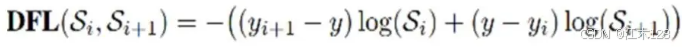作者 | 搜索架构部
导读
本文大语言模型在未经标注的大量文本上进行预训练后,可能产生包含偏见、泄露隐私甚至对人类构成威胁的内容。OpenAI 最先提出了基于人类反馈的强化学习算法(Reinforcement Learning fromHuman Feedback, RLHF),将人类偏好引入到大模型的对齐过程中,从而让大语言模型能够生成符合人类预期的输出。笔者长期在搜索领域应用大模型提升搜索质量,发现RLHF在搜索结果的相关性、准确性和无害性等方面均有显著的提升,同时也观察到由于RLHF 流程相比预训练以及SFT更加复杂,导致在训练效率上,其系统吞吐率远低于预训练或者SFT,这严重制约了 RLHF 的应用与发展。当前业界和学界在预训练阶段和推理部署阶段的性能优化进展非常丰富,但在强化学习尤其是RLHF性能优化的公开资料较少。我们注意到,RLHF 和预训练共享大多数分布式训练技术,因此在优化手段上,RLHF 既要吸收预训练的方法,也要结合自身的特点做针对性地优化。
RLHF 目前已经发展出多种算法,本文将谈一谈 RLHF 的性能优化问题,我们以PPO为例来讨论 RLHF 的性能优化。PPO 优化过程同预训练有显著不同,且较为复杂,因此比较适合用来讨论 RLHF 的性能优化。最近学术界也开始涌现出一批使用监督微调的对齐方式,从而简化对齐过程,如 DPO 算法等,但是其优化手段可被囊括在 PPO 优化手段之内。
我们的优化手段包括文本生成速度优化、动态显存优化、系统并行优化等。经过优化后,我们的方案能够保证效果的同时,大幅提升性能。我们也针对搜索业务场景需求对业界主流方案进行了对比测试,性能大幅优于其他方案。
01 PPO 算法流程
PPO 优化流程涉及四个不同的模型,分别是Actor、Critic、Reward和Reference,是一个典型的多角色多阶段的过程,大致流程如下
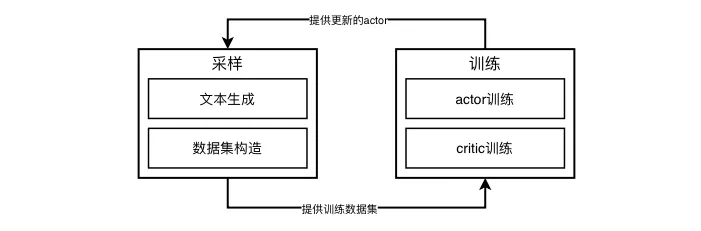
PPO的训练阶段同预训练几乎一样,都是先前向计算损失函数,而后进行反向传播。唯一不同的是PPO训练涉及两个模型。PPO的采样阶段是预训练没有的,采样阶段只有纯粹的前向推理计算,包括文本生成和奖励计算等。由于逐token生成的特性,文本生成的效率一直是业界关注的焦点,在PPO流程中更是超过训练时间而成为整个系统的瓶颈。
02 软硬件配置与基线吞吐率分析
为简化讨论,本文以下表中所列的软硬件配置为基准进行讨论。但是本文所提到的优化手段并不受限于下述条件。
