最近语言大模型(LLM)异常火爆,一个非常特别的开源社区正在探索在消费级硬件上微调、提供服务和进行推理的最佳方式。为满足上述需求,出现了许多出色的开源代码库,以HuggingFace生态系统为中心,这些代码库还包括FastChat、Axolotl和LLama.cpp。
本文专注于分布式训练策略的具体细节,特别是DeepSpeed和FSDP,并总结了以多GPU和多节点训练为主的不同高效微调方法。显然,当前的趋势是,我们会使用越来越多的计算资源,因此将需要更多GPU来运行更大的模型。
在这种情况下,理解这些主题尤为重要,尤其是当你想要将几个3090家庭服务器升级到具有8个A100 80GB的GCP容器时,另外,这对于试图微调自己的语言模型的初创公司或企业来说也很重要。大型科技公司进行的实际大规模训练涉及大量资料,这些内容大部分来自主导了BLOOM-176B训练的Stas Bekman,GPU匮乏的用户(即GPU-poors)关注这些资料的意义并不大。
本文从多个优秀的资源中整合了各种观点,着重讨论了HuggingFace生态系统的相关内容,并考虑了一些来自在线资源以及作者本人在2023年暑期实习中所学到的实际情况。
综上,本文希望能够回答以下问题:
\1. 在分布式训练和性能优化方面,我们应该关注什么?DeepSpeed和FSDP在背后是如何运作的?
\2. 不同的分布式训练策略需要的硬件设置和注意事项?
\3. 各种有效的微调优化器以及可能存在的权衡?
\4. 一些可以覆盖所有重要微调优化的实用指南,用以在多GPU和多节点设置中训练大模型。
\5. 现在可以使用的开源代码库以及各自的优缺点?
(本文作者为加州大学圣地亚哥分校计算机科学系的硕士研究生Sumanth R Hegde。以下内容由OneFlow编译发布,转载请联系授权。原文:
https://sumanthrh.com/post/distributed-and-efficient-finetuning/ )
1
分布式训练
分布式训练涵盖的范围非常广泛,因此本文无法覆盖所有内容。在训练/微调LLM时,我们通常会面对超10亿参数的庞大模型和大规模数据集(超1万亿词元的预训练数据集,超100万词元的监督微调数据集)。我们最终的目标是尽快完成训练,以最大化吞吐量,即希望能够每秒处理尽可能多的样本。
LLM在训练过程中需要大量的GPU显存,不仅仅因为模型参数数量庞大(例如,Falcon 40B拥有40亿参数,在BF16格式下仅模型权重就需要约74GB显存),还因为优化器状态所需的显存——例如,使用普通的AdamW优化器,每个参数需要12个字节来存储模型权重的副本、动量和方差参数。因此,我们需要智能的分布式训练策略,以确保每个GPU worker只需处理部分训练状态和数据。
主要的并行策略有:
\1. 数据并行(Data Parallelism, DP):每个GPU worker获取整个小批量数据的一部分,并在该部分数据上计算梯度。然后在所有worker上对梯度进行平均,以更新模型权重。在其最基本的形式中,比如PyTorch中的DDP,每个GPU存储模型权重的副本、优化器状态以及所处理数据部分的梯度。
\2. 模型并行/垂直模型并行(MP):在模型并行中,模型被分割成多个部分,每个部分被放置在不同的GPU上,这被称为垂直模型并行。举例来说,如果有一个包含12层的单一模型,该模型的不同层会被分别放置在3个不同的GPU上。

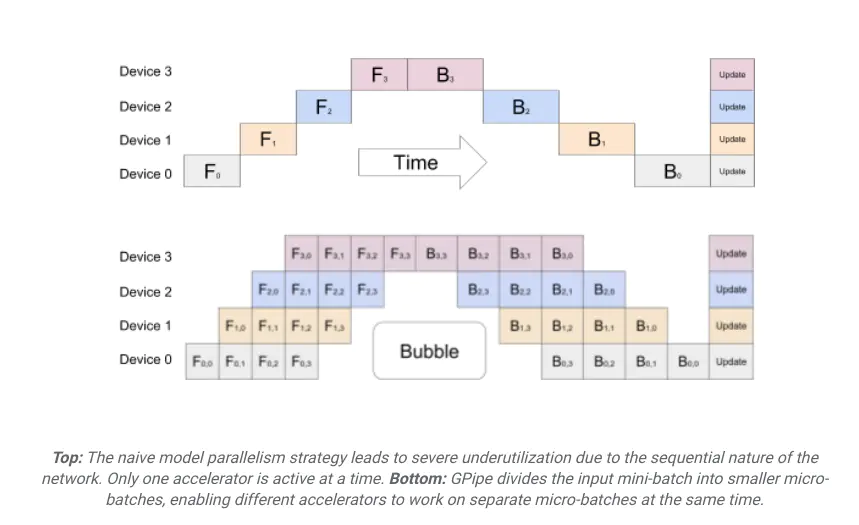
在朴素模型并行(naive model parallelism)中,所有GPU在处理相同的数据批次时都需要等待前一个GPU完成计算,然后才能处理数据。这意味着在任何给定时刻,除了一个GPU外,其他GPU实际上都处于闲置状态(因此称为“朴素”)。为改善这种情况,可以使用流水线并行(PP),这种方式通过让不同微批次数据的计算重叠,给你带来并行的错觉。这类似于计算机架构中的经典流水线。参见以下关于GPipe的博文:
为了在多个加速器上实现高效训练,GPipe将模型划分到不同加速器,并自动将一个小批次的训练样本分成更小的微批次。通过在这些微批次上进行流水线式的执行,各个加速器可以进行并行计算。
\3. 张量并行(TP):在张量并行中,每个GPU通过在GPU worker之间对模型进行水平切片,仅处理张量的一部分。每个worker处理相同的数据批次,计算他们所拥有权重部分的激活值,并交换彼此需要的部分,每个worker计算他们所拥有权重部分的梯度。
我们可以将上述各种并行策略结合起来,以实现更好的吞吐量增益。接下来,我们将更详细地了解两种用于数据并行训练的改进方法:零冗余优化器(Zero Redundancy Optimizer)和密切相关的全切片数据并行策略(Fully Sharded Data-Parallel strategies)。
注释:我将使用术语“GPU worker”来指代在每个GPU上运行的各个进程。虽然这种表述并不十分准确,但在数据并行设置中,这样说更方便,更易于理解。
拓展阅读:
-
多个GPU上的高效训练:https://huggingface.co/docs/transformers/perf_train_gpu_many
-
如何在多个GPU上训练大模型?
