茴香豆本地标准版搭建
茴香豆介绍
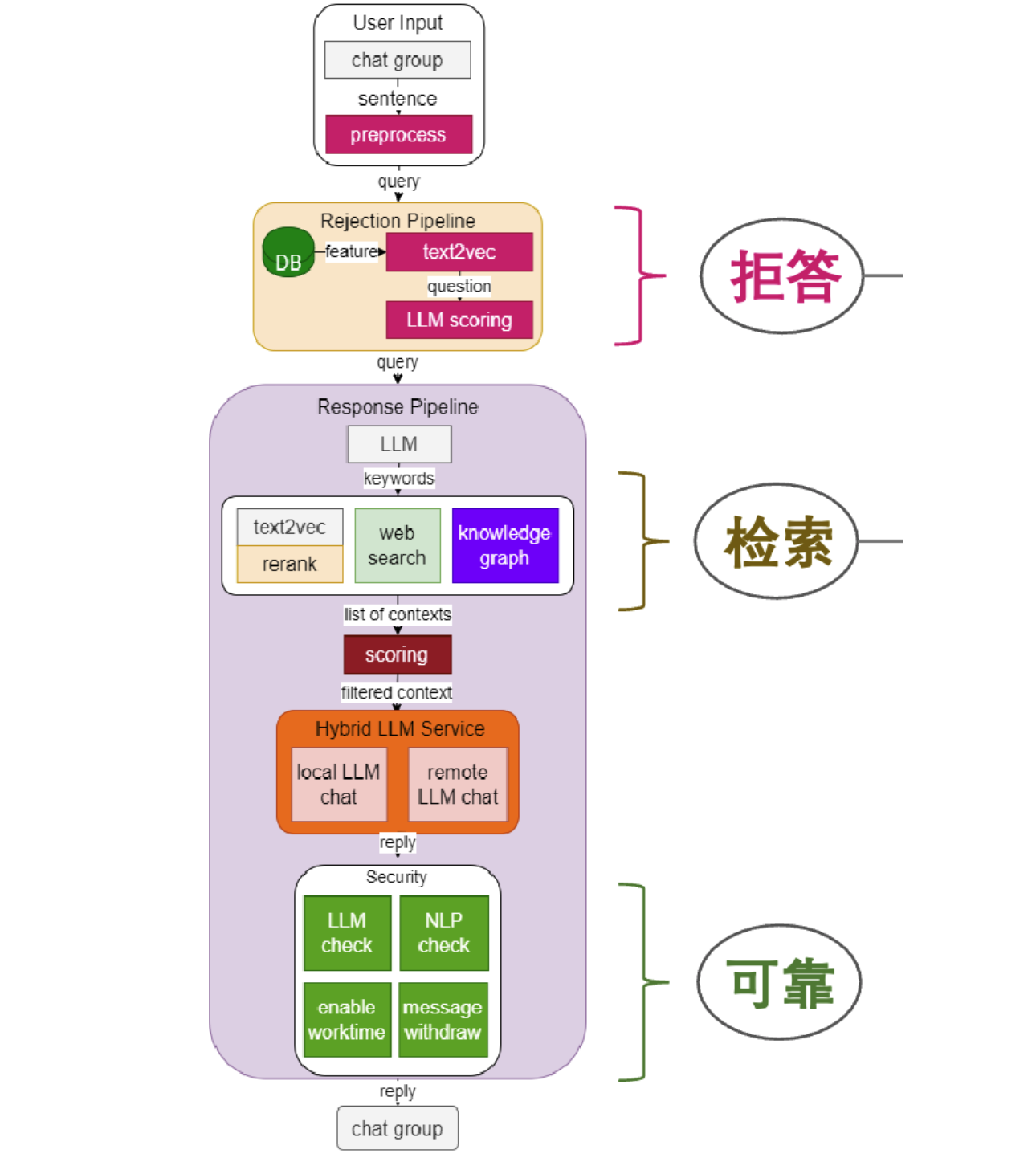
茴香豆 是由书生·浦语团队开发的一款开源、专门针对国内企业级使用场景设计并优化的知识问答工具。在基础 RAG 课程中我们了解到,RAG 可以有效的帮助提高 LLM 知识检索的相关性、实时性,同时避免 LLM 训练带来的巨大成本。在实际的生产和生活环境需求,对 RAG 系统的开发、部署和调优的挑战更大,如需要解决群应答、能够无关问题拒答、多渠道应答、更高的安全性挑战。因此,根据大量国内用户的实际需求,总结出了三阶段Pipeline的茴香豆知识问答助手架构,帮助企业级用户可以快速上手安装部署。
茴香豆特点:
- 三阶段 Pipeline (前处理、拒答、响应),提高相应准确率和安全性
- 打通微信和飞书群聊天,适合国内知识问答场景
- 支持各种硬件配置安装,安装部署限制条件少
- 适配性强,兼容多个 LLM 和 API
- 傻瓜操作,安装和配置方便
本地环境搭建-使用InternStudio
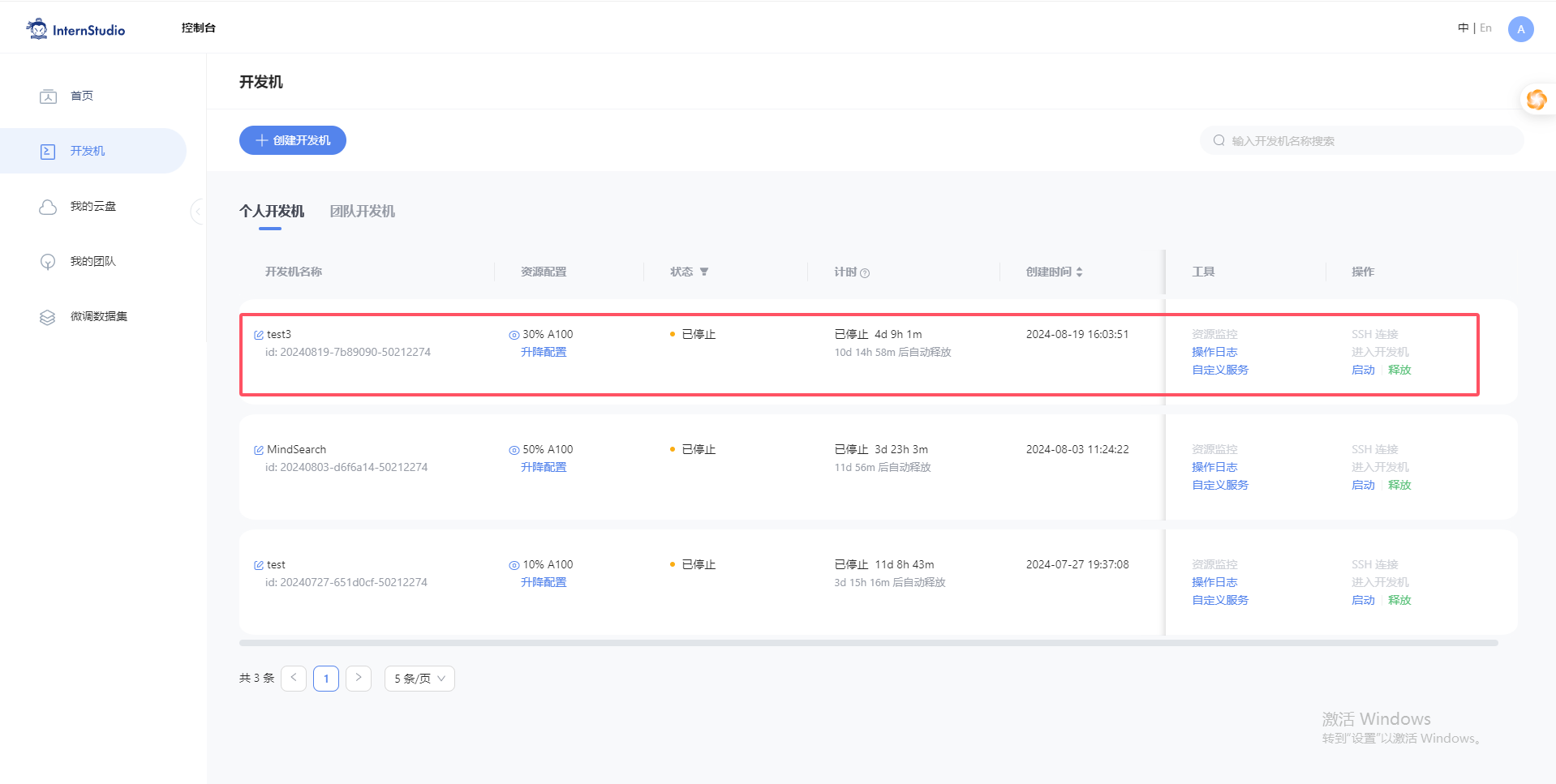
首先登录 InternStudio ,选择30%A100 资源
启动
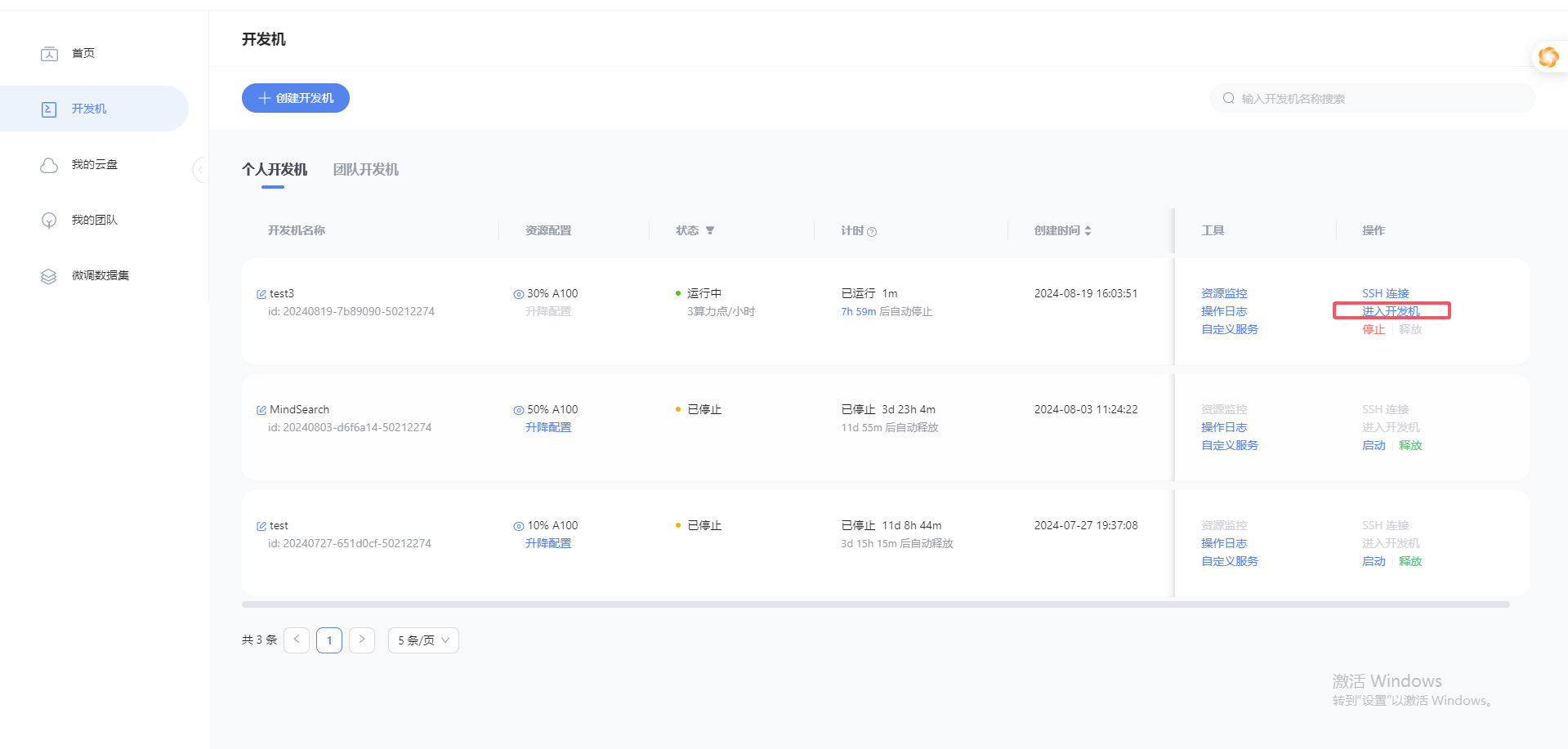
点击进入开发机
搭建茴香豆虚拟环境
studio-conda -o internlm-base -t huixiangdou
# 激活虚拟环境(注意:后续的所有操作都需要在这个虚拟环境中进行)
conda activate huixiangdou
cd /root
# 克隆代码仓库
git clone https://github.com/internlm/huixiangdou && cd huixiangdou