2.1 基础配置

2.2 训练配置

其中:
-
prompt_length是prompt数据集的最大长度,prompt的长度分布应该较为均匀,其平均长度也应该接近这个值;
-
generate_lenght是生成文本的最大长度,当生成超过这个阈值时文本会被截断;
-
generate_batch_size是生成文本时的batch_size,这个值越大则GPU利用率越高,但同时会带来更高的显存占用;
-
global_batch_size和micro_batch_size最初由梯度累积概念引入,详情可在网上搜索,这里需要重点说明的是,micro_batch_size是决定系统吞吐率以及显存占用最关键的参数,global_batch_size理论上同系统吞吐率以及显存占用关系不大,也就是说可以无限制的扩大。但如果处理不好,梯度聚合过程也可能导致大量的显存消耗,从而导致global_batch_size无法连续调节,后面会有一个案例具体说明;
-
ppo_iter指的是ppo算法每轮在全量采样数据上迭代几次。
2.3 显存分配方式
全参微调条件下,至少需要1280G(2*8*80G)显存,典型的显存分配方式如下:
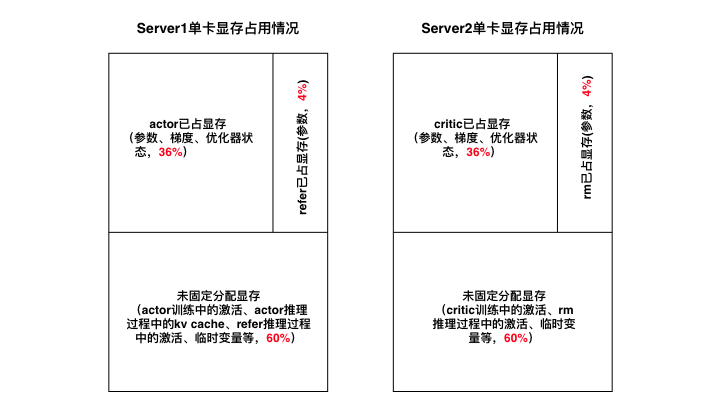
这种分配方式的好处如下:
-
计算负载均衡——除了文本生成阶段只有actor参与以外,其他时间两机的计算大致相同;
-
显存负载均衡;
-
actor和refer共享初始热启checkpoint、critic和reward共享初始checkpoint,每台机器只需存储一份热启checkpoint
2.4 系统关键部分耗时

2.5 吞吐率计算
系统各关键部分全部为串行执行,一次ppo迭代的耗时为: 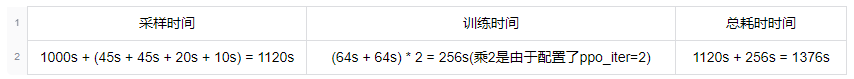
可以计算得到系统吞吐率为 256 sample / 1376 s / 16 gpu = 0.012 sample / gpu / s。
03 文本生成速度优化
文本生成大约占了百分之八十左右的耗时,根据阿姆达尔定律:
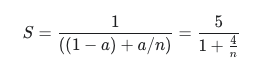
如果能够加速两倍,整个系统就能够取得接近1.67倍的提速,这是非常可观的。目前业界成熟的大模型应用范式是先在训练框架上进行模型训练,然后再使用专门的推理框架进行模型推理服务,推理加速往往是推理框架重点关注的问题。对于训练框架,一方面在功能上推理往往只起辅助作用,比如校验当前训练结果等,另一方面训练框架大多针对训练特性做优化,很难同时兼容推理的一些优化特性。因此,本项目中引入英伟达的TRT-LLM进行文本生成阶段的加速,不过在讨论TRT-LLM之前,先来探讨一下文本生成速度慢的一些可能原因。
