留顺序的方法,就是利用 dict.fromkeys。Python 3.7+ 中,字典是有序的(Python 3.6 中的 CPython 实现也是有序的)。

这段代码运行后会输出:

✨ 优点:保留原始顺序,效率高。
⚠️ 缺点:可能不太直观,需要知道字典有序的特性。
💡 小贴士:这个方法的代码非常简洁,而且性能也很不错,特别是在 Python 3.7+ 的环境下。
方法五:用 pandas
如果你熟悉 pandas 库,并且已经在使用它进行数据处理,那你也可以用 pandas 来实现列表去重。pandas 的 unique 函数非常方便。

这段代码运行后会输出:

✨ 优点:保留原始顺序,代码简洁。
⚠️ 缺点:需要引入 pandas 库,适合已经在使用 pandas 的场景。
💡 小贴士:在处理大型数据集时,pandas 是个很强大的工具,值得学习和使用。
方法六:用 numpy
如果你在进行数值计算,可以用 numpy 来去重。numpy 的 unique 函数同样方便快捷。

这段代码运行后会输出:

✨ 优点:保留原始顺序,代码简洁,适合数值计算。
⚠️ 缺点:需要引入 numpy 库,适合已经在使用 numpy 的场景。
💡 小贴士:如果你从事科学计算或工程应用,numpy 是不可或缺的工具。
总结下来,不同的方法各有优劣。对于小数据集或不关心顺序的情况,用 set 最简单高效;如果需要保留顺序且数据量不大,列表推导式和 collections.Counter 是不错的选择;如果追求高效且保留顺序,dict.fromkeys 是个好选择;对于已经在使用 pandas 或 numpy 的场景,这两个库也提供了方便的方法。
希望这些方法能帮助你更好地处理列表去重的问题。