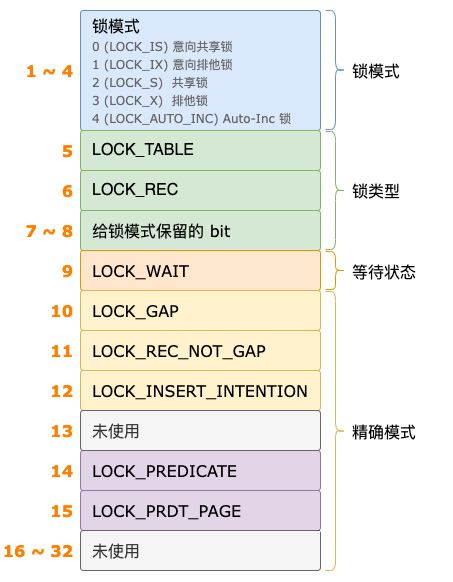
均值漂移算法(Mean Shift Algorithm)是一种基于密度的非参数聚类算法,其原理主要基于核密度估计和梯度上升方法。以下是均值漂移算法原理的详细解析:
1. 基本思想
均值漂移算法的基本思想是通过迭代地更新数据点的位置,使得数据点向密度较高的区域移动,最终聚集成簇。算法假设不同簇类的数据集符合不同的概率密度分布,目标是找到任一样本点密度增大的最快方向(即Mean Shift方向),并将样本点移动到这个方向上,直到收敛到局部密度最大值。
2. 算法流程
均值漂移算法的流程大致如下:
初始化:选择数据集中的点作为起始点,并定义一个窗口(或称为核)的大小。这个窗口用于计算每个数据点周围的密度。
计算偏移向量:在窗口内,计算每个数据点与窗口中心之间的偏移向量。这些偏移向量表示了数据点相对于窗口中心的位置变化。
计算权重:根据偏移向量的距离,计算每个数据点的权重。通常使用高斯核函数来衡量距离,距离窗口中心越近的点权重越大。
更新窗口中心:根据数据点的权重加权平均,计算新的窗口中心位置。这个过程是沿着密度增加的方向移动窗口中心,即实现梯度上升。
迭代与收敛:重复步骤2至步骤4,直到窗口中心位置不再发生显著变化或满足其他收敛条件。收敛到相同点的样本被认为是同一簇类的成员。
3. 带宽(Bandwidth)的影响
带宽是均值漂移算法中的一个重要参数,它决定了窗口的大小。带宽的选择对聚类结果有很大影响:
如果带宽设置得太小,算法可能会收敛到过多的局部最大值,导致聚类结果过于细碎。
如果带宽设置得太大,一些簇类可能会合并成一个大的簇类,导致聚类结果过于粗糙。
因此,选择合适的带宽是均值漂移算法应用中的一个关键问题。
4. 应用场景
均值漂移算法由于其非参数化的特性,可以处理任意形状的簇类,并且不需要预先指定簇类的个数。这使得它在许多领域都有广泛的应用,如图像分割、目标跟踪和密度估计等。
5. 优缺点
均值漂移算法的优点包括:
不需要设置簇类的个数。
可以处理任意形状的簇类。
算法参数较少,且结果较为稳定。
然而,均值漂移算法也存在一些缺点:
对于较大的特征空间,计算量可能非常大。
带宽参数的选择对聚类结果有很大影响,需要仔细调整。
综上所述,均值漂移算法是一种基于密度的非参数聚类算法,通过迭代地更新数据点的位置来实现聚类。它在处理复杂形状的簇类时具有优势,但在实际应用中需要注意带宽参数的选择和计算量的控制。
6. Python实现
在Python中,均值漂移算法(Mean Shift Algorithm)的实现可以通过多种方式进行,但标准的库(如scikit-learn)并没有直接提供均值漂移聚类的函数。不过,我们可以使用scikit-learn中的MeanShift类来实现类似的功能,尽管这个类实际上是基于均值漂移的概念,但它主要用于模式查找(如峰值检测)和聚类。
下面是一个使用scikit-learn的MeanShift类来实现均值漂移聚类的简单示例:
import numpy as np
from sklearn.cluster import MeanShift, estimate_bandwidth
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 生成模拟数据
centers = [[1, 1], [-1, -1], [1, -1]]
X, _ = make_blobs(n_samples=300, centers=centers, cluster_std=0.4, random_state=0)
# 估计带宽(这通常是一个重要的步骤,但这里我们直接使用一个简单的估计方法)
bandwidth = estimate_bandwidth(X, quantile=0.2, n_samples=500)
# 创建MeanShift模型
ms = MeanShift(bandwidth=bandwidth, bin_seeding=True)
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_
# 绘制结果
plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis')
plt.scatter(cluster_centers[:, 0], cluster_centers[:, 1], s=300, c='red', marker='*', edgecolor='k')
plt.title("Mean Shift Clustering")
plt.show()

在这个例子中,我们首先生成了一些模拟数据,这些数据围绕三个中心点聚集。然后,我们使用estimate_bandwidth函数来估计一个合适的带宽值,这个带宽值对于均值漂移算法的性能至关重要。之后,我们创建了MeanShift模型,并使用估计的带宽来拟合数据。拟合完成后,我们可以获取每个数据点的簇标签和簇中心。
需要注意的是,MeanShift类中的bin_seeding参数是一个重要的选项。当设置为True时,算法首先使用一种基于网格的方法来初始化簇中心(称为“bin seeding”),这可以显著提高算法的性能和稳定性。
最后,我们使用matplotlib库来可视化聚类结果,其中数据点根据其簇标签着色,簇中心以红色星号标记。
请注意,由于均值漂移算法的性质,它可能会产生一些小的簇或噪声簇,这些簇可能只包含很少的数据点。在实际应用中,可能需要根据具体情况对结果进行后处理或调整算法参数。