3.1 文本生成速度慢可能的原因
1. 为避免重复计算,文本生成接口均采用kv cache机制,这种机制将文本生成切分成两个阶段,既context阶段和decode阶段。其中context阶段就是对prompt计算kv,因此该阶段也被称作prefill阶段。decode阶段则是逐token生成的过程,由于kv cache大大减少了计算量,该阶段变成访存密集型任务,GPU计算单元的利用率较低。且kv-cache需要额外消耗大量的显存,限制了batch_size的大小,这又进一步降低了GPU计算单元的利用率;
2. 无效生成——由于batch内prompt长短不齐,简单的文本生成策略会从最短的prompt长度位置开始,造成大量的无效生成。当batch内某个句子生成结束后,仍然会跟随batch内其他未结束的句子一起继续生成,又会造成大量的无效生成;
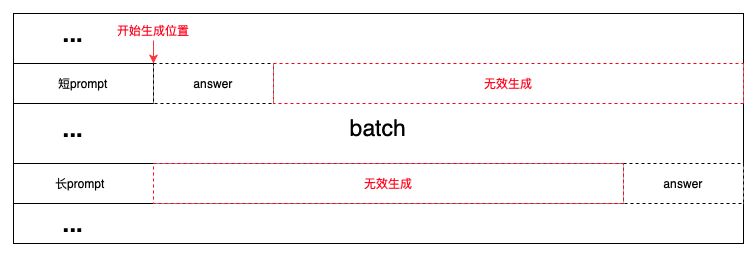
3. 大模型由于参数量过大,单显卡的显存往往无法匹配训练时的显存需求,类Megatron-LM的训练框架使用模型并行将显存需求分散到多张显卡。模型并行包括张量并行和流水并行两种机制,在推理时,这两种机制都会引入的额外通信开销。如果使用pp,还会引入空泡,导致生成效率进一步下降。实际上推理所需的显存远低于训练,10B左右的模型完全可以放在单卡上做推理,从而避免模型并行带来的开销。
3.2 TRT-LLM为什么可以提高文本生成速度
对于问题1,TRT-LLM通过引入paged attention机制优化显存占用,从而提高batch_size,改善吞吐率;
-
对于问题2,TRT-LLM通过引入inflight batching机制替换已完成的生成任务,大大减少了无效生成,对于序列长度分布极不均匀的场景,甚至观察到了5倍左右的吞吐率提升;
-
对于问题3,部署TRT-LLM可以无需遵照训练时的模型切分方式,因此也可以降低模型切分带来的开销。
3.3 引入TRT-LLM后带来的问题
3.3.1 额外的显存占用
很显然,TRT-LLM也需要消耗显卡的计算和存储资源,不过由于文本生成和训练在时间上是错开的,可以通过offload的方式错峰使用显存,使得训练和文本生成在显卡使用上互不影响。
3.3.2 参数更新