git checkout 79fa810
apt update
apt install python-dev libxml2-dev libxslt1-dev antiword unrtf poppler-utils pstotext tesseract-ocr flac ffmpeg lame libmad0 libsox-fmt-mp3 sox libjpeg-dev swig libpulse-dev
pip install BCEmbedding==0.1.5 cmake==3.30.2 lit==18.1.8 sentencepiece==0.2.0 protobuf==5.27.3 accelerate==0.33.0
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
下载模型文件
# 创建模型文件夹
cd /root && mkdir models
# 复制BCE模型
ln -s /root/share/new_models/maidalun1020/bce-embedding-base_v1 /root/models/bce-embedding-base_v1
ln -s /root/share/new_models/maidalun1020/bce-reranker-base_v1 /root/models/bce-reranker-base_v1
# 复制大模型参数(下面的模型,根据作业进度和任务进行**选择一个**就行)
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b /root/models/internlm2-chat-7b
完成后可以在相应目录下看到所需模型文件
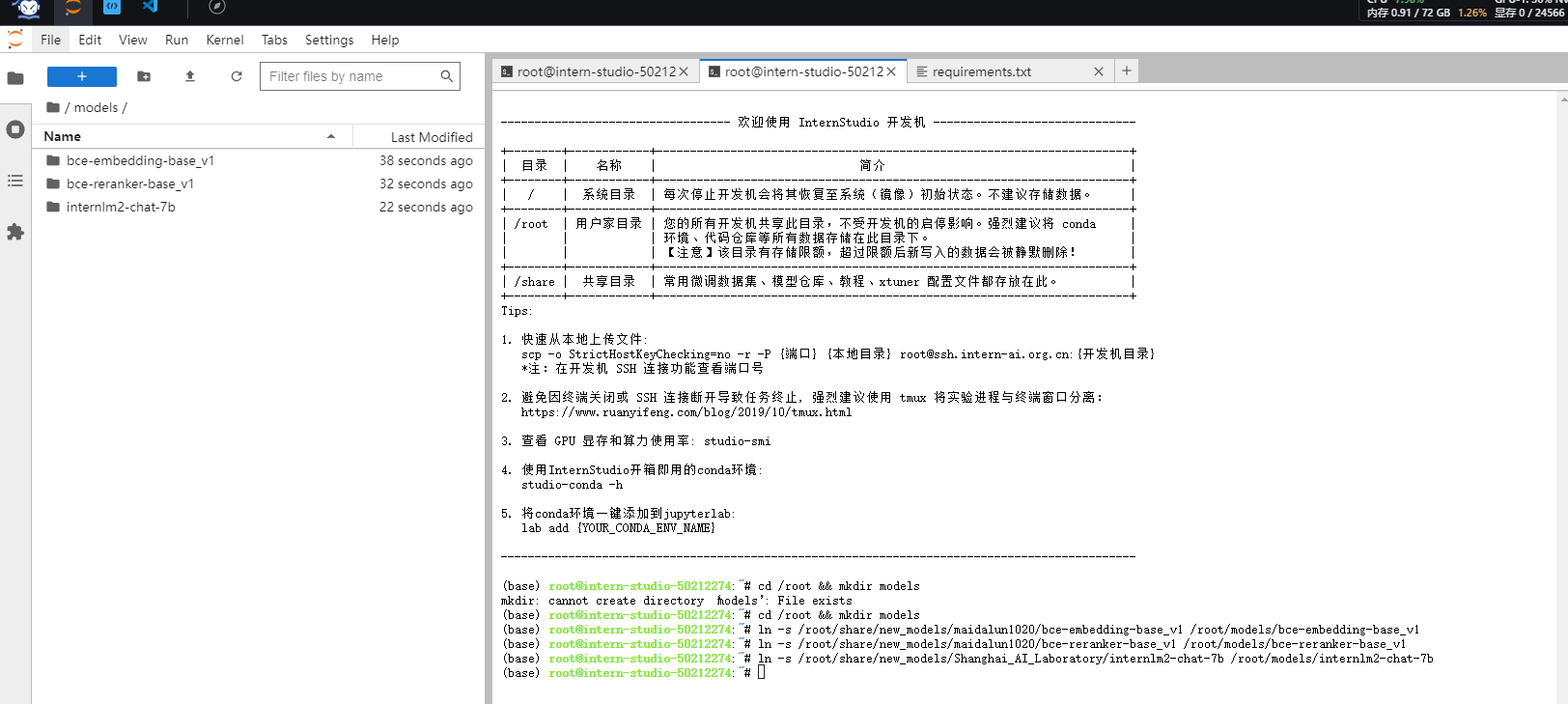
更改配置文件
执行下面的命令更改配置文件,让茴香豆使用本地模型:
sed -i '9s#.*#embedding_model_path = "/root/models/bce-embedding-base_v1"#' /root/huixiangdou/config.ini
sed -i '15s#.*#reranker_model_path = "/root/models/bce-reranker-base_v1"#' /root/huixiangdou/config.ini
sed -i '43s#.*#local_llm_path = "/root/models/internlm2-chat-7b"#' /root/huixiangdou/config.ini
修改后的配置文件如下:
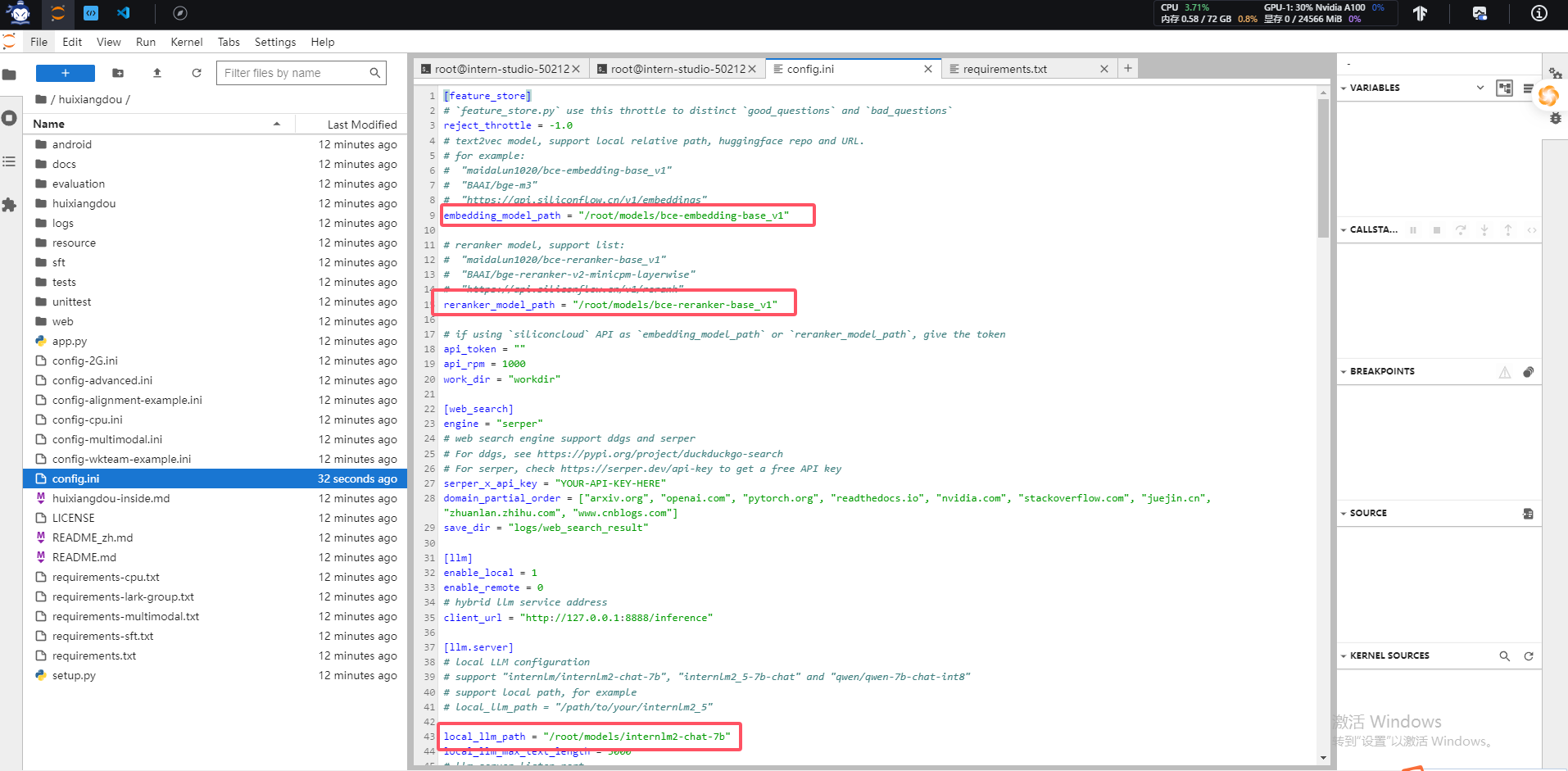
我们看到模型路径已经被替换本地模型路径地址了
知识库创建
修改完配置文件后,就可以进行知识库的搭建,本次教程选用的是茴香豆和 MMPose 的文档,利用茴香豆搭建一个茴香豆和 MMPose 的知识问答助手。
conda activate huixiangdou
cd /root/huixiangdou && mkdir repodir
git clone https://github.com/internlm/huixiangdou --depth=1 repodir/huixiangdou