https://lilianweng.github.io/posts/2021-09-25-train-large/
2
ZeRO驱动的数据并行
这是当前最高效、最热门的分布式训练策略之一。DeepSpeed的ZeRO是一种数据并行处理形式,它极大提高了内存效率,其主要思想是利用数据并行训练中的内存冗余和快速GPU间通信的最新改进来提高吞吐量,根据不同阶段,会增加一些通信量。实际上,ZeRO有两个组成部分:ZeRO-DP(数据并行)和ZeRO-R(残留内存)。DeepSpeed团队还提出了一些后续优化措施,这进一步提升了ZeRO的吸引力,例如ZeRO-Offload/Infinity(将计算卸载到CPU/NVMe磁盘)和ZeRO++(实现了灵活的多节点训练和量化权重)。
ZeRO-DP的可视化图表如下(来自DeepSpeed的博客文章):
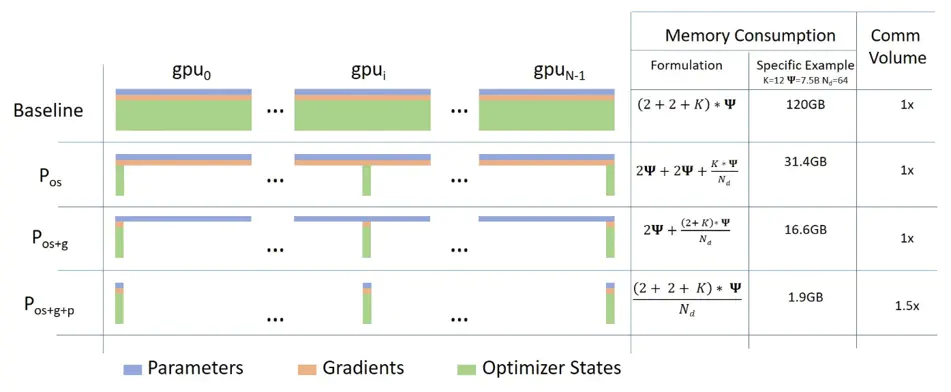
在64个GPU上训练7.5B参数模型时,模型表现如下:
\1. 基准:PyTorch DDP
\2. ZeRO 第一阶段/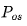 :内存减少4倍(特定示例),与基准的通信量相同(没有额外的GPU间通信)。
:内存减少4倍(特定示例),与基准的通信量相同(没有额外的GPU间通信)。
\3. ZeRO 第二阶段/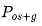 :内存减少8倍(特定示例),与基准的通信量相同。
:内存减少8倍(特定示例),与基准的通信量相同。
\4. ZeRO 第三阶段/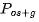 :内存减少64倍(特定示例),通信量为基准的1.5倍(这里的1.5倍针对的是不同硬件设置和模型大小)。
:内存减少64倍(特定示例),通信量为基准的1.5倍(这里的1.5倍针对的是不同硬件设置和模型大小)。
基准
PyTorch DDP实现了简单的数据并行性。每个GPU worker都有模型权重、优化器状态和梯度的副本。后向传播后,各个worker间的梯度会被平均化(即全局归约(all-reduce)),并且模型权重会被更新。
关于通信量的注释:为理解ZeRO的好处,我认为,重要的是要明确通讯量的确切含义。典型DP中存在一个全局归约步骤,其中每个worker都会发送出其所拥有的梯度数组,然后接收其他worker的梯度数组,以获得平均值。下文摘自ZeRO论文:
当前最先进的全局归约实现采用了两步操作:第一步reduce-scatter,它在不同进程上的数据的不同部分会被归约。第二步是all-gather,其中每个进程都在这一步中收集所有进程上的归约数据。这两步的结果就是全局归约。同时,reduce-scatter和all-gather都采用了流水线方式实现,这导致每个步骤需要Ψ个元素(对于具有Ψ个元素的数据)的总数据搬运量。因此,在标准的数据并行性中,每个训练步骤会产生2Ψ的数据搬运量。
在这种情况下,“数据”指的是我们的梯度,而进程指的是每个GPU上运行的单个worker。总而言之,我想表达的是:如果你有Ψ个参数,那么普通数据并行性将产生2Ψ通信成本。
ZeRO 第一阶段/Pos**(优化器状态分区)**
在这种情况下,只有优化器状态在GPU worker之间进行了分区/分片,而模型权重和梯度在所有worker之间进行了复制。反向传播后,需要进行一次常规全局归约,以便在所有worker间获取平均梯度值。然后,每个worker更新其分区中的优化器状态。Adam方程如下。
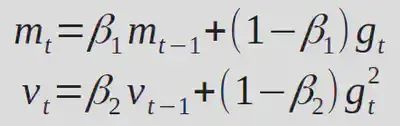
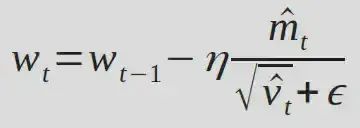
(w、g、v 和m 分别对应权重、梯度、速度和动量)。需要注意的是,这些都是逐元素操作,在计算梯度后,各个权重分片之间并没有依赖关系。
通信量:首先我们会执行一次全局归约操作,将更新后的梯度通信给所有GPU,然后,在更新各自分片的优化器状态之后,每个GPU仍需要从其他GPU获取更新后的权重。ZeRO论文并没有清楚表明这样做是否会增加通信量。在我看来,对ZeRO的第1阶段和第2阶段来说,这种实现实际上是一样的:
-
梯度的全局归约由两部分组成:reduce-scatter和all-gather。
-
在DeepSpeed ZeRO1和2中,首先进行reduce-scatter操作,在不同GPU上分别减少梯度的不同部分。接着,每个GPU计算其所管理的优化器分区对应的更新后权重,之后我们只需进行一次all-gather操作,将更新后的模型参数传播给所有其他GPU。这样就能在通信量不变的情况下,减少内存消耗。
ZeRO Stage 2 /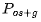 (优化器状态+梯度分区)
(优化器状态+梯度分区)
在这种情况下,优化器状态和梯度都被分区/分片到不同的worker上。这意味着,两个GPU worker在训练期间不仅要关注不同的微批次数据,还要维护模型参数子集的梯度。关键在于,每个worker都在更新其优化器状态的分区,因此对于一个worker而言,它所需的梯度(或者说,经过归约/平均的梯度)只是对应于该状态分区的梯度。至于实现方式,正如上面提到的,DeepSpeed有效地执行了reduce-scatter操作,其中每个worker对应的梯度在该worker处被平均(而不是对所有参数进行典型的all-reduce操作)。这意味着,在相同通信量下节省了更多内存,也就是说,与DDP相比,这里没有额外的数据搬运成本。