TRT-LLM以独立进程的方式部署,由于Actor的每轮更新,必须同步更新相应的TRT-LLM模型,简单的参数更新方法如下
3.3.2.1 naive方案
1.actor保存checkpoint到磁盘(训练框架所支持的格式);
2.再t转换为HuggingFace格式的checkpoint;
3.将HuggingFace格式的checkpoint转换成trtllm格式的checkpoint;
4.将TRT-LLM格式的checkpoint转换为TensorRT engine;
5.TRT-LLM Runtime从磁盘中加载TensorRT engine。
上述几个步骤涉及多次磁盘IO,由于模型参数量极大(23GB,参数格式为bf16),总耗时超过15分钟。如果是离线部署,这个方案是可以接受的,且框架有自带的转换脚本,无需额外的开发工作。但是强化学习需要在线更新,15分钟的更新时间会严重拖慢系统速度。幸运的是TensorRT提供了在线更新的接口。另外观察到上述的多次转换是由各个框架格式不兼容造成的,需要手动实现参数转换功能。
3.3.2.2 refit方案
前置条件
TRT engine需开启refit选项(开启方法可参考TRT-LLM文档,此选项会导致dump的TensorRT engine大10M左右,但不会影响性能)
主要步骤
1.(训练进程)将Actor模型的参数转换成TensorRT engine的参数格式,并拷贝到共享内存中(逐Tensor转换和拷贝,主要涉及到一些Tensor的拆分、合并以及转置操作等);
2.(训练进程)将Actor模型的参数和优化器状态等固定显存占用unload到cpu内存中(为TRT-LLM推理腾退显存,可unload部分参数),通知(RPC方式)TRTLLM进程加载最新参数;
3.(TRT-LLM进程)加载cpu内存中保存的TensorRT engine;
4.(TRT-LLM进程)遍历共享内存中的参数并改写TensorRT engine (逐Tensor改写)
整个过程消除了磁盘IO,更新时间优化到20s左右;另外如果考虑使用单卡部署TRT-LLM,从而消除不必要的通讯开销以及空泡(PP),还可以使用共享内存+NCCL通讯的方式更新参数,如下图所示:
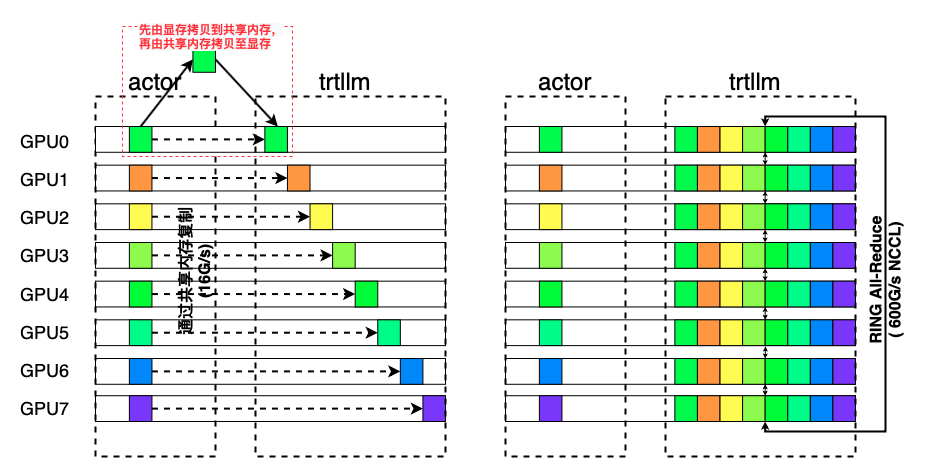
相比于共享内存,显卡间的NCCL通讯速度极快,参数拷贝时间几乎可以忽略不计。
3.4 吞吐率改进状况
1. 系统关键部分耗时

从耗时统计中可以看出,TRT-LLM对文本生成速度提升了超过30倍,大大超出预期。
2. 吞吐率计算
