CopyNet 是一种特别设计的序列到序列(Seq2Seq)模型,旨在更好地处理那些在输出序列中需要直接复制输入序列中的部分或全部内容的任务。它在机器翻译、摘要生成、文本复述等任务中有广泛的应用,尤其是在输入和输出有显著重叠的场景。
以下是 CopyNet 模型在序列到序列学习中的具体应用:
1. 任务背景
在许多自然语言处理任务中,生成的输出序列常常需要复制输入序列中的一些词语或短语。例如,在机器翻译中,专有名词通常直接从源语言复制到目标语言中;在摘要生成中,一些关键短语可能需要直接引用。
2. CopyNet 模型的结构
CopyNet 的结构可以看作是对传统的 Seq2Seq 模型的一种扩展,主要包括以下几个部分:
-
编码器(Encoder):与传统的 Seq2Seq 模型类似,CopyNet 使用编码器将输入序列编码为一系列隐藏状态。
-
解码器(Decoder):解码器在生成每一个输出词时,既考虑生成新词的概率分布,也考虑直接复制输入序列中某个词的概率分布。
-
生成机制(Generation Mode):生成新词时,解码器基于传统的 Seq2Seq 方法,使用词汇表中的词语来生成输出。
-
复制机制(Copy Mode):在复制模式下,模型基于注意力机制(Attention Mechanism)从输入序列中选择一个词,直接将其复制到输出序列中。
3. 训练过程
在训练过程中,CopyNet 的目标函数是生成和复制的加权和。模型通过最大化生成词的概率和复制词的概率的和来学习。

4. 应用场景
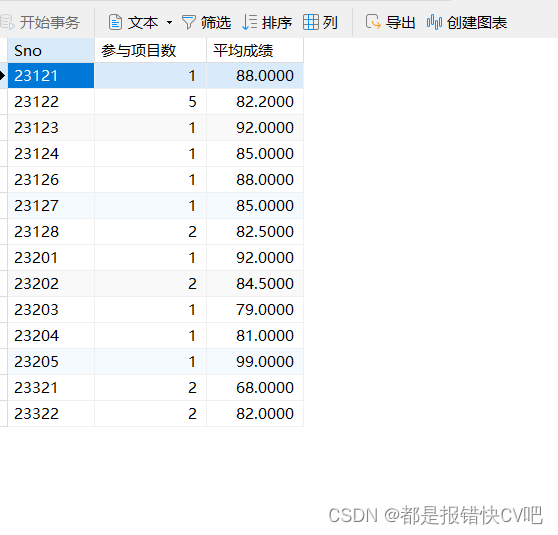
- 文本摘要:在生成摘要时,某些句子片段或重要信息可以直接从原文中复制,以确保摘要的准确性。
- 机器翻译:在处理专有名词或具有特定结构的句子时,可以直接将输入中的一些词语复制到翻译结果中。
- 问答生成:当生成回答时,问题中的一些关键术语可能需要直接复制到答案中。
5. 实现细节
在实现方面,CopyNet 可以基于现有的 Seq2Seq 框架(如 Transformer、LSTM 等)进行扩展。典型的步骤包括:
- 使用标准的编码器-解码器架构。
- 在解码阶段引入两个分支,一个用于词汇表生成,一个用于输入序列的复制。
- 将这两者结合,通过注意力机制选择是否生成或复制。
6. 优势
- 增强生成能力:CopyNet 能够平衡生成新词和直接复制输入词,使得模型在处理需要高度忠实于输入内容的任务时更加有效。
- 提高输出质量:尤其在需要保留输入中关键信息的任务中,CopyNet 生成的输出更具准确性和自然性。
7. 代码实现
实现 CopyNet 模型的 Python 代码需要使用深度学习框架(如 TensorFlow 或 PyTorch)。下面以 PyTorch 为例,展示如何实现一个简单的 CopyNet 模型。
1). 导入必要的库
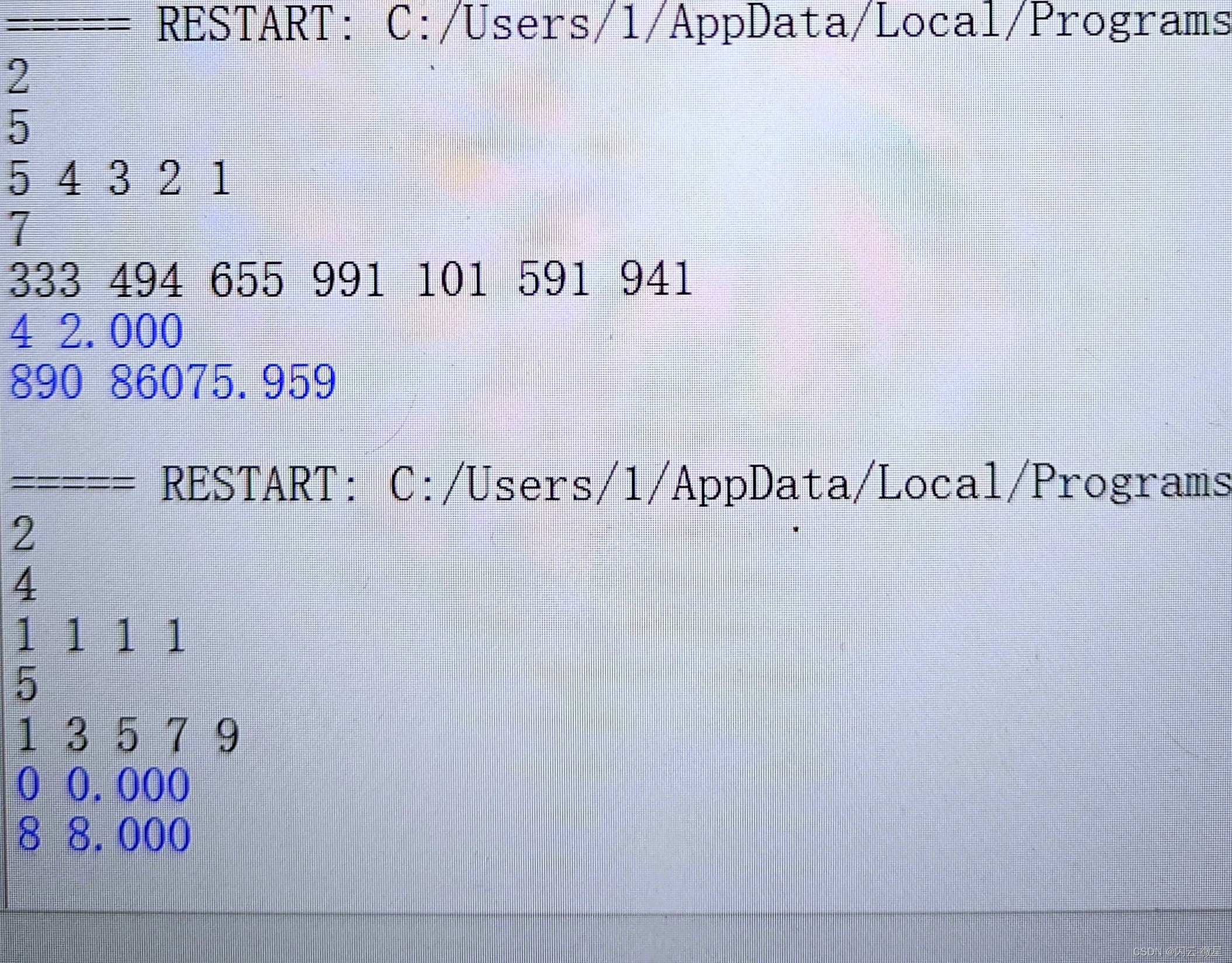
import torch import torch.nn as nn import torch.nn.functional as F import numpy as np
2). 编码器(Encoder)
class Encoder(nn.Module): def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout): super().__init__() self.embedding = nn.Embedding(input_dim, emb_dim) self.rnn = nn.GRU(emb_dim, hid_dim, n_layers, dropout=dropout) self.dropout = nn.Dropout(dropout) def forward(self, src): embedded = self.dropout(self.embedding(src)) outputs, hidden = self.rnn(embedded) return outputs, hidden
3). 解码器(Decoder)
class Decoder(nn.Module): def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout): super().__init__() self.output_dim = output_dim self.embedding = nn.Embedding(output_dim, emb_dim) self.rnn = nn.GRU(emb_dim, hid_dim, n_layers, dropout=dropout) self.fc_out = nn.Linear(hid_dim, output_dim) self.dropout = nn.Dropout(dropout) def forward(self, input, hidden): input = input.unsqueeze(0) embedded = self.dropout(self.embedding(input)) output, hidden = self.rnn(embedded, hidden) prediction = self.fc_out(output.squeeze(0)) return prediction, hidden
