首先yolov8中loss的权重可以在ultralytics/cfg/default.yaml修改
损失函数定义ultralytics/utils/loss.py
回归分支的损失函数
- DFL(Distribution Focal Loss),计算anchor point的中心点到左上角和右下角的偏移量
- IoU Loss,定位损失,采用CIoU loss,只计算正样本的定位损失
target_bboxes /= stride_tensor
loss[0], loss[2] = self.bbox_loss(
pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask
)
分类损失:
- BCE loss,只计算正样本的分类损失。
loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum
CIOU loss
- 调用 loss 方法
"""IoU loss."""
weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
iou函数
def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
box1: 表示一个边界框,形状为(1, 4)的Tensor。
box2: 表示n个边界框,形状为(n, 4)的Tensor。
xywh: 如果为True,表示输入的框格式为(x, y, w, h)(中心点坐标和宽高);如果为False,则输入格式为(x1, y1, x2, y2)(左上角和右下角坐标)。
GIoU, DIoU, CIoU: 控制是否计算相应的IoU扩展版本。
eps: 一个小值,用于避免除零错误。
- 计算交集面积
- 计算得到交集 h和w相乘
inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp_(0) * (b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1) ).clamp_(0)
- 计算得到并集
union = w1 * h1 + w2 * h2 - inter + eps
- 计算IOU(交集/并集)
iou = inter / union
- 其中Yolo中使用的CIOU,补充CIOU内容
- CIOU是IOU的基础上进行的计算IOU部分相同
- 第一步还是计算IOU
- 第二步,计算包围两个边界框的最小矩形s的h和w
cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
- 第三步,计算s的对角线的平方c2,两个边界框中心点之间距离的平方rho2
c2 = cw.pow(2) + ch.pow(2) + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2).pow(2) + (b2_y1 + b2_y2 - b1_y1 - b1_y2).pow(2)) / 4 # center dist**2
rho2推理过程:
中心点cx:cx = (x1 + x2) / 2
中心点cy:cy = (y1 + y2) / 2
两个框中心点分别是 (cx1, cy1) 和 (cx2, cy2)距离为:根号下(cx2-cx1)^2 + (cy2-cy1)^2
距离的平方:cho2 = (cx2-cx1)^2 + (cy2-cy1)^2
展开得:((x1 + x2) / 2-(x1_2 + x2_2) / 2)^2...
整理得:1/4 * ((x1 + x2) -(x1_2 + x2_2))与代码一致
- 第四步,计算一个与边界框宽高比相关的v,根据v计算权重alpha得到最终CIOU
v = (4 / math.pi**2) * ((w2 / h2).atan() - (w1 / h1).atan()).pow(2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
这里就完成了iou loss计算过程
DFL loss
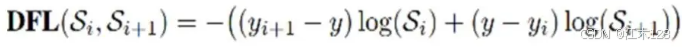
调用 dfl loss
if self.use_dfl:
target_ltrb = bbox2dist(anchor_points, xywh2xyxy(target_bboxes[..., :4]), self.reg_max)
loss_dfl = self._df_loss(pred_dist[fg_mask].view(-1, self.reg_max + 1), target_ltrb[fg_mask]) * weight
loss_dfl = loss_dfl.sum() / target_scores_sum
- 第一步,调用bbox2dist将输入的坐标转换为距离中心的四个方向的距离l、t、r、b
- anchor_points - x1y1 计算的是锚点到左上角 (x1, y1) 的水平距离和垂直距离,即 l 和 t。
x2y2 - anchor_points 计算的是右下角 (x2, y2) 到锚点的水平距离和垂直距离,即 r 和 b。
- anchor_points - x1y1 计算的是锚点到左上角 (x1, y1) 的水平距离和垂直距离,即 l 和 t。
dfl loss函数
def _df_loss(pred_dist, target):
tl = target.long() # target left
tr = tl + 1 # target right
wl = tr - target # weight left
wr = 1 - wl # weight right
return (F.cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape) * wl + F.cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape) * wr).mean(-1, keepdim=True)