git clone https://github.com/open-mmlab/mmpose --depth=1 repodir/mmpose
# Save the features of repodir to workdir, and update the positive and negative example thresholds into `config.ini`
mkdir workdir
python -m huixiangdou.service.feature_store
在 huixiangdou 文件加下创建 repodir 文件夹,用来储存知识库原始文档。再创建一个文件夹 workdir 用来存放原始文档特征提取到的向量知识库。

执行后效果
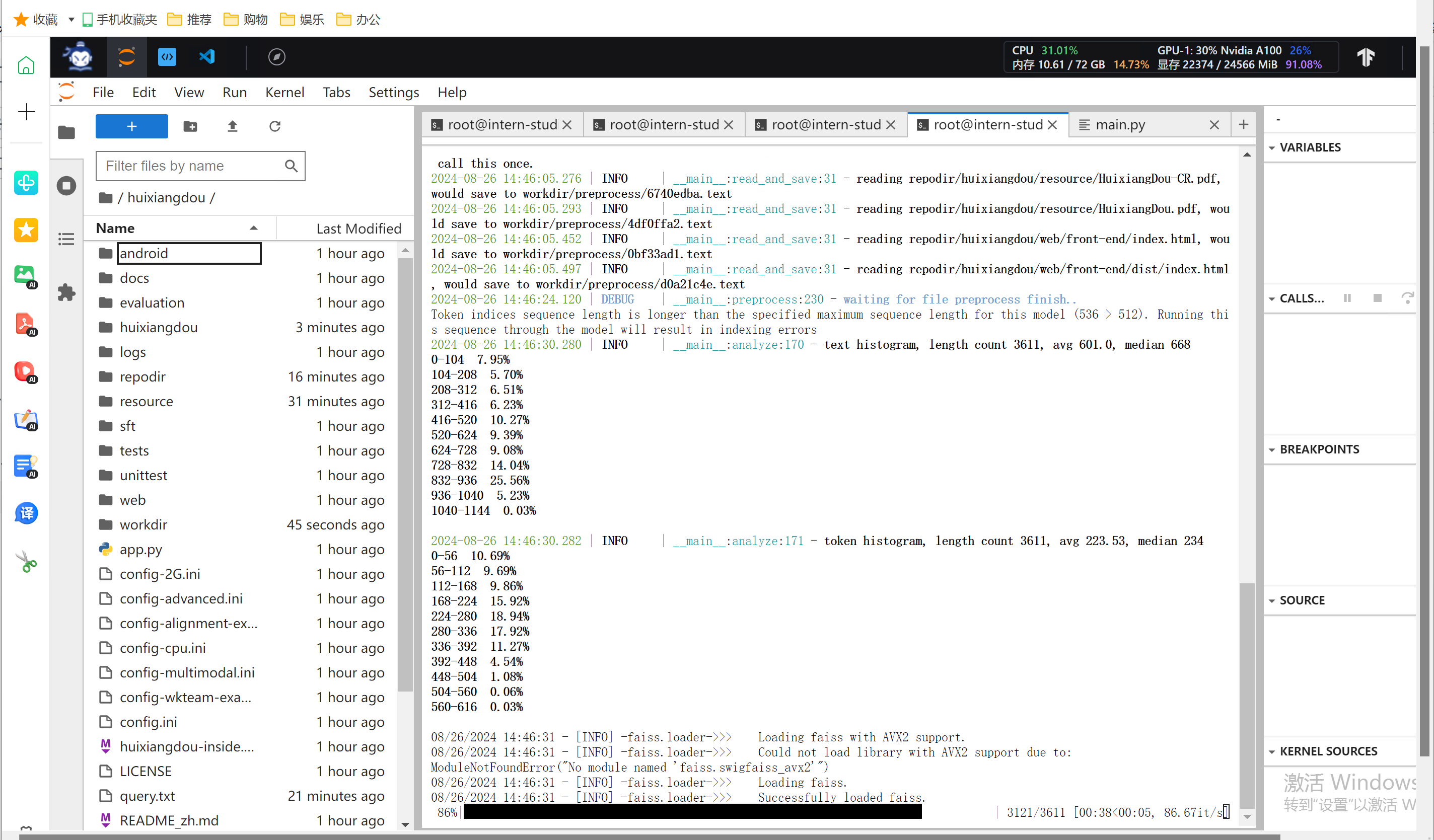
workdir 出现向量化数据

测试知识助手
运行下面的命令,可以用命令行对现有知识库问答助手进行测试:
conda activate huixiangdou
cd /root/huixiangdou
python -m huixiangdou.main --standalone
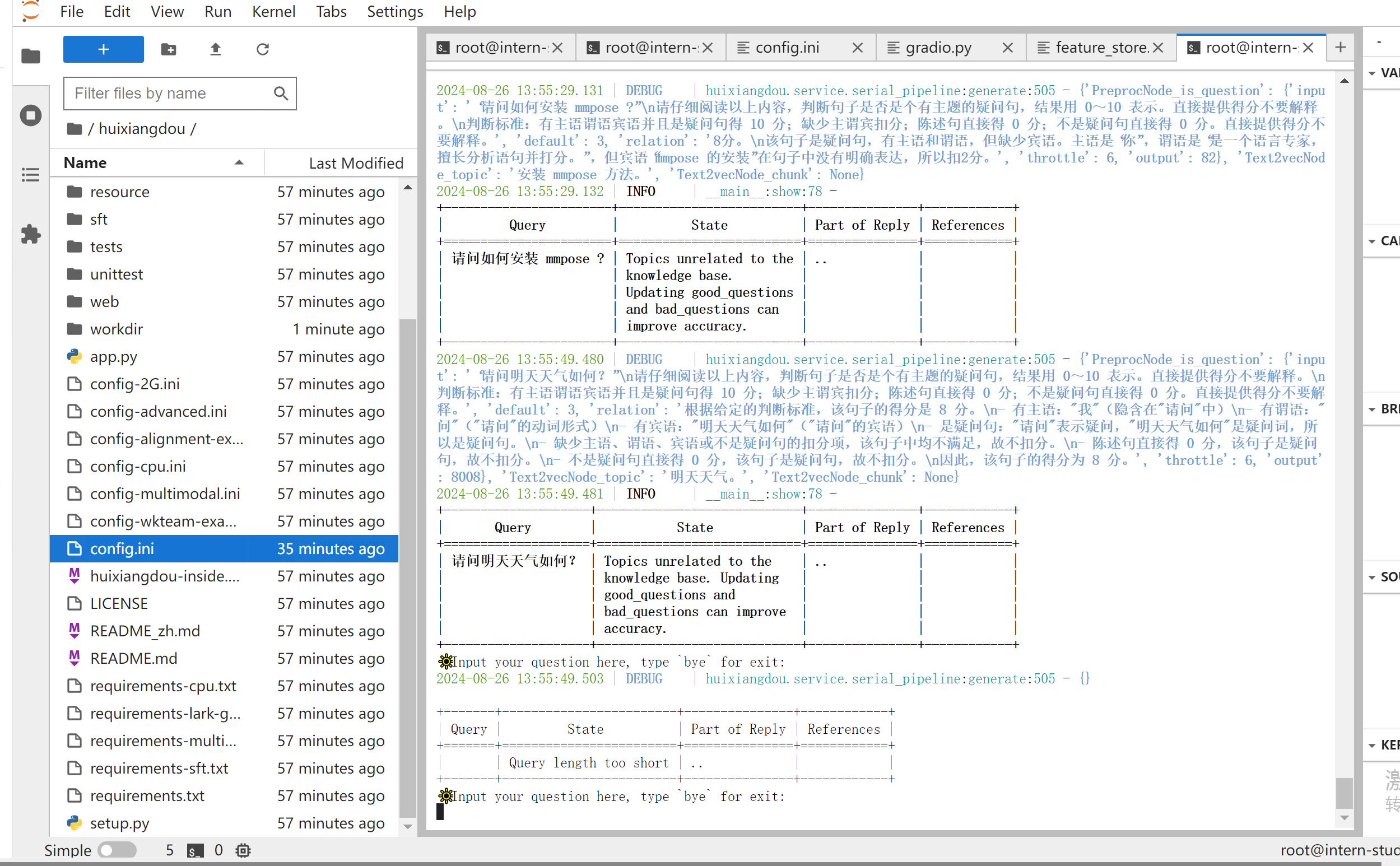
我们可以看到知识库助手测试验证可以使用的。
Gradio UI 界面测试
茴香豆也用 gradio 搭建了一个 Web UI 的测试界面,用来测试本地茴香豆助手的效果,启动茴香豆 Web UI
conda activate huixiangdou
cd /root/huixiangdou
python3 -m huixiangdou.gradio
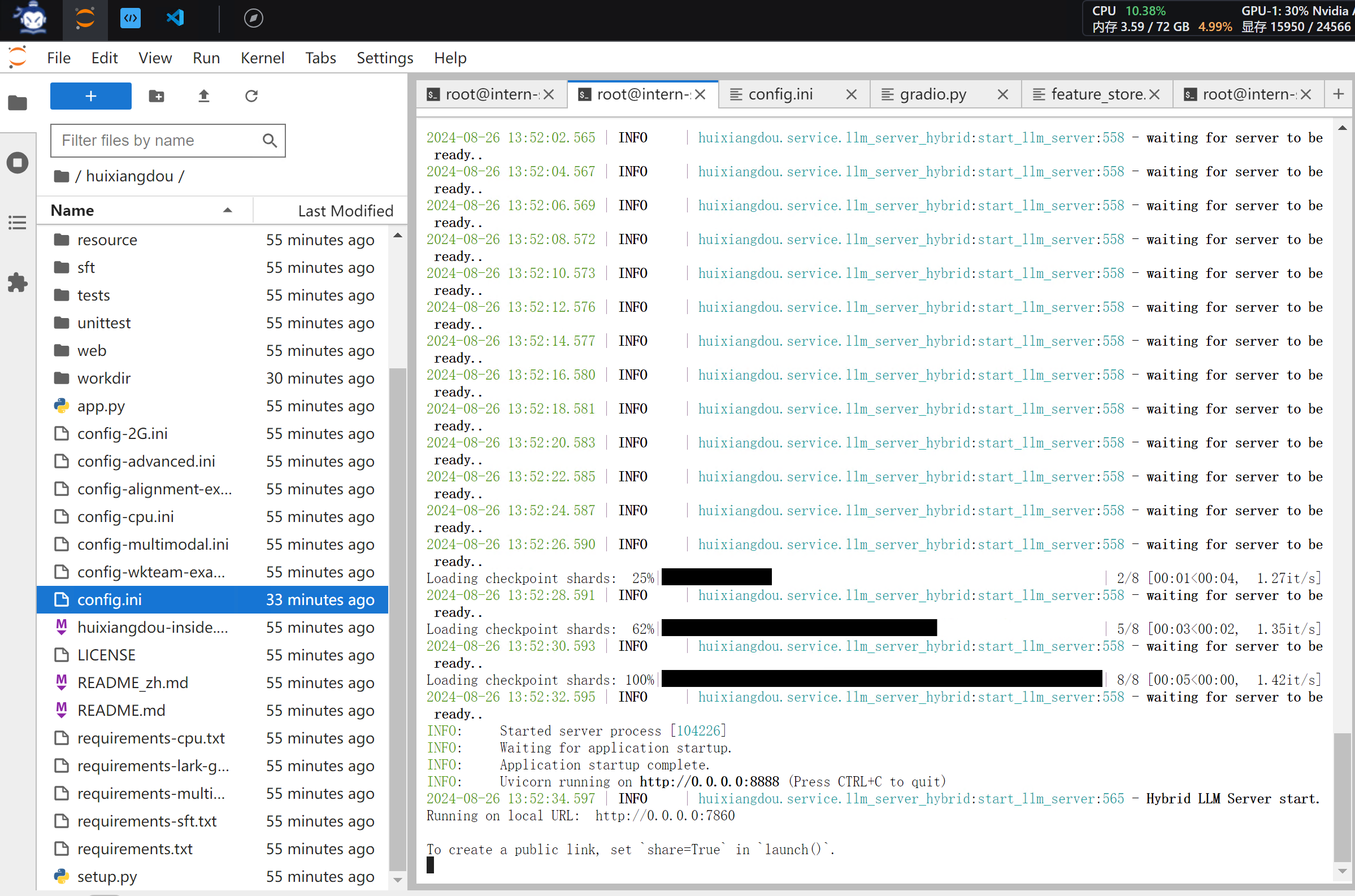