注意:在使用ZeRO Stage 1和2时,仍然需要整个模型适配单个GPU。此外,在使用RAM时,需要注意如下事项:随着进程/GPU数量的增加以及模型大小的扩展(超过40亿参数),模型初始化会占用大量RAM。ZeRO 3对此有所改进。
ZeRO Stage 3 /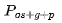 (优化器状态+梯度+参数分区)
(优化器状态+梯度+参数分区)
对我来说,这是ZeRO最有趣的阶段。除优化器状态和梯度外,第3阶段还跨worker划分了模型参数。来自DeepSpeed的可视化图表如下:
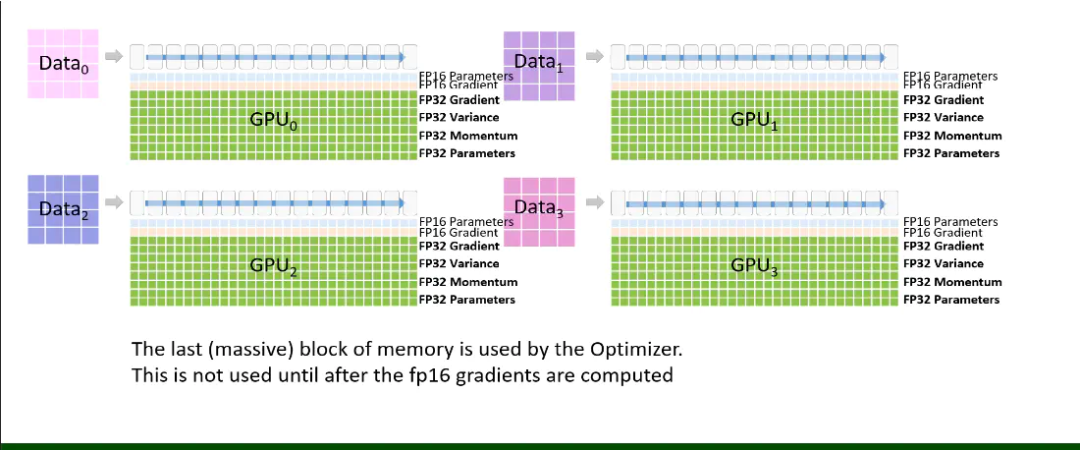
使用4个GPU实现不同训练状态的可视化
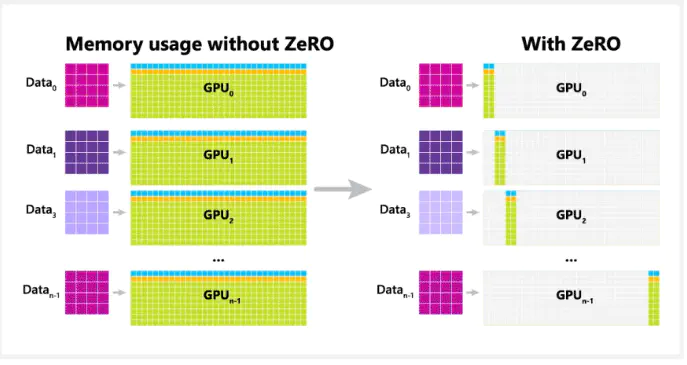
使用DeepSpeed ZeRO-3对训练状态分片
借用Stas Bekman指南中的一个例子,假设有以下3层模型和4个GPU:

使用DeepSpeed ZeRO 3,GPU的配置方式如下:

在ZeRO-3中,模型的每一层都被水平切片,每个worker存储权重张量的一部分。在前向和后向传播过程中(每个GPU worker 仍然看到不同的微批次数据),不同的GPU worker交换它们所拥有的每一层的部分(按需进行参数通信),并计算激活/梯度。
其余部分类似ZeRO Stage 2。很容易看出,ZeRO-3的通信量是基准DDP的1.5倍:在每个训练步骤中,我们需要在前向传播中额外进行一次模型参数的all-gather操作。在这个操作中移动的数据量为Ψ(每个GPU),因此总通信量为Ψ(参数all-gather)+ Ψ(梯度reduce-scatter)+ Ψ(all-gather,用于更新的参数)= 3Ψ = 1.5倍DDP。考虑到内存消耗被GPU workerN 削减,这给人留下了深刻印象。ZeRO论文的另一个关键洞察如下:
只要有足够的设备来共享模型状态,ZeRO就可以使DP适应任意大小的模型。
也就是说,只要有足够多的GPU,在进行数据并行(DP)训练时,我们就不会再受到每个GPU显存的限制(说起来容易做起来难)。
ZeRO-R
我并不想深入探讨这一话题,但ZeRO-R在ZeRO-DP的基础上,通过关注激活的内存消耗和管理内存碎片化做了改进提升。ZeRO-R通过对激活进行分区,减少了激活的内存占用。此外,它还在管理临时缓冲区方面进行了一些改进,你可以将之视为在worker间进行梯度累积和归约期间分配用于存储中间结果的内存。
ZeRO-Offload
ZeRO-Offload是一种优化技术,可以将优化器和计算从GPU卸载到主机CPU上。在2021年1月发布时,ZeRO-Offload可在1个NVIDIA V100 GPU上实现40 TFLOPS(V100 32 GB vRAM,最大吞吐量为130 TFLOPS),适用于10亿参数模型。而采用PyTorch DDP时,最大值为30 TFLOPS,适用于14亿参数模型,在不耗尽内存的情况下,这是可以运行的最大模型。将计算卸载到CPU的主要问题是,以吞吐量衡量,CPU要比GPU慢上多个数量级。ZeRO-Offload采用的这种策略是,只将较少的密集计算(<< O(MB),其中M 是模型大小,B 是批次大小)卸载到CPU,以使总计算复杂度保持不变(O(MB))。在实践中,这意味着诸如范数计算(norm calculation)、权重更新等操作可以在CPU上完成,而前向和后向传播的矩阵乘法需要在GPU上完成。ZeRO-Offload适用于ZeRO的所有阶段(1、2和3)。
这里(https://docs.it4i.cz/dgx2/introduction/)给出了用于实验的DGX-2节点规格,该节点配备了16个V100 GPU。需要注意的是,如果处于ZeRO-2设置中,ZeRO-Offload仍然会受到每个GPU可用内存的限制,即在每个GPU上容纳整个模型可能成为瓶颈。
ZeRO-Infinity
ZeRO-Infinity是ZeRO-Offload的改进版本,于2021年4月推出。它允许将计算卸载到磁盘(NVMe内存),并对CPU卸载进行了改进。研究表明,ZeRO-Infinity在一个DGX-2节点上训练时,可以适应10-100万亿参数的模型(万亿级别!)。ZeRO-Infinity通过同时利用CPU和NVMe内存来实现这一点。以下是论文中的可视化图表:
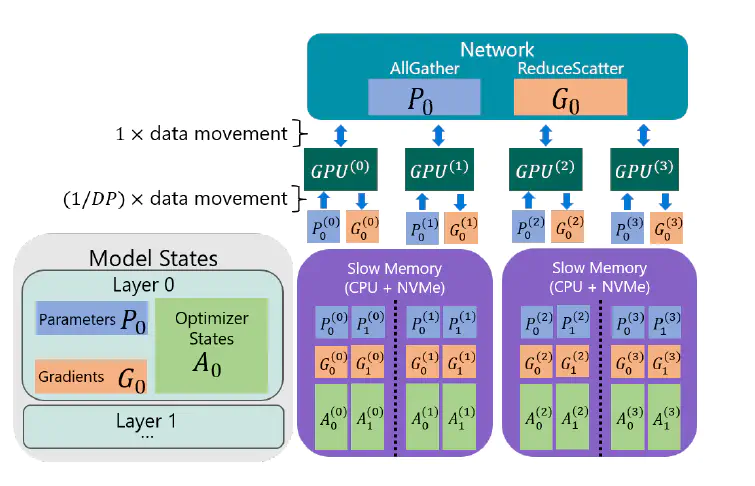
以上是ZeRO Infinity在4个数据并行排布(GPU)上的截图,描述了反向传播期间的状态。分区/分片的参数从慢速内存(CPU+ NVMe)移动到GPU,然后被收集起来形成完整的层。在梯度计算之后,它们被聚合、重新分区,然后卸载到慢速内存。分区/分片的参数从慢速内存(CPU+ NVMe)移动到GPU,然后被收集起来形成完整的层。在梯度计算之后,它们被聚合、重新分区,然后卸载到慢速内存。
与ZeRO-Offload不同,ZeRO-Infinity是基于ZeRO-3专门构建的。作者在32个DGX-2节点、512个GPU上对模型速度进行了评估。结果表明,ZeRO-Infinity可训练高达20万亿参数的模型,每个GPU的吞吐量可达49 TFlops,而3D并行等替代并行策略可训练的模型规模要小40倍。ZeRO-Infinity要想成为有竞争力的选择,需要满足一些带宽要求,即NVMe-CPU和CPU-GPU通信。