- tl和tr代表目标值的左右边界
- wl是左边界的权重,wr是右边界的权重,如真实坐标值为8.3,那么它距离8近给一个大一点的权重0.7,距离9远,给一个小一点的权重0.3
- 分别计算预测分布与左右目标值交叉熵损失并求和
- 注:其中
pred_dist[fg_mask]代表了目标的布尔分布,假设 self.reg_max = 7,这意味着我们对每个像素点的预测是在 0 到 7 的范围内的一组离散值,总共有8个可能的值。因此pred_dist[fg_mask]应该是形状为 (n, 8) 的张量,其中 n 是通过 fg_mask 选出来的前景位置的数量。view(-1, 8) 就是确保张量的每一行对应一个前景位置,并包含了所有 8 个可能的预测值。 - 注2:代码中的
anchor_points代表了一个格子是前景的中心点,l、t、r、b是anchor_points距离整个物体边界的距离
网络输出的pred_dist如何获得
- 首先要得到
anchors和strides
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
def make_anchors(feats, strides, grid_cell_offset=0.5):
feats:输入特征图列表,通常是从不同的特征层中提取的特征图。
strides:特征图的下采样步长列表,对应每个特征图。
grid_cell_offset:用于调整锚点位置的偏移量,默认为 0.5,即锚点位于网格单元的中心。
for i, stride in enumerate(strides):
_, _, h, w = feats[i].shape
sx = torch.arange(end=w, device=device, dtype=dtype) + grid_cell_offset # shift x
sy = torch.arange(end=h, device=device, dtype=dtype) + grid_cell_offset # shift y
sy, sx = torch.meshgrid(sy, sx, indexing="ij") if TORCH_1_10 else torch.meshgrid(sy, sx)
anchor_points.append(torch.stack((sx, sy), -1).view(-1, 2))
stride_tensor.append(torch.full((h * w, 1), stride, dtype=dtype, device=device))
return torch.cat(anchor_points), torch.cat(stride_tensor)
h 和 w 分别表示特征图的高度和宽度。
sx 和 sy 分别是水平和垂直方向上的网格坐标(加上偏移量后,中心在网格单元中心)。
torch.meshgrid 用于生成二维网格坐标(sx 和 sy),这些坐标将构成锚点。
torch.stack((sx, sy), -1).view(-1, 2) 将 sx 和 sy 坐标组合为 (x, y) 坐标对,并展平为一个二维的锚点列表。
torch.full((h * w, 1), stride, dtype=dtype, device=device) 生成一个步长张量,与锚点数量匹配。
- 对box进行如下卷积
class DFL(nn.Module):
def __init__(self, c1=16):
super().__init__()
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
x = torch.arange(c1, dtype=torch.float)
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1
def forward(self, x):
"""Applies a transformer layer on input tensor 'x' and returns a tensor."""
b, _, a = x.shape # batch, channels, anchors
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
# return self.conv(x.view(b, self.c1, 4, a).softmax(1)).view(b, 4, a)
conv不进行训练,权重是默认的,self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1)),即[0, 1, 2, ..., c1-1]
forward:
这里将输入张量 x 重新调整形状为 (batch_size, 4, c1, num_anchors)。4 表示每个锚点的4个回归值(通常是 l, t, r, b,即到边界的距离)。
transpose(2, 1):交换维度,将张量变为 (batch_size, c1, 4, num_anchors) 的形状。这使得通道维度 c1 排在第二位。
.softmax(1):对 c1 维度(即原来的通道维度)应用 softmax 操作。softmax 将每个类别的预测转换为概率分布,这在 DFL 中用于对每个边界框的预测进行更加细粒度的调整。
self.conv(...):使用 1x1 卷积对经过 softmax 的输出进行处理,实际上是对 softmax 结果的加权平均。由于卷积层的权重被初始化为 0 到 c1-1 的线性值,这一步相当于计算 softmax 结果的期望值,输出的每个通道的值可以被解释为最终预测的偏移量。
view(b, 4, a):将最终的输出张量调整回形状 (batch_size, 4, num_anchors),即每个锚点有4个回归值。