看到如上界面,启动完成。
接下来我们使用 启用端口转发到本地7860 端口
ssh -p 40552 root@ssh.intern-ai.org.cn -CNg -L 7860:127.0.0.1:7860 -o StrictHostKeyChecking=no

在本地浏览器中输入 127.0.0.1:7860 打开茴香豆助手测试页面

这里我们使用到知识库 是前面已经创建好的,正反例的信息可以在正例位于 /root/huixiangdou/resource/good_questions.json 文件夹中,反例位于/root/huixiangdou/resource/bad_questions.json 查找
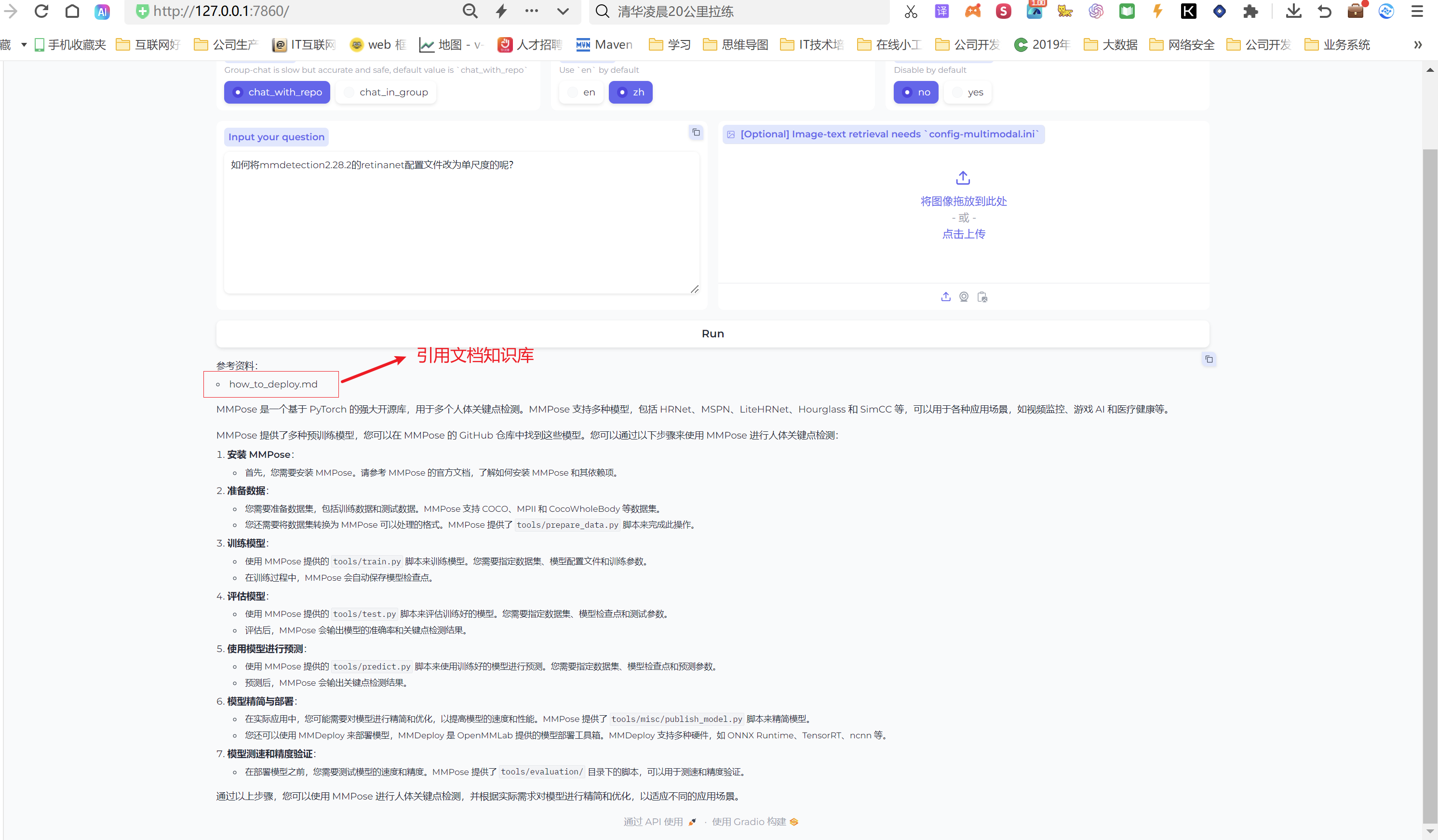
我们的问题 “如何将mmdetection2.28.2的retinanet配置文件改为单尺度的呢?” 模型给我们返回信息如下
在问一个问题“如何使用mmpose检测人体关键点?”
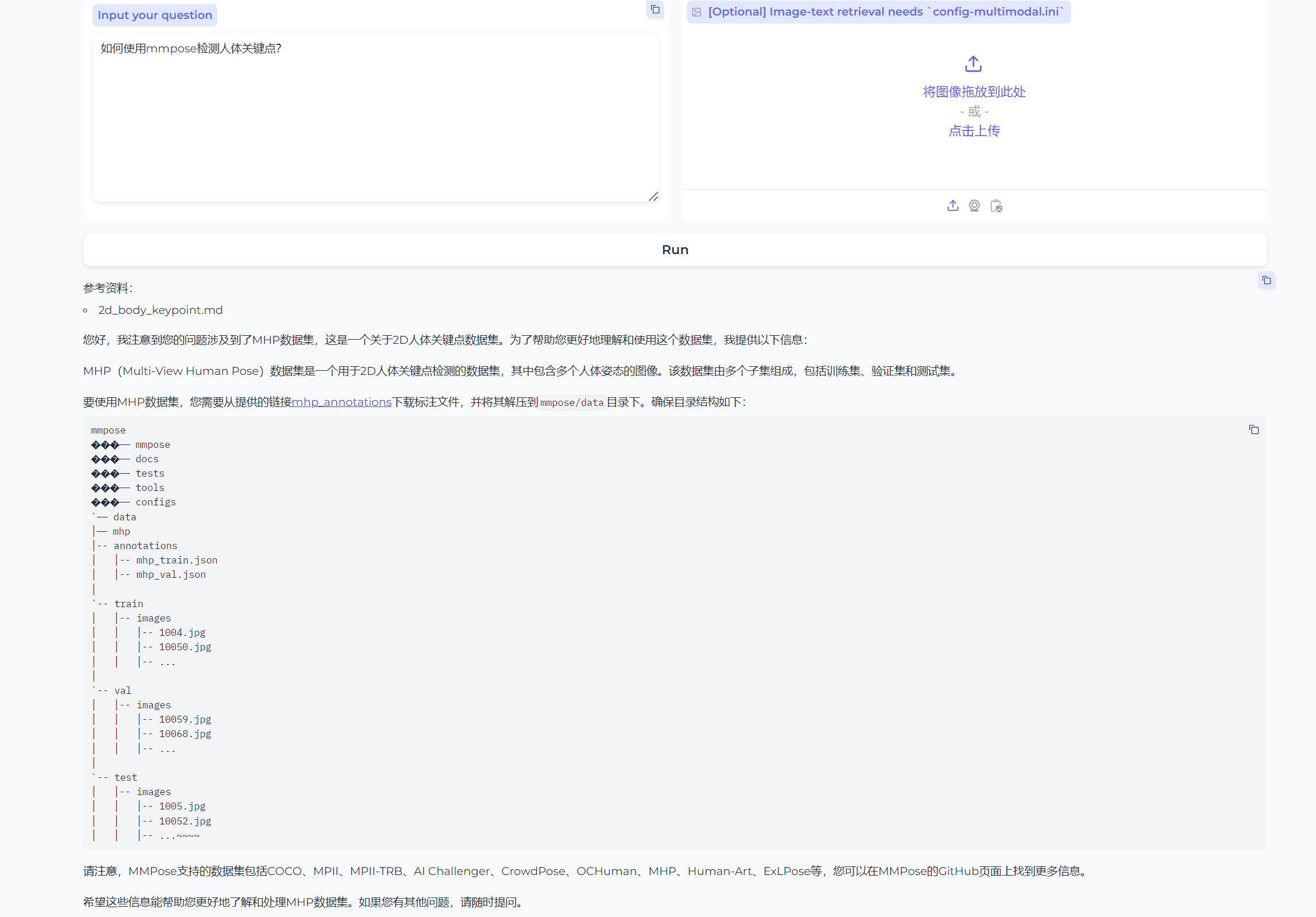
以上信息是基于知识库检索出来 然后在发给后端LLM 大模型进行推理的。上面我们主要是官方提供的例子实现的RAG增加检索。有的小伙伴可能会问了如果使用自己列子呢? 下面我们介绍一下这块如何实现。
创建自己知识库
首先我们需要找一个知识库,这里我们就以《少年歌行》小说为蓝本做测试,因为考虑这个本小说书较大,所以我们节选了小说的一部分内容。

节选小说内容大概 3512行,总字数有153355字

我们上面提到我们在创建知识库文档向量化的是用到了 正反例的信息。 也就是我们需要修改原项目中的/root/huixiangdou/resource/good_questions.json 和/root/huixiangdou/resource/bad_questions.json