关于ZeRO-Offload和ZeRO-Infinity之间的差异,以下是DeepSpeed团队的评论:
DeepSpeed首先包含了ZeRO-Offload的卸载功能,ZeRO-Offload是一个用于将优化器和梯度状态卸载到ZeRO-2内的CPU内存的系统。ZeRO-Infinity是ZeRO-3可以使用的下一代卸载功能。相比ZeRO-Offload,ZeRO-Infinity能够处理更多数据,能更有效地利用带宽,并且能更好地实现计算和通信重叠。
默认情况下,使用ZeRO-3进行卸载时,ZeRO-Infinity的优化机制会自动生效;使用Stage 1/2进行卸载时,ZeRO-Offload会生效。
拓展阅读:
\1. ZeRO-Offload/Infinity 教程: https://www.deepspeed.ai/tutorials/zero-offload/
\2. ZeRO-Offload - 十亿级模型训练大众化 : https://arxiv.org/abs/2101.06840
\3. ZeRO-Infinity - 打破GPU内存墙,实现超大规模深度学习: https://arxiv.org/abs/2104.07857
ZeRO++
ZeRO++是DeepSpeed团队对ZeRO-3的最新改进。主要改进如下:
\1. 量化权重(qwZ):通过将模型权重量化为int8,将all-gather参数通信量减少一半。
\2. 层次划分 (hpZ):层次划分是一种混合分区方案,适用于DeepSpeed ZeRO 3的多节点设置。在这种情况下,模型参数会在一个节点内分片,然后在不同节点之间复制。这意味着,与典型的ZeRO-3全面运行相比,我们无法节省相同数量的内存,但可以避免昂贵的节点间参数通信开销,从而提高整体吞吐量。我更倾向于FSDP中使用的 “混合分片(hybrid sharding)” ,而非 “层次划分”,下文讨论FSDP时,会再次深入讨论这个问题。
\3. 量化梯度(qgZ):通过在梯度reduce-scatter操作中使用int4量化数据替换fp16,可以节省更大通信量。(回顾:这是发生在ZeRO 2/3阶段,针对分片梯度进行的梯度聚集和平均)
总体而言,与ZeRO-3 相比,ZeRO++通过这三项改进将通信量减少了4倍。
拓展阅读:
\1. ZeRO:训练万亿参数模型的内存优化: https://arxiv.org/abs/1910.02054
\2. ZeRO教程: https://www.deepspeed.ai/tutorials/zero/
\3. ZeRO++:针对巨型模型训练的超高效集体通信: https://arxiv.org/abs/2306.10209
\4. ZeRO++教程: https://www.deepspeed.ai/tutorials/zeropp/
3
全分片数据并行
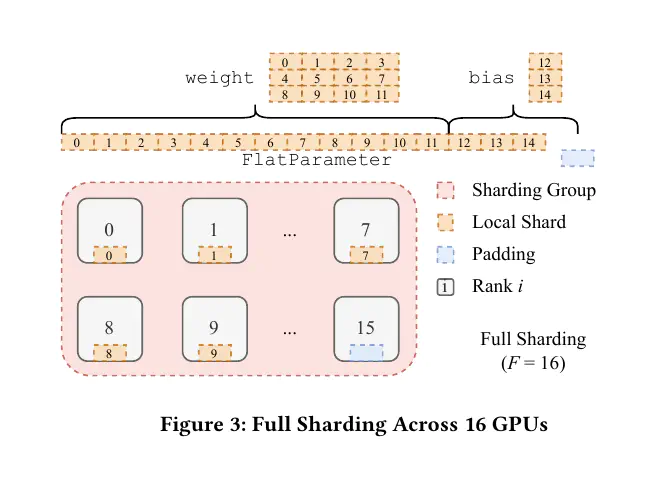
全分片数据并行(FSDP)是另一种旨在提高内存效率、减少通信计算开销以提高吞吐量的数据并行技术。FSDP的分片策略基于Xu等人和ZeRO的想法。FSDP有两种分片策略:全分片(Full Sharding)和混合分片(Hybrid Sharding)。
全分片
这基本上与ZeRO-3相同,其中参数、优化器状态和梯度被分片到各个worker或设备上。下图来自FSDP博客,展示了两个设备之间不同操作的低层次可视化。
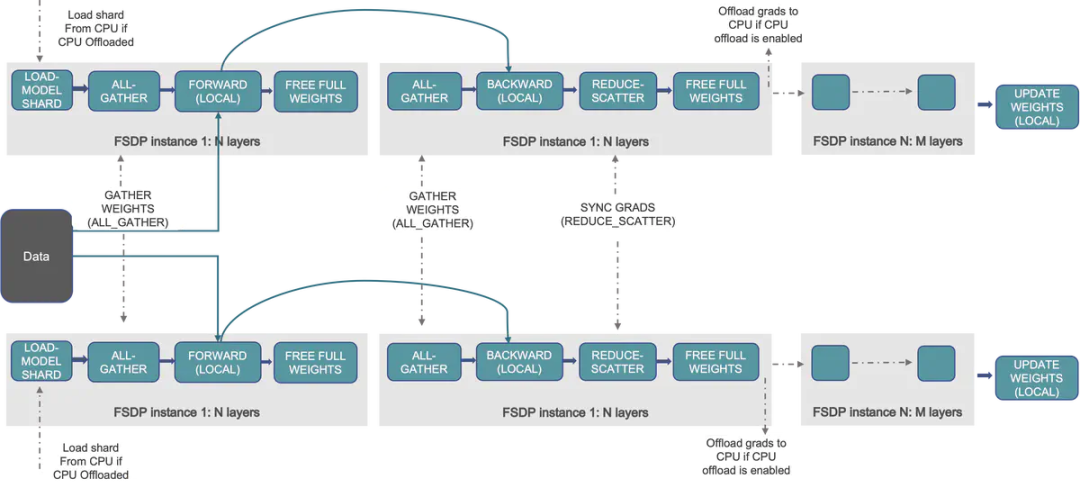
正如你所看到的,每个worker/设备仅持有权重的子集,并且可以按需进行参数通信来计算中间激活和梯度。以下是来自PyTorch的FSDP教程:
“在前向传播中
运行all_gather从所有rank中收集全部分片,以恢复该FSDP单元中的完整参数
运行前向计算
丢弃刚刚收集的参数分片
在后向传播中
运行all_gather从所有rank中收集全部分片,以恢复该FSDP单元中的完整参数
运行后向计算
运行reduce_scatter以同步梯度
丢弃参数”
此处,“rank”指的是一个GPU worker。
下图是另一篇论文中有帮助的可视化图,特别是对比了全分片和混合分片:
混合分片
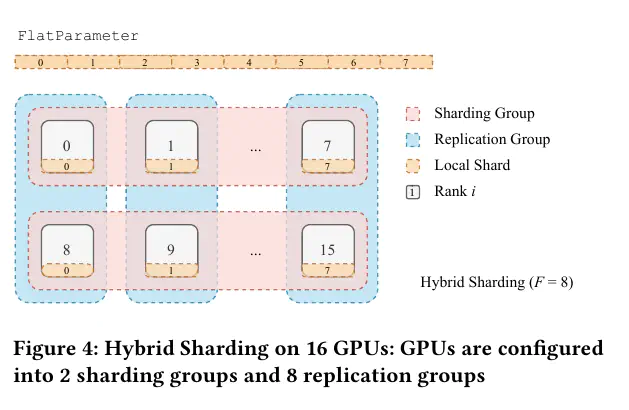
混合分片包括分片和复制。这意味着,对于给定数量的worker/ GPUW,分片仅在大小为F 的子集之间发生,并在不同子集之间复制。
具体来说,假设我们想要跨2个节点进行多节点训练,每个节点在GCP中都是一个a2-ultragpu-8g节点。每个节点有8个A100 GPU,共有16个worker。那么可以使用混合分片在每个节点内部对模型参数进行分片,然后在节点之间复制。这意味着,在每个前向/反向传播中,每个节点内部有类似的all-gather和reduce-scatter操作,即从其他GPU获取模型参数(节点内部),并计算中间激活和梯度。然后,我们需要进一步在节点之间进行另一个all-gather操作,以获得在该训练步骤中处理的总小批量数据的平均梯度值。当我们被迫处理分片参数(即不能选择ZeRO 2/1时),并处于多节点设置中时,这种方法尤其有吸引力。这类似于ZeRO++中的“层次划分(hierarchical partitioning)”。
4
实现
如何使用DeepSpeed和FSDP?