4). CopyNet 模型
class CopyNet(nn.Module): def __init__(self, encoder, decoder, src_pad_idx, trg_pad_idx, device): super().__init__() self.encoder = encoder self.decoder = decoder self.src_pad_idx = src_pad_idx self.trg_pad_idx = trg_pad_idx self.device = device def create_mask(self, src): mask = (src != self.src_pad_idx).permute(1, 0) return mask def forward(self, src, trg, teacher_forcing_ratio = 0.5): trg_len = trg.shape[0] batch_size = trg.shape[1] trg_vocab_size = self.decoder.output_dim outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device) encoder_outputs, hidden = self.encoder(src) input = trg[0, :] for t in range(1, trg_len): output, hidden = self.decoder(input, hidden) # Copy mechanism copy_prob = F.softmax(output, dim=1) gen_prob = F.softmax(self.decoder.fc_out(hidden[-1]), dim=1) final_prob = torch.log(gen_prob + copy_prob) outputs[t] = final_prob teacher_force = np.random.random() < teacher_forcing_ratio top1 = output.argmax(1) input = trg[t] if teacher_force else top1 return outputs
5). 训练函数
def train(model, iterator, optimizer, criterion, clip): model.train() epoch_loss = 0 for i, batch in enumerate(iterator): src = batch.src trg = batch.trg optimizer.zero_grad() output = model(src, trg) output_dim = output.shape[-1] output = output[1:].view(-1, output_dim) trg = trg[1:].view(-1) loss = criterion(output, trg) loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), clip) optimizer.step() epoch_loss += loss.item() return epoch_loss / len(iterator)
6). 评估函数
def evaluate(model, iterator, criterion): model.eval() epoch_loss = 0 with torch.no_grad(): for i, batch in enumerate(iterator): src = batch.src trg = batch.trg output = model(src, trg, 0) output_dim = output.shape[-1] output = output[1:].view(-1, output_dim) trg = trg[1:].view(-1) loss = criterion(output, trg) epoch_loss += loss.item() return epoch_loss / len(iterator)
