目录
- jieba 分词
- 本身特点
- 使用方法
- 输出结果
- RecursiveCharacterTextSplitter 分词
- 本身特点
- 使用方法
jieba 分词
jieba(中文名:结巴)是一个广泛使用的中文分词库,它支持三种分词模式:
- 精确模式:试图将句子最精确地切开,适合文本分析。
- 全模式:把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能保证每个词语的准确性。
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎的分词。
本身特点
- 支持繁体分词和简体分词。
- 支持自定义词典,可以提高分词的准确性。
- 支持词性标注。
- 可以进行关键词提取和词频统计。
使用方法
import jieba
text = "我爱北京天安门"
seg_list = jieba.cut(text)
print("Default Mode: " + "/ ".join(seg_list)) # 默认精确模式
print("Full Mode: " + "/ ".join(jieba.cut(text, cut_all=True))) # 全模式
print("Search Mode: " + "/ ".join(jieba.cut_for_search(text))) # 搜索引擎模式
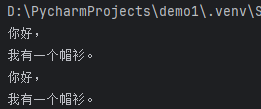
输出结果

RecursiveCharacterTextSplitter 分词
RecursiveCharacterTextSplitter 是 Langchain 中的一个文本分割工具,它基于字符递归地分割文本。这种分词方法不是基于词的边界,而是基于文本的字符长度进行分割。
本身特点
- 可以指定每个文本块的最大字符数。
- 可以指定文本块之间的重叠字符数,以保持上下文的连贯性。
- 通常用于生成适合深度学习模型输入的文本块。
使用方法
from langchain.text_splitters import RecursiveCharacterTextSplitter
# 省略其他【这个示例要是运行的话前期准备工作很复杂,包很难下载,这里只是展示它们的不同以及各自的输出结果】
# 获取对应语言风格的数据
metadata = [item for item in data if item.get("press") == type_all[get_type]]
contents = [item['content'] for item in metadata]
updated_metadata = [{key: dic[key] for key in dic if key != 'content'} for dic in metadata]
# 创建 Document 对象
document = [Document(page_content=content, metadata=meta) for content, meta in zip(contents, updated_metadata)]
# print(document)
# 切分文档
text_split = RecursiveCharacterTextSplitter(chunk_size=12, chunk_overlap = 4)
split_data = text_split.split_documents(document)# 切分数据
print(split_data)