DeepSpeed ZeRO/FSDP的主要优势之一在于,当实际上只处于数据并行设置时,我们可以在数据+张量并行的情况下节省内存,提升吞吐量。这意味着,我们无需进行任何临时的架构更改,也无需通过混乱的.to()设备转换或任何定制操作来改变前向传播过程。因此,ZeRO/FSDP可以在不同的架构中运行,实现良好的集成效果。ZeRO是在微软的DeepSpeed库中实现的,并已整合到Accelerate库中。而FSDP则是PyTorch本身的一部分,同样也整合到了Accelerate库。因此,我们可以使用Trainer API(其后端使用了Accelerate)中的任一策略,或者直接使用Accelerate。
流水线并行和张量并行?
目前,流水线并行(PP)和张量(TP)并行需要进行架构更改和/或调整模型的前向传播过程。如果想要在DeepSpeed中使用流水线并行,那么则需要更改模型的架构定义。
此外,由于Transformers库为每个模型实现了数十种特性,这使得对其进行集成变得非常复杂。当然,我们已经可以通过device_map="auto"实现朴素模型并行,但在使用多个GPU时,这是一种非常糟糕的策略,它只在模型无法适配单个GPU的情况下才有意义(否则最好还是只使用单个GPU)。如果确实需要流水线并行和张量并行,那么目前最好的选择是使用Megatron-LM,并专注于他们支持的模型(如BERT、GPT-2、T5、Llama)。
此外,还可以在Megatron-DeepSpeed中使用ZeRO支持的DP、DeepSpeed PP和Megatron TP,但这些方法仅适用于基于BERT、GPT-2和T5的模型训练。Stas Bekman曾试图在HuggingFace中实现流水线并行和张量并行,但未能成功。以下摘自Stas Bekman的博文:
Transformer现状:目前的情况是,没有一个模型支持完全的流水线并行(full-PP)。GPT2和T5模型具有朴素模型并行(naive MP)支持。目前的主要障碍是无法将模型转换为nn.Sequential,并将所有输入转化为张量。因为目前模型中包含许多特性,这些特性使转换变得非常复杂,因此我们需要删除特性才能实现转换。
我们已经尝试了开源,但这个问题太过棘手,尽管已向Stas Bekman求助,但仍未能解决。
DeepSpeed ZeRO和FSDP会继续存在吗?
我认为,由于其易用性,DeepSpeed的ZeRO和PyTorch的FSDP很可能会被保留下来,或者说只会被非常相似的策略取代。在语言大模型领域,变化是唯一的不变。
随着新模型、架构、注意力实现、位置嵌入改进等的出现,能够在几小时内用一个架构替换另一个架构,并在10M个样本上训练40亿+参数的模型变得非常重要。即使新的DP + PP + TP策略最终能够实现比ZeRO驱动的DP更高的吞吐量,可能也不会有太多的采纳量。出于相似原因,我认为,DeepSpeed ZeRO和FSDP会获得更多关注度,它们的吞吐量将进一步优化,甚至可能出现针对纯数据并行类别的定制计算集群配置。因此,如果我们坚持仅采用DP,结果不会太差。
(当然,这与OpenAI、Anthropic等所进行的超大型语言模型训练无关)
5
高效微调
这又是一个热门话题!接下来我将简要列举一些最受欢迎的优化方法:
混合精度
对于大模型训练而言,这是一个不言而喻的选择。简而言之,权重、激活和梯度以半精度格式存储,同时你有一个FP32/单精度格式的“主副本”权重。两种常用的半精度格式是BF16(由Google Brain开发的“Brain Float 16”)和FP16。FP16需要额外的损失扩展以防止梯度下溢,而BF16似乎不存在这些问题。
拓展阅读:
- 混合精度训练:https://arxiv.org/abs/1710.03740
- 性能和可扩展性:如何适配更大的模型并进行更快的训练:https://huggingface.co/docs/transformers/v4.18.0/en/performance
参数高效微调(PEFT)
PEFT旨在通过冻结大部分模型权重,将其中的子集/少量额外参数设置为可训练,从而在微调过程中降低内存需求。LoRA是最流行的PEFT,其中对模型参数进行了低秩版本的权重更新微调。
另一种有效的PEFT是IA(3),它在基于Transformer体系结构中的键、值和前馈层中注入可训练向量。对于LoRA和IA(3),添加的权重/向量可以与基础权重合并,这意味着,在推理时无需进行额外的计算(加法/乘法)。不足之处在于,其性能可能不及完全微调时的性能。然而,这一情况已迅速改变,实际上,只要你向所有线性层添加可训练权重,基于LoRA的方法可以达到完全微调的性能。
就IA(3)而言,在我对GPT-2(770M)这样的小型模型进行的实验中,发现IA(3)可以在可训练参数的数量不到1/10的情况下与LoRA的性能相匹配。然而,这仍需要更多社区实验,尤其是在LLama-2-7B或Falcon-40B的规模上。
拓展阅读:
-
语言大模型的低秩调整:https://arxiv.org/abs/2106.09685
-
PEFT中的LoRA概念指南:https://huggingface.co/docs/peft/conceptual_guides/lora
IA3概念指南:
-
PEFT中IA3的概念指南:https://huggingface.co/docs/peft/conceptual_guides/ia3
-
使用LoRA高效微调T5-XXL:https://www.philschmid.de/fine-tune-flan-t5-peft
Flash Attention
Flash Attention是一种快速(速度得到提升!)、内存高效(节省内存!)、精确(无需近似!)、IO感知(通过考虑GPU内存的不同级别进行读/写操作!)的注意力算法。使用 Flash Attention 2(自2023年7月份推出),你可以在A100 80GB上获得220 TFLOPS以上的性能(其最高性能为315 TFLOPS)。换句话说,当Flash Attention 1在2022年中问世时,它拥有当时可达到的最佳吞吐量,最高可达124 TFLOPS。此外,根据我们之前研究的部分DeepSpeed ZeRO论文,预计在2021年,Tesla V100的可实现峰值吞吐量约为70 TFLOPS!