7). 模型实例化和训练
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
HID_DIM = 512
N_LAYERS = 2
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
SRC_PAD_IDX = SRC.vocab.stoi[SRC.pad_token]
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT)
model = CopyNet(enc, dec, SRC_PAD_IDX, TRG_PAD_IDX, device).to(device)
optimizer = torch.optim.Adam(model.parameters())
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)
N_EPOCHS = 10
CLIP = 1
for epoch in range(N_EPOCHS):
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
print(f'Epoch: {epoch+1:02}')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {np.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {np.exp(valid_loss):7.3f}')
8). 推断
def translate_sentence(sentence, src_field, trg_field, model, device, max_len = 50): model.eval() tokens = [token.lower() for token in sentence] tokens = [src_field.init_token] + tokens + [src_field.eos_token] src_indexes = [src_field.vocab.stoi[token] for token in tokens] src_tensor = torch.LongTensor(src_indexes).unsqueeze(1).to(device) with torch.no_grad(): encoder_outputs, hidden = model.encoder(src_tensor) trg_indexes = [trg_field.vocab.stoi[trg_field.init_token]] for i in range(max_len): trg_tensor = torch.LongTensor([trg_indexes[-1]]).to(device) with torch.no_grad(): output, hidden = model.decoder(trg_tensor, hidden) copy_prob = F.softmax(output, dim=1) gen_prob = F.softmax(model.decoder.fc_out(hidden[-1]), dim=1) final_prob = torch.log(gen_prob + copy_prob) pred_token = final_prob.argmax(1).item() trg_indexes.append(pred_token) if pred_token == trg_field.vocab.stoi[trg_field.eos_token]: break trg_tokens = [trg_field.vocab.itos[i] for i in trg_indexes] return trg_tokens[1:]
9). 结论
上面的代码展示了如何用 PyTorch 实现 CopyNet 模型。这个实现简单展示了 CopyNet 的核心思想,包括编码器、解码器以及生成和复制机制的结合。在实际应用中,模型可能需要进一步优化和调整以适应具体任务。
通过引入复制机制,CopyNet 大大提升了模型处理具有高重叠率的序列生成任务的能力,成为自然语言处理领域中一项有力的工具。





![[CUDA编程] --- cuda线程模型](https://i-blog.csdnimg.cn/direct/bb4d621818204850812362cad272cacb.png)