系统各关键部分全部为串行执行,一次ppo迭代的耗时时间为:
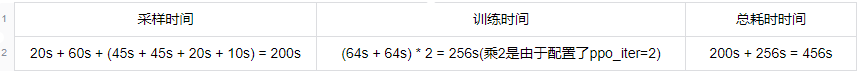
可以计算得到系统吞吐率为 256 sample / 456 s / 16 gpu = 0.035 sample / gpu / s,相较于基线吞吐率提升了将近192%。
04 动态显存优化
RLHF训练过程中显存常常是紧缺资源,显存会造成两个问题,一是训练过程中突然出现的OOM警告,使得跑了很长时间的任务失败;二是为了避免OOM刻意调小batch_size,使得显卡计算单元的利用率下降,训练时间延长。大模型训练过程中的显存占用分为固定显存占用以及动态显存占用。固定显存主要包括参数、梯度和优化器状态,对于类Megatron-LM框架来说,固定显存通过模型并行切分之后,继续优化的空间较小,因此需要开发人员关注的是动态显存优化。动态显存主要包括前向的激活以及临时变量等,下面将介绍这两种显存的优化方法。另外对于推理框架来说,激活和临时变量相比kv cache几乎可以忽略不计,而通过引入paged attention技术,kv cache显存占用已经得到了很好的优化,因此这里不多做讨论。
4.1 选择性激活重算 + 序列并行
在反向传播过程中,需要前向过程中的激活参与计算,因此需要保存这部分结果。激活所占的显存比例随着模型规模、batch_size以及序列长度的增加而逐步增加。对特定的模型,当需要增加batch_size以提升训练速度或者需要适配长文本训练任务时,显存会成为最棘手的问题。可通过重算技术来减小激活显存消耗,也就是只保存少部分中间激活,剩余的部分在需要时重新计算。重算对激活显存的优化效果是立竿见影的,但是同时也导致了速度的严重退化。最新的重算技术选择激活显存占用小同时计算较慢的算子作为检查点,而显存占用大并且计算较快的算子的中间结果则被丢弃,这种选择性重算技术虽然在激活显存优化能力上有所下降,但是能够保证速度退化不至于过于严重。
另一种激活显存优化技术是序列并行,这个技术由Megatron-LM引入,其核心思想仍然是使用通讯换取显存。具体而言,Megatron-LM的作者观察到那些TP无法切分的区域,在序列轴的维度上是相互独立的,因此可以在序列轴上进行切分,如下图所示:
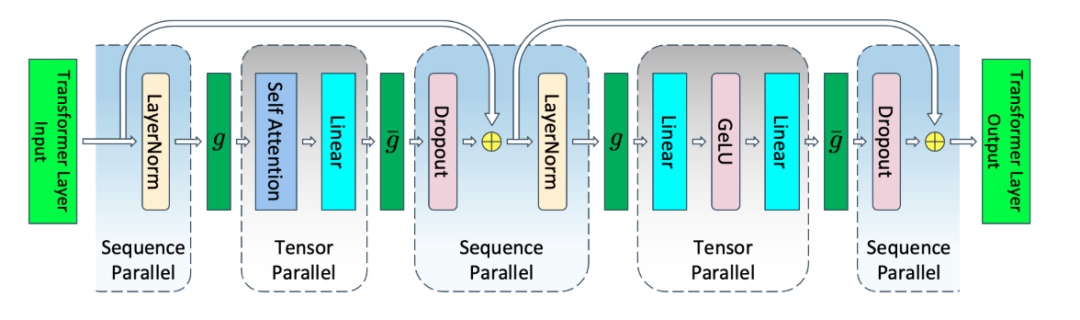
实验中观察到,在PP=8的条件下,使用序列并行+选择性重算能够优化掉50%左右的激活显存,但是会带来20%左右的速度退化。可以将batch_size提升至原先的两倍,最终的训练速度相比之前提升接近15%。同时对于更长的文本,预期会有更大的改进。