我们打开原来的good_questions.json 和bad_questions.json
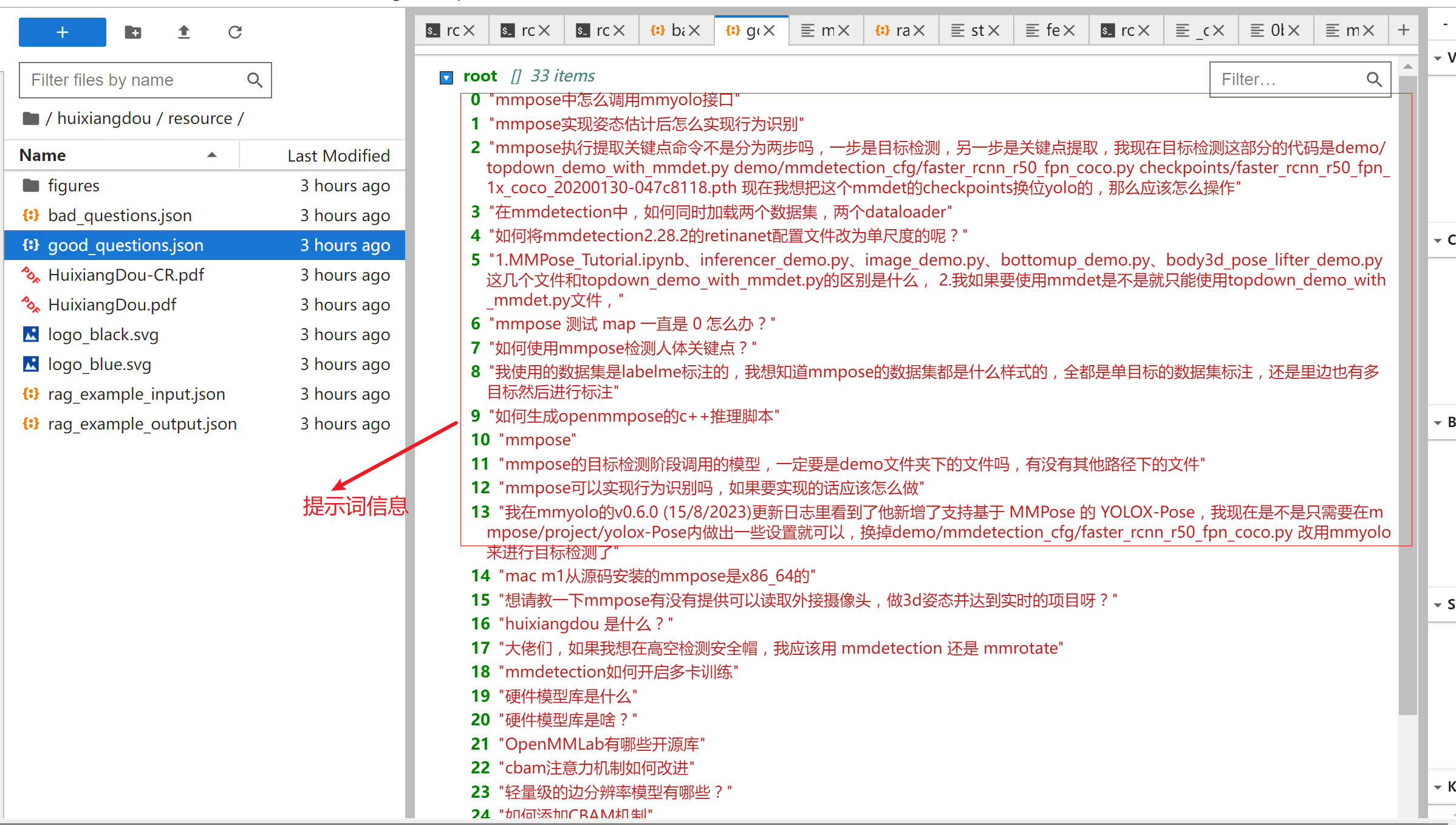
这里的提示词信息不是我们少年歌行小说书里面的内容,这块我们需要修改。因为编写这个正反例提示词工作量也比较大,我们可以借助gpt 等大模型来实现。
使用claude3.5 生成正反例的数据
我们将要少年歌行2.txt 和good_questions.json 和bad_questions.json 三个文件发给claude3.5 让他参考文档内容改写我们要的good_questions.json 和bad_questions.json
claude3.5 接受到消息后理解了我的意思 ,给我整理和小说内容的信息的正反提示词
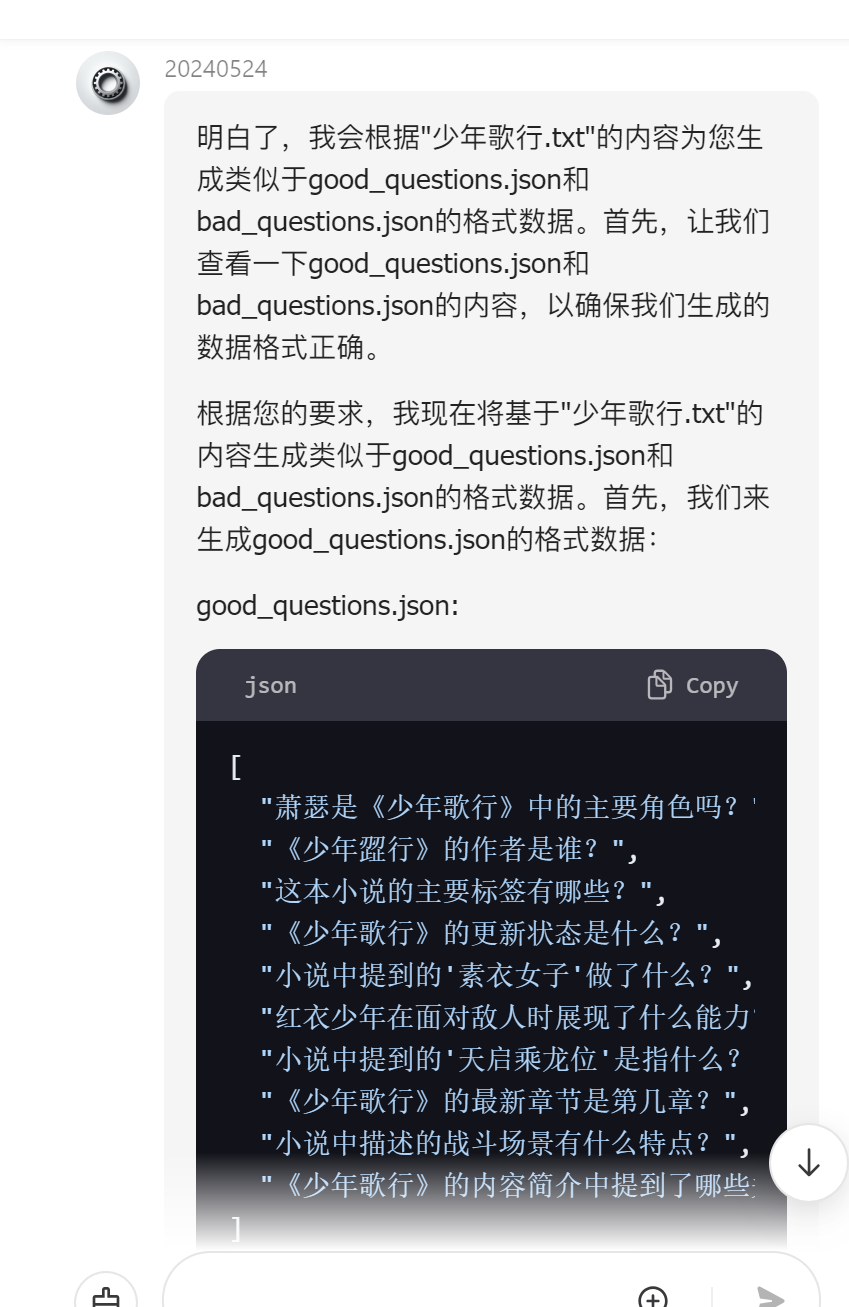
整理的结果
good_questions.json
[
"少年歌行的主角是谁?",
"小说中的素衣女子是什么角色?",
"萧瑟在故事中扮演什么角色?",
"少年歌行的主要标签是什么?",
"小说中的红衣少年有什么特殊能力?",
"故事中提到的'天启乘龙位'是什么?",
"小说中描述的战斗场景有哪些特点?",
"少年歌行的故事背景是什么样的?",
"小说中的逆袭元素体现在哪里?",
"作者周木楠在小说中塑造了什么样的人物形象?",
"少年歌行的主题思想是什么?",
"小说中的友情元素如何体现?",
"故事中的武器描写有哪些?",
"少年歌行的结局是怎样的?",
"小说中的热血场景有哪些?"
