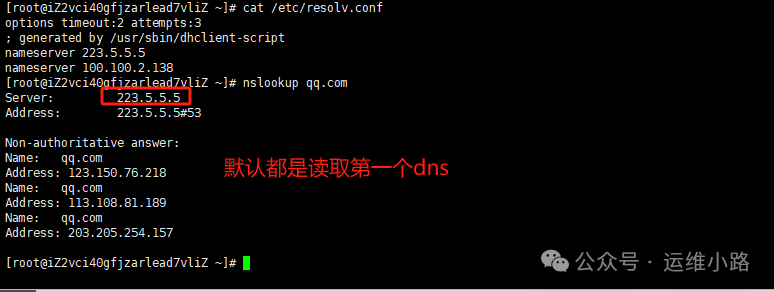
内嵌汇编代码基本用法
1.作用:对于特定重要和时间敏感的代码进行优化,同时在C语言中访问某些特殊指令(例如内存屏障指令)来实现特殊功能
2.内嵌汇编代码主要有两种形式
基础内嵌汇编代码:不带任何参数
扩展内嵌汇编代码:可以带输入输出参数
3.扩展内嵌汇编代码
asm 修饰词(
指令部分
:输出部分 //可以为空
:输入部分 //可以为空
:损坏部分)//"cc":寄存器改变 "memory":
- 各部分解释
修饰词:
volatile 用于关闭GCC优化
inline 用于内联,GCC会把汇编代码编译为尽可能短的代码
goto 用于内嵌汇编跳转到C语言的标签里面
输出部分用于描述在指令部分中可以修改的C语言变量以及约束条件。
输出约束通常以“=”或者“+”号开头,然后是一个字母(表示对操作数类型的说明),接着是关于变量结合的约束。“=”表示被修饰的操作数只具有可写属性;“+”表示被修饰的操作数只具有可读、可写属性。
输出部分可以为空
输入部分用来描述在指令部分只能读取的C语言变量以及约束调试。输入部分描述的参数只具有可读属性,不要试图修改输入部分的参数内容,因为GCC假定输入部分的参数在内嵌汇编之前和之后都是一致的。
在输入部分中不能使用“=”或者“+”约束条件,否则编译器会报错。
输入部分可以为空
损坏部分一般以“memory”结束
“memory”告诉GCC,如果内联汇编代码改变了内存中的值,那么让编译器做如下优化;在执行完汇编代码后重新加载该值,目的是放置编译乱序。
“CC”表示内嵌代码修改了状态寄存器的相关标志位,例如,使用CNBZ等比较语句。
当输入部分和输出部分显式地使用了通用寄存器时,应该在损坏部分明确告诉编译器,编译器在选择使用哪个寄存器来表示输入和输出操作数时,不会使用损坏部分里声明的任何寄存器,以免冲突。
指令部分,在内嵌汇编代码中使用%0来表示输出部分和输入部分的第一个参数,%1表示第二个参数,以此内推。
内嵌汇编代码的修饰符和约束符
1.内嵌汇编代码的常见修饰符

2. 内嵌汇编代码的常见约束符

3.ARM64体系结构中特有的约束符

使用汇编符号名
int add(int i,int j)
{
int res =0;
asm volatile (
"add %w[result], %w[input_i], %w[input_j]"
:[result] "=r" (res)
:[input_i]"r"(i) [input_j]"r"(j)
);
return res;
}
先看输出部分,其中只定义了一个操作数。“result”定义了一个汇编符号操作数,符号名为result,它对应“=r”(res),并使用了函数中定义的 res 变量,在汇编代码中对应%w[resul]中,w表示ARM64中的32位通用寄存器。再看输入部分,其中定义了两个操作数。同样使用定义汇编符号操作数的方式来定义。第1个汇编符号操作数是 input_i ,对应的是函数形参i,第2个汇编符号操作数是 input_j,对应的是函数形参j。
内嵌汇编函数与宏的结合
1.内嵌汇编函数与C 语言宏可以结合起来使用,让代码变得高效和简洁。我们可以巧妙地使
用C语言宏中的“#”以及“##”符号。若在宏的参数前面使用“#”,预处理器会把这个参数转换为一个字符串。“##”用于连接参数和另一个标识符,形成新的标识符。
#define ATOMIC_OP(op,asm_op)
static inline void atomic_##op(int 1, atomict *v)
{
register int w0 asm ("w0")= i;
register atomic_t *xl asm ("xl")=v;
asm volatile(ARM64_LSE_ATOMIC_INSN(__LL_SC_ATOMIC(op),
" "#asm_op "%w[1], %[v]\n")
: [i] "+r"(w0), [v] "+Q"(v->counter)
:"r"(X1)
:__LL_SC_CLOBBERS);
}
ATOMIC_OP(andnot, stclr)
ATOMIC_OP(or, stset)
ATOMIC_OP(xor, steor)
ATOMIC_OP(add, stadd)
使用goto修饰词
asm goto (
指令部分
:/*输出部分为空*/
:输入部分
:损坏部分
:Goto Labels)