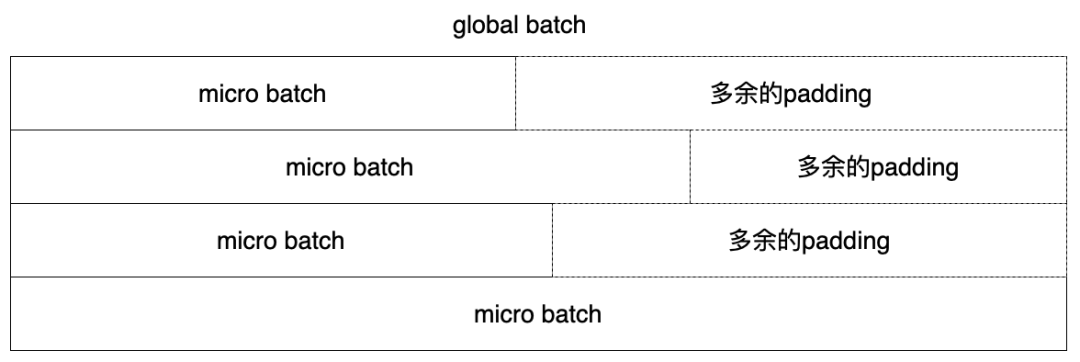
4.2 按照micro_batch进行padding
这部分以及后面的临时显存优化是一些编程上的注意事项,并无太多的理论。具体而言,当编写训练部分的代码时为图省事,或者不经意间,会对global_batch进行padding,实际进行前向和反向计算时是以micro_batch为单位的,当global_batch内长度分布极不均匀时,由padding导致的计算时间大大增加。
4.3 临时显存优化
临时显存优化的两大原则:
- 尽早释放
2. 避免申请过大的显存资源
以推理过程中next_logp计算的优化为例,优化前global_batch_size无法开大,对于训练效果和训练效率均会造成一定影响。下面以gbs=64,mbs=2为例说明:
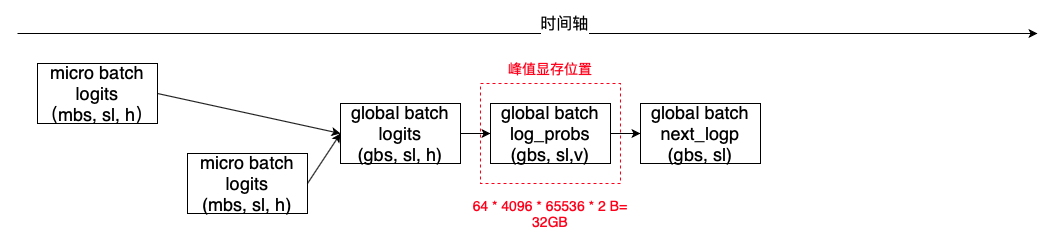
通过提前计算mbs,尽早释放中间显存,可以将峰值显存从gbs * N优化到mbs * N。
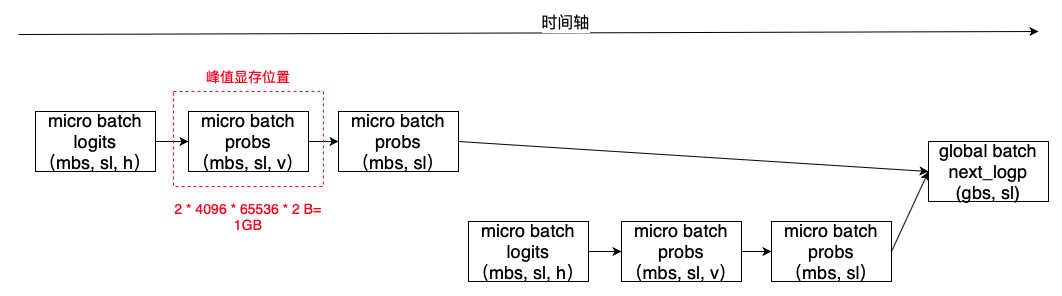
对mbs的计算中也申请了一块2GB左右的显存,通过将计算的粒度控制在单条样本,还可以进一步降低峰值显存占用,代价是计算效率会有所降低,这点需要权衡。
4.4 吞吐率改进状况
由于优化了显存,系统可以使用更大的global_batch_size,降低了流水并行的空泡率(如果开PP的话),从而提高了训练速度。按照micro_batch进行padding由于节省了计算,又进一步提升了训练速度。总的提升大约在10%左右。
1.系统关键部分耗时

2.吞吐率计算
系统各关键部分全部为串行执行,一次ppo迭代的耗时时间为: 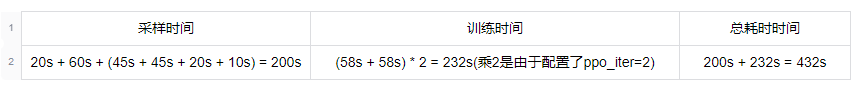
可以计算得到系统吞吐率为 256 sample / 432 s / 16 gpu = 0.037 sample / gpu / s,相较于基线吞吐率提升了将近208%。
05 系统并行优化
5.1 优化方法
PPO是一个典型的多阶段流程,所包含的步骤中有些有前后依赖关系,需要串行执行,也有一些步骤则没有依赖关系,可以并行执行,如下图所示:
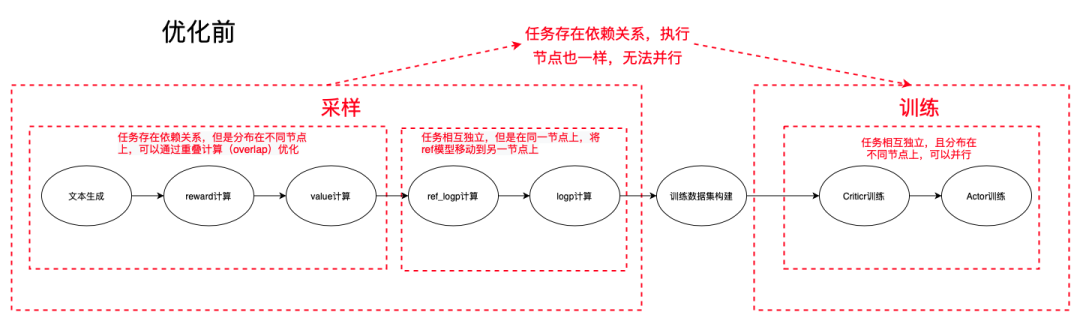
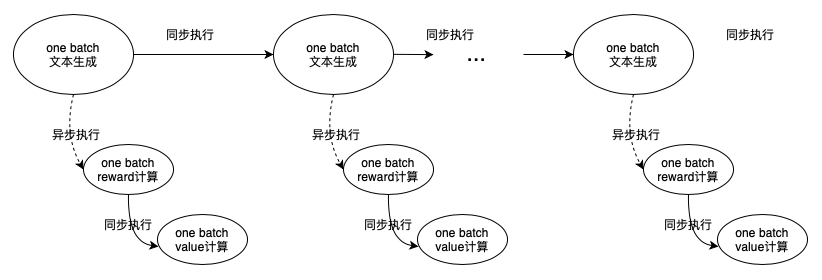