]
bad_questions.json
[
"少年歌行和哈利波特有什么关系?",
"小说中有外星人吗?",
"萧瑟喜欢吃什么食物?",
"作者周木楠的生日是哪天?",
"少年歌行的故事发生在2023年吗?",
"小说中有没有描写现代科技?",
"红衣少年会使用手机吗?",
"素衣女子的衣服是哪个品牌的?",
"小说中有没有提到COVID-19?",
"少年歌行的故事是不是发生在美国?",
"作者写这本书用了多长时间?",
"小说中有没有出现汽车?",
"故事里的角色会上网吗?",
"少年歌行的电影版什么时候上映?",
"小说中有没有描写太空旅行?"
]
替换正反提示词
整理的还不错,我们也只是测试,所以不需要太多提示词。将以上2个json 文件上传/root/huixiangdou/resource 目录替换原来的2个json文件
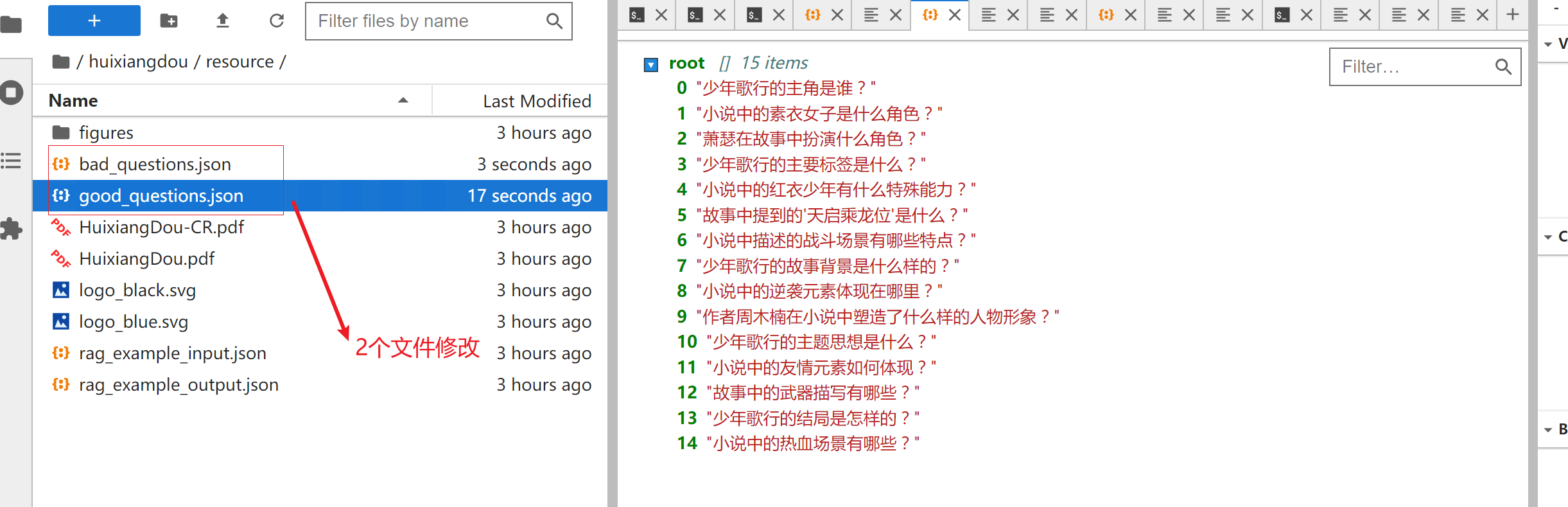
修改测试代码
打开/root/huixiangdou/huixiangdou/service/feature_store.py 第297行test_reject 代码中把原来提示词换成我们上面的部分提示词
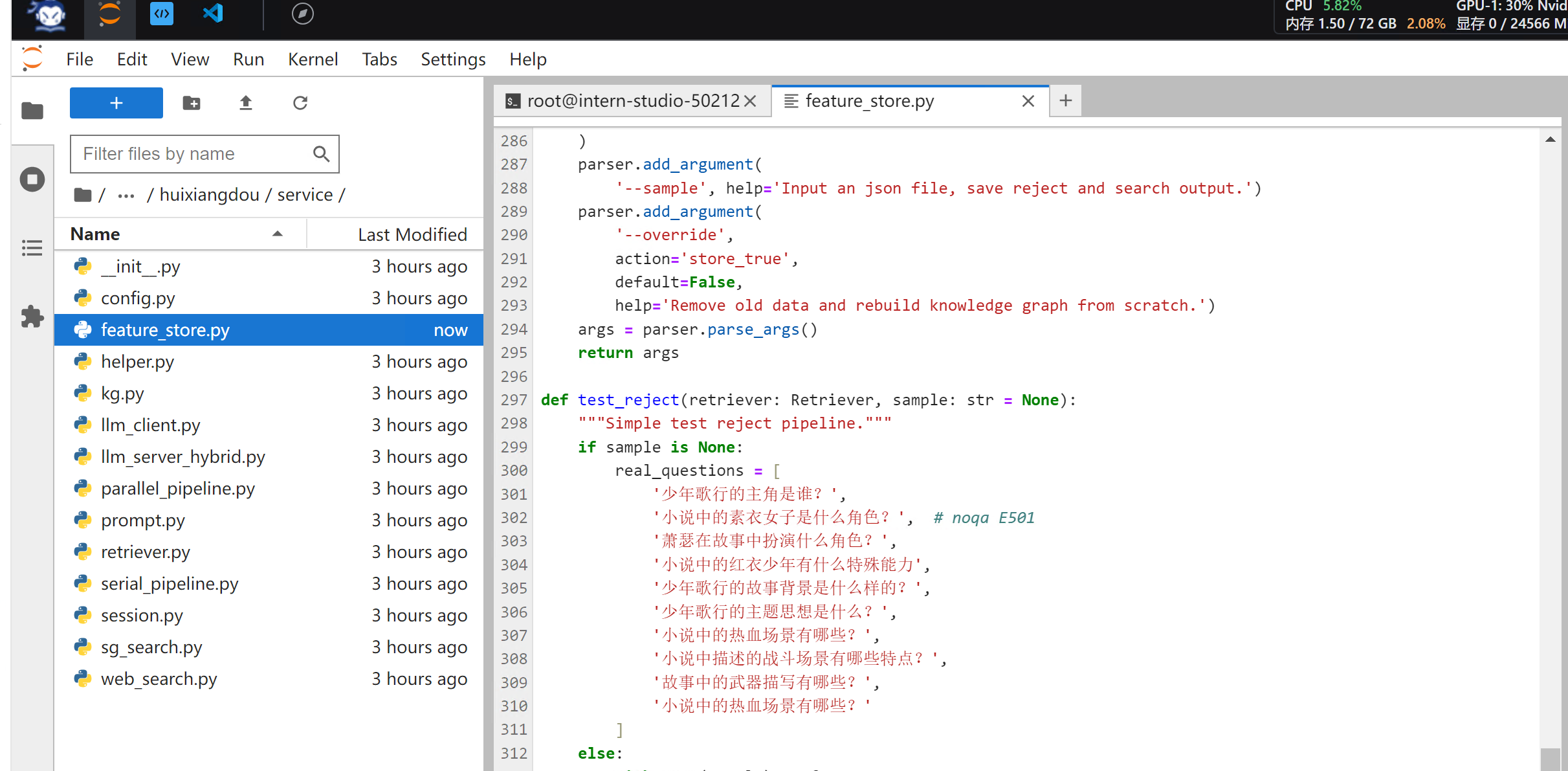
重新创建知识库
我们将节选小说上传到/root/huixiangdou/repodir 目录下
输入如下命令重新创建知识库