目前,Flash Attention支持Ampere、Ada或Hopper NVIDIA GPU(如A100、RTX 3090、H100等),且仅支持半精度数据类型bf16/fp16。要在Transformers中使用Flash Attention,只需对LLama和Falcon进行一处更改(将use_flash_attention=True 传递给AutoModel)。对于其他模型,则需手动将forward中使用的注意力函数改为Flash-attention的高吞吐量版本,不过这一点正在快速取得进展。Flash Attention很快将集成到PyTorch的 scaled_dot_product_attention 中,这样就不必再依赖猴补丁(monkey patches)。(这本应在v2.1版本中实现,但有望在不久的将来实现)
Flash Attention v1.0集成在Optimum中也已经有一段时间了,但不能使用填充词元(padding tokens),这使得它的作用非常受限。
拓展阅读:
- ELI5:Flash Attention:https://gordicaleksa.medium.com/eli5-flash-attention-5c44017022ad
- FlashAttention-2:更快的关注力与更好的并行性和工作分区 https://tridao.me/publications/flash2/flash2.pdf
梯度/激活检查点
通常情况下,每次在前向传播中,所有中间激活都会被保留在内存中,因为它们在计算反向传播时是必需的。梯度/激活检查点(checkpointing)是一种通过仅保留部分中间激活,并根据需要重新计算其余部分来减少内存消耗的技术。其中牵涉到的权衡是额外的重新计算时间。据HuggingFace提供的经验法则,梯度检查点会使训练减慢约20%。当模型层数为N 时,激活的内存需求从*O(N)*下降到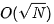 。当然,因为总内存中存储的不仅仅是激活,所以内存消耗可能没有那么大。
。当然,因为总内存中存储的不仅仅是激活,所以内存消耗可能没有那么大。
拓展阅读:
- 《将大型网络适配到内存中》:https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9
- 《性能和可扩展性:如何适配更大的模型并加速训练》:https://huggingface.co/docs/transformers/v4.18.0/en/performance
量化
量化是黑客的最爱,主要有两种量化方法,下面我将简要介绍:
-
后训练量化(PTQ):旨在实现高效推断。LLM.int8(),GPTQ就属于这一类。
-
量化感知训练:从术语的原始意义出发,这意味着从一开始就使用量化的权重和激活来训练模型,以备后续推理使用。这正是我们想要的 ——一种使用量化参数进行训练的策略。QLoRA属于这一类(在某种程度上,因为它将量化整合到训练过程中)。QLoRA主要将基础预训练模型权重量化为8/4bits,然后以浮点半精度/全精度训练额外的LoRA参数。这是一种十分强大的策略,能在单个拥有48GB vRAM的GPU上微调超过600亿参数的模型。当然,需要注意的是,其吞吐量会大大降低。原因很简单:每当计算给定层的激活时,都会发生额外的去量化步骤(具体数字取决于硬件设置。例如,你可能能够在8个A100上运行DeepSpeed ZeRO 3的Falcon-40B训练时不进行量化,在这里单独使用量化毫无意义,即使你可以获得更好的批次大小。不过,在只有2个A100的情况下就不一样了)。
补充信息:完整的QLoRA论文值得一读。他们的方法除了能在消费级GPU上训练65B参数的模型(这是当时最大的开源语言模型)之外,该论文还表示,基于LoRA的训练可以与完全微调相媲美(他们增加了更多可训练的层,但通过对基础权重进行量化使其比原始LoRA配置更高效),并且数据集的质量在监督微调中至关重要(450K FLAN样本比9K高质量人工标注样本更糟糕)。
拓展阅读:
- QLoRA:https://arxiv.org/abs/2305.14314
- 对Transformer模型进行量化:https://huggingface.co/docs/transformers/v4.34.0/en/main_classes/quantization
梯度累积
梯度累积是一种提高有效批次大小的方法,尽管吞吐量会有所下降(有时甚至会下降至零)。
比如,假设你的批次大小为2,梯度累积步长为4。使用梯度累积,你会在每个训练步骤中进行常规的前向和后向传播,但是,你会在每4个训练步骤中调用一次优化器步骤(在PyTorch中为optimizer.step())。这意味着,在4个步骤中会进行梯度累积,然后使用这8个样本的平均梯度更新模型权重。这样一来,你的批次大小增加了,这使得权重更新变得更加平稳,但内存消耗保持不变。实际上,使用多GPU/多节点训练的梯度累积可以增加批次大小,同时加快训练速度。因为在正常训练中,梯度在本地(由GPU处理的批次)被局部平均,并且每个训练步骤都需执行一次全局归约。而使用梯度累积,你可以在更大的间隔(即gradient_accumulation_steps)上执行这一全局归约操作。减少此类全局归约可降低worker间的通信负担(可能还包括节点间的通信),进而提高训练速度。
拓展阅读:
- 使用DeepSpeed API进行训练:https://www.deepspeed.ai/training/
是否应该一直尝试增加批次大小?
阅读完我们讨论的所有内容之后,这是一个吸引人的问题。答案是:否!要记得,我们的目标是尽可能快地使用现有硬件,训练出可能的最优神经网络。因此,即使你只使用了可用GPU内存的75%(例如在A100中为60GB/80GB),也可能已经达到了系统中的最大吞吐量。这意味着,进一步增加批次大小将导致相应时延的增加,结果是吞吐量不会提高,甚至可能降低。此外,即使你有一套强大的硬件配置来训练40B+参数的模型,仅通过上述内存优化来增加批次大小还不够,因为这可能会影响收敛性能。因此,很难针对大模型展开一项良好的研究。
在Transformer时代之前有一篇论文(https://openreview.net/forum?id=H1oyRlYgg)显示,大型批次大小可能会影响泛化性能。DeepSpeed提到,你可以找到更好的超参数/优化器选择,使更大型批次大小发挥作用,正如1-cycle 学习速率调度指南(https://www.deepspeed.ai/tutorials/one-cycle/)所证明的那样。DeepSpeed的一位作者还提出,为使大规模训练运行达到目标收敛速率,全局批次大小通常是固定的。总之,更大型的批次大小并不一定更好!
到底多大的批次大小算大?