Actor的训练和Critic的训练任务在不同节点并且相互独立时,可以很容易进行并行计算。ref_logp和logp的计算任务虽然相互独立,但由于在同一节点需要共享显卡,且单个任务既可打满利用率,此时任务并行的意义不大(虽然cuda通过stream机制很容易支持并发任务)。观察到对于ref_logp计算这种仅做推理的任务,将其移动到critic所在的节点也几乎没有影响,之后便可以进行并行计算ref_logp和logp。比较复杂的是文本生成与reward计算之间的并行,两者虽分布在不同的节点,但是任务之间存在依赖关系,即reward计算所需要的句子是文本生成的结果。观察到文本生成按照batch计算并返回,可以通过下述方法重叠两者的计算。
优化后的系统如下所示:
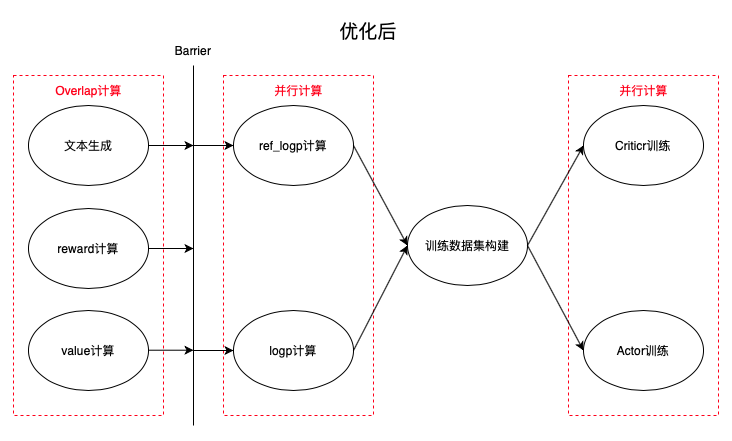
系统中还存在其他一些可以并行的部分,例如actor模型的加载/卸载,共享内存拷贝和TRT-LLM模型的卸载/加载与refit_engine等,其优化方法与上述提到的思想大同小异,这里不再详细介绍。
5.2 吞吐率改进状况
1.系统关键部分耗时
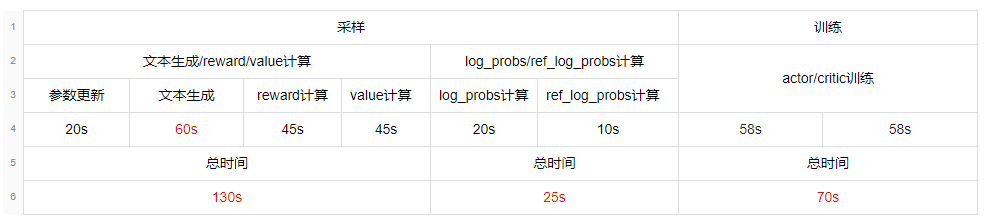
2.吞吐率计算
系统各关键部分全部为串行执行,一次ppo迭代的耗时时间为

可以计算得到系统吞吐率为 256 sample / 275s / 16 gpu = 0.054 sample / gpu / s,相较于基线吞吐率提升了将近350%。
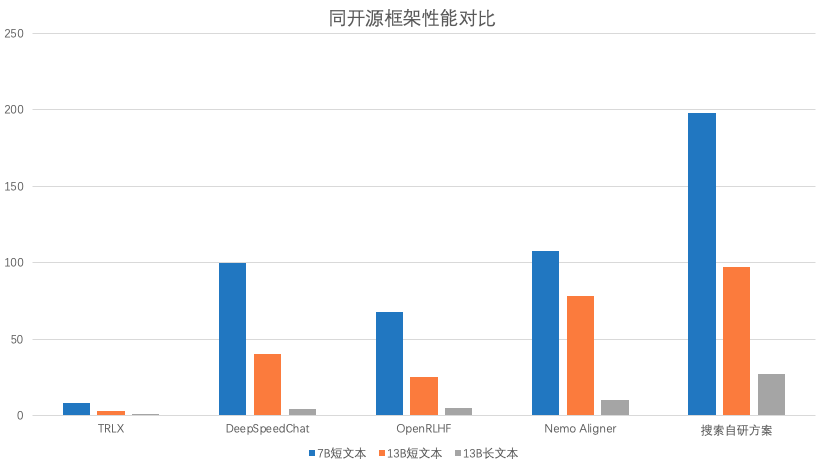
06 其他开源框架对比
实验设置:
全参数RLHF训练,采用16*A100(80G)训练。
07 总结
综上,我们在广泛实验、对比和学习了业界主流框架的情况下,通过分析RLHF任务的特点并采用先进的大模型预训练及推理性能优化手段,使得RLHF任务性能大幅提升,能够以相对少的资源支持了业务的快速迭代和发展,取得了良好的业务效果。
————END————
推荐阅读
基于飞桨框架实现PCA的人脸识别算法
统一多场景自动编译加速——支持动态shape场景,一套架构搞定训推需求
基于飞桨框架的稀疏计算使用指南
云高性能计算平台 CHPC 让企业的传统 HPC 玩出新花样
Embedding空间中的时序异常检测















![[学习笔记]在不同项目中切换Node.js版本](https://i-blog.csdnimg.cn/direct/50c5aa75ec0b4a5088865cef00cefe28.png)