conda activate huixiangdou
cd /root/huixiangdou
python -m huixiangdou.service.feature_store
Gradio UI 界面测试
我们参考上面的内容执行如下代码把Gradio UI 运行起来
conda activate huixiangdou
cd /root/huixiangdou
python3 -m huixiangdou.gradio
启动完成后,页面输入127.0.0.1:7860` 打开茴香豆助手测试页面
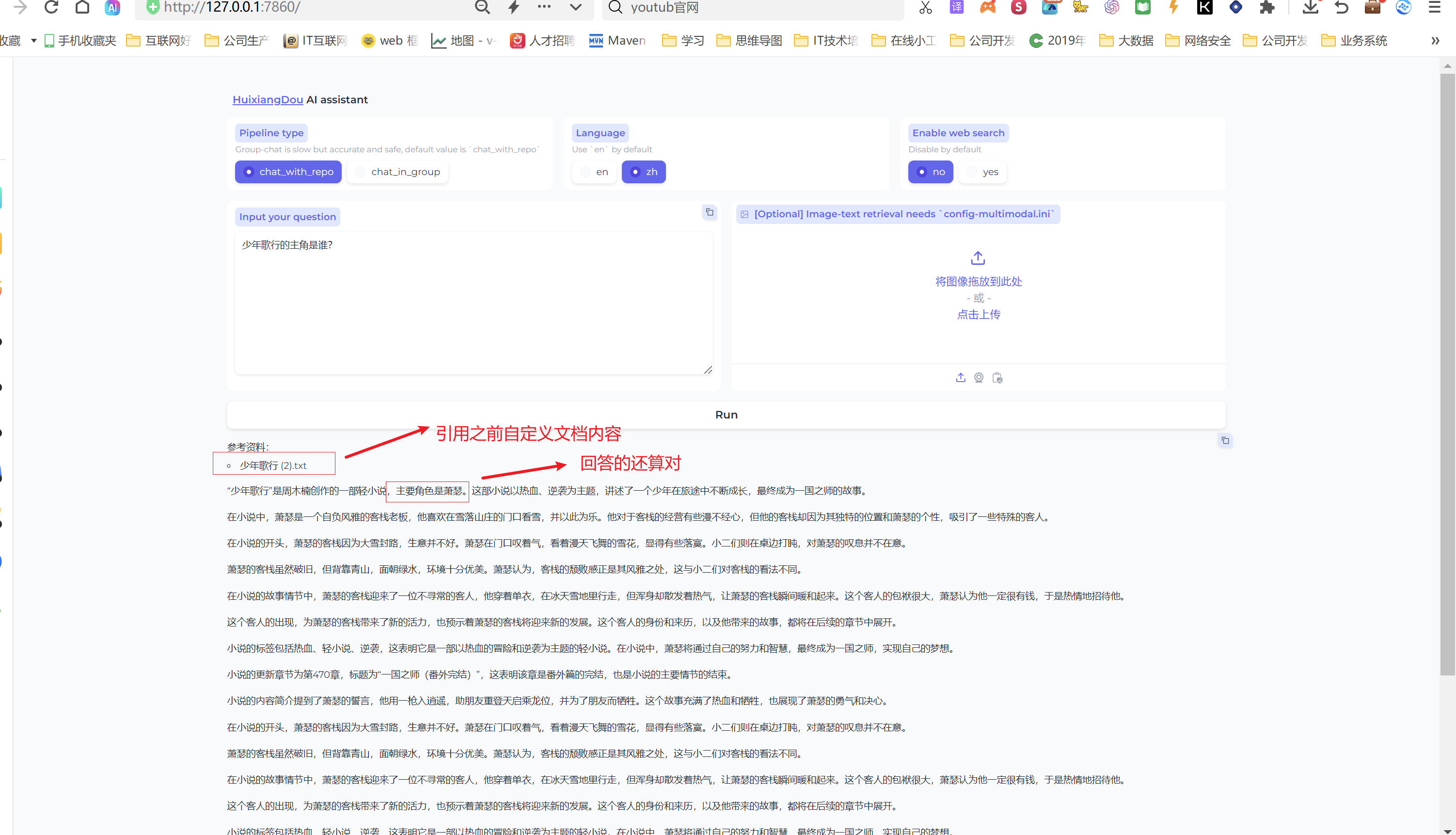
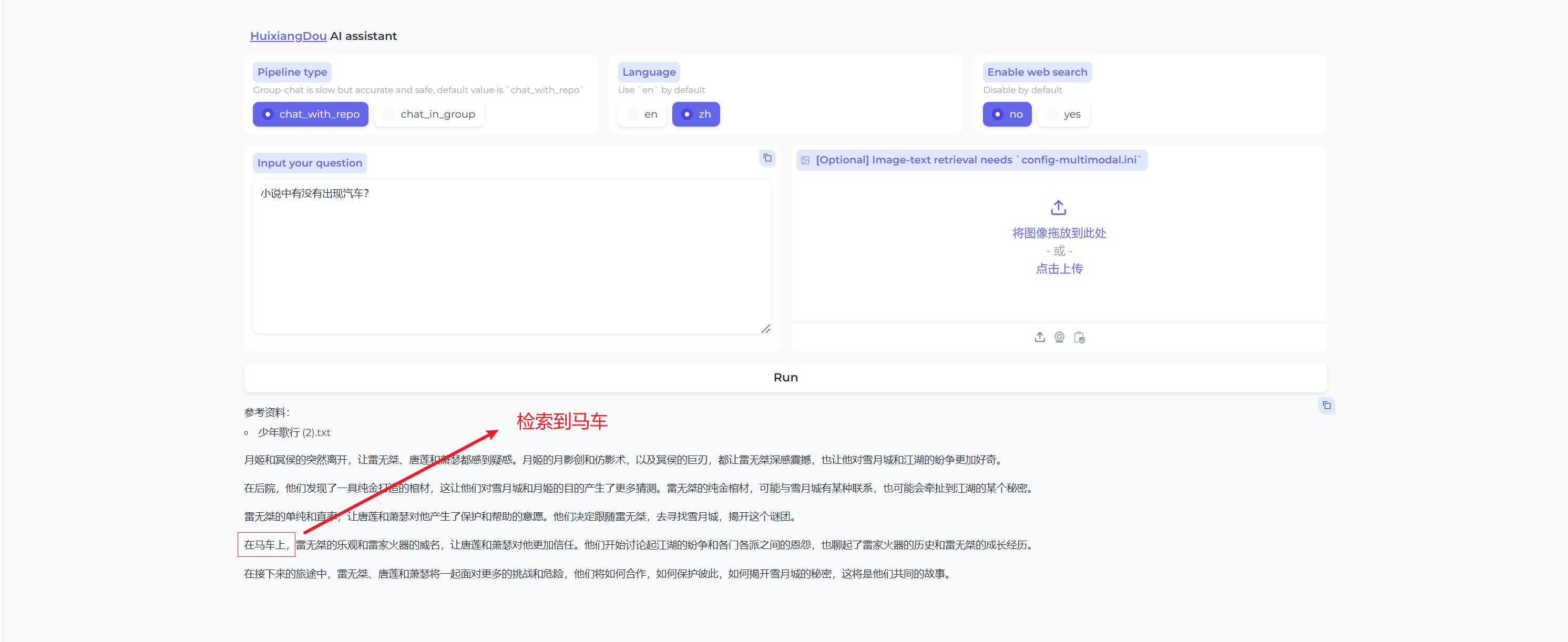
在测试一个问题
以上就是我们使用茴香豆创建自己知识库来实现文档检索功能。感兴趣的小伙伴可以参考文档自己做一遍。







![[Leetcode 105][Medium] 从前序与中序遍历序列构造二叉树-递归](https://i-blog.csdnimg.cn/direct/329b862731984da3a04749f81e544f5e.png)
![汇川技术|Inoproshop软件菜单[在线、调试]](https://i-blog.csdnimg.cn/direct/7240f9ca9ce7410fab2b9184d804fca4.png)