便于参考,BLOOM-176B预训练采用了366B个词元,全局批次大小为2048。尤其是在微调阶段,目前还不清楚批次大小大到何种程度才会影响模型的收敛。
6
实践指南
总结
综上所述,以下是尝试在1000万以上规模的数据集上对10-100B+模型参数进行实验和微调的实用指南(我有DeepSpeed的经验,尚未使用FSDP,所以我将重点放在这上面):
-
默认情况下使用BF16/ FP16。BF16基本不需要其他配置参数,通常不会出现任何溢出问题(相反,FP16可能会因不同的损失扩展因子导致不同的结果,并且由于动态范围较小,可能出现更多的溢出问题),因此非常方便。
-
使用LoRA,并将可训练参数添加到所有线性层。如果你想紧密遵循QLoRA,可在这里(https://github.com/artidoro/qlora/blob/7f4e95a68dc076bea9b3a413d2b512eca6d004e5/qlora.py#L248)使用他们的实用函数。
-
如果你GPU支持Flash Attention,那么可以使用它。目前,Flash Attention 2可在HuggingFace的Llama 2和Falcon上使用,其他模型可能需要进行调整。
-
使用梯度/激活检查点。这将略微降低吞吐量。如果你使用了Flash Attention,可能就不需要梯度检查点。参考Flash Attention论文(另见Tri Dao的建议,https://github.com/EleutherAI/gpt-neox/pull/725#issuecomment-1374134498)。

-
在你的数据加载器中使用高效的采样器,如多重包采样器(multi-pack sampler)。
-
如果你有多个GPU,首先尝试使用BF16+LoRA+梯度检查点+DeepSpeed ZeRO 3。
-
GPU内存有限时,可使用量化。QLoRA风格的训练目前仅适用于DeepSpeed ZeRO 1/2。因此,即使它在模型参数方面非常高效,但在ZeRO 1/2中仍有参数冗余,并且吞吐量也会减少。
-
随着GPU的增加(如8个V100或A100),DS ZeRO-3成为了最佳选择。DS ZeRO-2也不错,但你可能会受到CPU内存限制的影响(在模型初始化期间),因为模型参数会在所有工作节点上被复制。例如,如果要在具有8个GPU的节点上使用Falcon-40B模型,那么CPU内存需要超过1.5TB,而云容器实例(AWS、GCP等)很少有这么大的内存,所以会受到限制。当然,在家用服务器上可能不适用,因为家用服务器没有用于GPU间通信的NVLink。DS ZeRO-3具有更多的GP间通信,因此NVLink很重要。
-
在小规模多节点设置中,启用了层次分区(或FSDP的混合分片)的DeepSpeed ZeRO-3似乎是最佳选择。如果你有Infiniband互联,大多可以使用普通的DeepSpeed ZeRO-3,并用于更大模型。
-
如果在上述所有优化之后仍然批次大小不足,应该使用梯度累积。对于大模型和多GPU/多节点设置,梯度累积可加快训练时间。
-
如果你的GPU内存非常有限,可以激活CPU/磁盘卸载(通过硬盘,这必须是ZeRO-Infinity 的NVMe)。随着Flash Attention 2的出现,我们需要对纯GPU训练和GPU + NVMe/CPU卸载之间的吞吐量差距进行另一项研究。我怀疑现在这个差距比以前大得多,因此只有在真正受限的情况下才进行卸载(这就是为什么这是要尝试的最后一个优化)。ZeRO-Infinity 优于ZeRO-Offload,对于这一点你必须使用ZeRO Stage 3。
-
计算有效的批次大小,并相应调整超参数。一个通用的指导原则是,随着有效批次大小的增加,要增加学习率。正如OpenAI的微调文档中提到的,即使对于100B+的模型,这似乎仍然成立。
-
最后,在开始训练时,使用 htop 监控RAM使用情况(有时会出现RAM OOM问题),同时使用 nvidia-smi 确保GPU没有被数据预处理拖慢(你应该争取接近100%的GPU利用率,即使GPU内存使用较少)。
关于超参数的更多内容:以下为学习率缩放的相关评论。事实证明,在预训练过程中,随着模型的增大(比如100B+),即使使用了更大的批次大小,通常来说,我们还是应该降低而非增加学习率,这一点可以在OpenAI的GPT-3论文和BLOOM论文中得到证实。要建立对这种模式的直觉十分困难,因此我们只能采取非常实证的方法,如果实验结果与之相悖,就迅速更新所有先验知识。
补充指南
在Transformers的文档中提供了许多关于性能和可扩展性的有用技巧。如果你关心在家搭建和管理服务器时可能遇到的问题,或者NVLink的具体作用,又或者想深入了解内存管理,这些内容都非常有价值。Stas Bekman系列(https://github.com/stas00/ml-engineering)收录了许多与调试和性能相关的实用提示,可能会有所帮助。
7
关于DeepSpeed和FSDP的更多内容
使用DeepSpeed ZeRO-3进行多节点训练
对于普通ZeRO-3,你需要确保跨节点的参数通信不会成为一个巨大的瓶颈,否则,即便使用两个节点,吞吐量的提升可能也非常有限。通过Stas Bekman的调查,我们对需要具备怎样的跨节点网络有了清晰的认识:
对于大小为M 的模型,有N 个节点,每个节点有G 个GPU,每个节点在每个训练步骤中发送约48*M/Nbits 的数据。即便是对于两个8xA100节点,配备一个40B参数模型,每个节点在每个训练步骤中通信的数据量就达到了120GB!对于大规模训练(64GPU+),确实需要具备1000Gbps的InfiniBand互连。对于较小规模的多节点训练,可选择100-400Gbps的带宽。在亚马逊EC2 P4d实例(配备了8个A100,用于机器学习训练的节点)上,通常使用弹性网络适配器(Elastic Fabric Adapter,EFA)作为跨节点的网络接口,根据规格,你可以获得高达400Gbps的网络带宽,这相当不错!实际上,你获得的确切带宽约为340Mbps,因此应该规划使用规格中列出的最大带宽的80-85%。用于AWS P5实例的EFA v2配备了H100,速度快了整整8倍。
要测算你所获得的跨节点网络带宽,可使用Stas Bekman的实用函(https://github.com/stas00/ml-engineering/blob/9a51114f8377350bfbf1764f23feac441e865401/multi-node/all_reduce_bench.py)。这个函数专门用于对所有归约操作进行基准测试,因此能够准确测试训练过程中所能看到的情况。
建议:在没有Infiniband的情况下,最好使用ZeRO++和层次分区(hpZ)。要实现这一点,你需要将zero_hpz_partition_size 配置参数设置为每个节点的GPU数量/rank。例如,如果你使用两个节点进行训练,每个节点有8个A100 GPU,那么zero_hpz_partition_size 将设置为8。
Accelerate/Transformer 支持:目前尚不清楚加速DeepSpeed集成是否支持层次分区(hpZ)。表面上看,应该支持,因为加速应该整合DeepSpeed ZeRO的所有功能,而hpZ只是DeepSpeed配置文件中的一个参数更改。我已经提了一个issue(2023年10月1日),如有需要,我会更新这篇帖子。
对于FSDP,你将使用混合分片策略(HYBRID_SHARD)。对于多节点训练(至少是小规模的,没有Infiniband的情况下),这似乎是一个不错的选择,但有用户通过艰难的方式发现了这一点。Accelerate已经支持带有混合分片的FSDP。
DeepSpeed 内存需求
当你拥有新的基础架构设置,并希望尝试DeepSpeed时,绝对应该使用DeepSpeed的内存估算器。
DeepSpeed ZeRO 1/2
deepspeed.runtime.zero.stage_1_and_2.estimate_zero2_model_states_mem_needs_all_live(model,
num_gpus_per_node=1, num_nodes=1, additional_buffer_factor=1.5)
使用默认缓冲因子(这是一个简单地扩展所有CPU和GPU内存估算的估算因子),对于一个拥有3B参数的模型,在拥有1个节点和8个GPU的环境中,你将得到以下结果,来自于DeepSpeed文档:
python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage_1_and_2 import estimate_zero2_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("t5-3b"); \
estimate_zero2_model_states_mem_needs_all_live(model, num_gpus_per_node=8, num_nodes=1)'
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 8 GPUs per node.
SW: Model with 2851M total params.
per CPU | per GPU | Options
127.48GB | 5.31GB | offload_optimizer=cpu
127.48GB | 15.93GB | offload_optimizer=none
以Falcon-40b为例,使用ZeRO 1/2所需的CPU RAM大于1.5TB。你无需实际运行训练/微调代码来测试这一点,只需使用上述模型和硬件设置运行上述命令,就会得到一个估算。对于FSDP,我没有找到类似的内存估算器,因此可直接使用DeepSpeed ZeRO-3对FSDP的全分片估算。
注意:再补充一点关于CPU RAM不足的情况。这可能很难调试,因为你的进程将在日志中没有任何信息的情况下失败。添加PyTorch分布式调试标志(NCCL_DEBUG=INFO, TORCH_DISTRIBUTED_DEBUG=INFO )也无济于事,因为这是一个RAM问题。我只是在初始训练阶段通过监视htop(如前文所述)发现了这一困难。
DeepSpeed ZeRO 3
python deepspeed.runtime.zero.stage3.estimate_zero3_model_states_mem_needs_all_live(model, \
num_gpus_per_node=1, num_nodes=1, additional_buffer_factor=1.5)
在一个节点上,每个节点有8个GPU的硬件设置下,对于一个包含3B参数的模型,使用以下命令可以估算参数、优化状态和梯度所需的内存:
python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("t5-3b"); \
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=8, num_nodes=1)'
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 8 GPUs per node.
SW: Model with 2851M total params, 32M largest layer params.
per CPU | per GPU | Options
71.71GB | 0.12GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
127.48GB | 0.12GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
63.74GB | 0.79GB | offload_param=none, offload_optimizer=cpu , zero_init=1
127.48GB | 0.79GB | offload_param=none, offload_optimizer=cpu , zero_init=0
1.47GB | 6.10GB | offload_param=none, offload_optimizer=none, zero_init=1
127.48GB | 6.10GB | offload_param=none, offload_optimizer=none, zero_init=0
这也让你对不同的卸载策略和初始化有了一个概念!使用zero_init=1 时,模型权重将以一种内存可扩展的方式初始化,一旦分配后,权重将立即在你的worker之间分区。当zero_init=0 时,CPU RAM需求可能会飙升(对于10B+模型和多个GPU来说可能会达到TB 级别),因此你绝对应该使用zero_init=1。在多GPU设置中使用CPU卸载也会增加大量RAM的需求,并且可能导致RAM OOM。使用估算器,之后如果确实需要,如CPU RAM不足的话,可以切换到NVMe卸载。
使用Accelerate
Accelerate 旨在提供一个统一的界面,用于启动各种分布式训练运行,同时为你提供在纯 PyTorch中编写代码的灵活性。目前看来,如果你打算在FSDP和DeepSpeed之间切换同一段代码,可能会有一些注意事项。例如,对于FSDP,你必须在实例化优化器之前调用 accelerator.prepare(model)。我不确定相同的方法是否适用于 DeepSpeed(对于 DeepSpeed,你可以对一切进行*.prepare()* 调用)。还有一些其他注意事项,这里就不展开了,但可以查看以下Accelerate的文档。
拓展阅读:
1.使用Accelerate进行FSDP:https://huggingface.co/docs/accelerate/usage_guides/fsdp
2.使用PyTorch FSDP对Llama 2 70B进行微调:https://huggingface.co/blog/ram-efficient-pytorch-fsdp
8
开源代码库
短短几个月内,开源代码库已取得了长足进步。在这里,我主要想回答“如果我想立即开始使用开源代码库进行微调,可以使用什么?应该牢记什么?”等问题。如往常一样,细节决定成败。接下来我将总结FastChat和Axolotl的平台功能,这是两个最实用、最受欢迎的平台。
FastChat
FastChat是一个用于微调、服务和评估LLM-based chatbots from LMSys的平台。其功能包括:
Serving
你可以使用FastChat为Llama、Falcon、WizardLM等模型提供服务。(支持的模型列表)添加新模型进行推理/服务似乎非常简单,并支持因果模型(如 Llama)和序列到序列模型(如 T5)。他们还支持使用CPU卸载和不同的量化方案等服务。在幕后,FastChat使用了出色的vLLM库进行高效推理,这也是另一个LMSys开源项目。
微调
-
支持微调的模型有Llama、T5和Baichuan。如有错误,烦请指正。主要的微调脚本仅适用于Llama模型,并有针对Llama特定的魔法数字。此外,还有针对T5和Baichuan模型的额外微调脚本。Falcon模型的训练支持仍有待解决。
-
专门针对(单轮/多轮)对话数据监督微调,以训练聊天机器人。在类似FLAN的数据集上,用(instruction, response)对进行指令微调是有可能的(单轮对话),但不可能混合因果语言建模数据集等其他数据集格式,或者在多个数据集上进行训练。
-
支持LoRA和基于QLoRA的训练。提供的DeepSpeed配置是参考配置,适用于低资源环境(例如,1个V100 32GB用于微调Llama-13B),因此会默认启动CPU卸载。请确保根据你的硬件设置进行修改。更多参考信息请参阅训练文档。
-
FastChat使用Trainer API,并且与几乎所有可用的开源训练包一样,在训练和评估中仅支持单一的同质数据集(在这种情况下,还必须是对话数据)。这意味着,你可以看到组合数据集的训练损失和评估损失,但在监控运行时不会看到其他信息。
评估
FastChat的评估包以MT-bench为基础,是一个基于多轮对话的评估数据集。在评分方面,他们使用LLM作为评委,可以利用GPT-3.5或GPT-4等更强大的语言模型对模型输出评分。
Axolotl
Axolotl是一个用于微调语言模型的大规模开源项目,具有以下显著特点:
-
支持Llama、MPT、Falcon等各种因果语言模型。目前尚不支持序列到序列模型。
-
具有多种格式,支持在多个数据集上训练。在我看来,对Axolotl来说,这是一个极其重要的功能。数据集格式的完整列表太过庞大,但你可以在类似FLAN的指令微调数据集、类似ShareGPT的基于对话的数据集以及简单的基于文本补全的数据集上进行训练(用于因果语言建模的纯文本/代码)。Axolotl还支持预标记数据集。
-
支持LoRA、QLoRA,以及多包采样器,该采样器将相似长度的序列打包在一起,以避免在填充词元上浪费计算。
-
Axolotl还使用Trainer API,并具有许多用于自定义评估和记录的功能。你可以在MMLU上进行评估,或者在本地基准数据集上记录训练期间的损失/准确性。
-
此外,Axolotl还支持FSDP和DeepSpeed,主要是因为它们只需让Trainer处理这一部分。Flash-Attention也适用于Llama、BTLM和新的Mistral等其他模型。
-
因为在Trainer上定制起来比较困难,所以Axolotl不支持对不同任务(如MMLU和MATH)进行评估,不能分开可视化损失曲线。
-
对此,我有一个小小的疑问,除 prediction_step 和 training_step 等方法之外,Axolotl最终几乎定制了Trainer的每个部分。如果他们已经可以使用 torch.distributed.gather ,我想知道为什么不直接从一开始就用纯PyTorch + Accelerate编写所有代码,这样本就可以避免冗余。Trainer还提供了十几种优化器以供选择,但监督微调只需要其中的一小部分。
实用的微调指南
HuggingFace近期发布的几篇值得阅读的微调指南:
-
在2个8xA100-ultra-80GB节点上使用PEFT和FSDP对Llama 2 70B进行微调:https://huggingface.co/blog/ram-efficient-pytorch-fsdp
-
在2个8X100-ultra-80GB节点上使PEFT和DeepSpeed对Falcon 180B进行微调:https://medium.com/@sourabmangrulkar/falcon-180b-finetuning-using-peft-and-deepspeed-b92643091d99
-
在1个8xA100-ultra-80GB节点上使用PEFT和DeepSpeed对Falcon 180B进行微调:https://www.philschmid.de/deepspeed-lora-flash-attention
9
超大型模型训练
首先,在搭载8枚A100显卡的单一节点上,我们可以训练多大的模型。通过上述优化措施,目前我们可以在搭载8枚A100-80GB显卡的DGX节点上微调Falcon 180B。根据HuggingFace的指南(https://www.philschmid.de/deepspeed-lora-flash-attention),你可以在153分钟内,使用15000个样本,在dolly数据集上对一个包含180亿参数的模型进行3轮微调,其中有效批次大小为64,序列长度为2048个词元。由于文本块是作为预处理步骤进行的,因此不知道准确的吞吐量数值,当然我们也需要估算每个训练步骤所需的时间(因为总训练时间包括了评估和检查点所需的时间),但每秒吞吐量可能大于5个样本,对于180B参数的模型来说,这是相当不错的表现。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。