前言

来自阿里巴巴和北京大学的文章:Self-Evolved Diverse Data Sampling for Efficient Instruction Tuning
link:https://arxiv.org/pdf/2311.08182
github:https://github.com/OFA-Sys/DiverseEvol
一、摘要
提升大型语言模型的指令遵循能力需要大量的sft数据集。然而,庞大的数量带来了相当大的计算负担和标注成本。为了研究一种label-efficient的指令微调方法,允许模型本身主动采样子集,引入了一种自进化机制DiverseEvol。
在此过程中,模型迭代地增强其训练子集以完善其自身的性能,而无需人类或更高级LLM的干预。数据采样技术的关键在于增强所选子集的多样性,因为模型根据其当前的embedding选择与任何现有数据点最不同的新数据点。
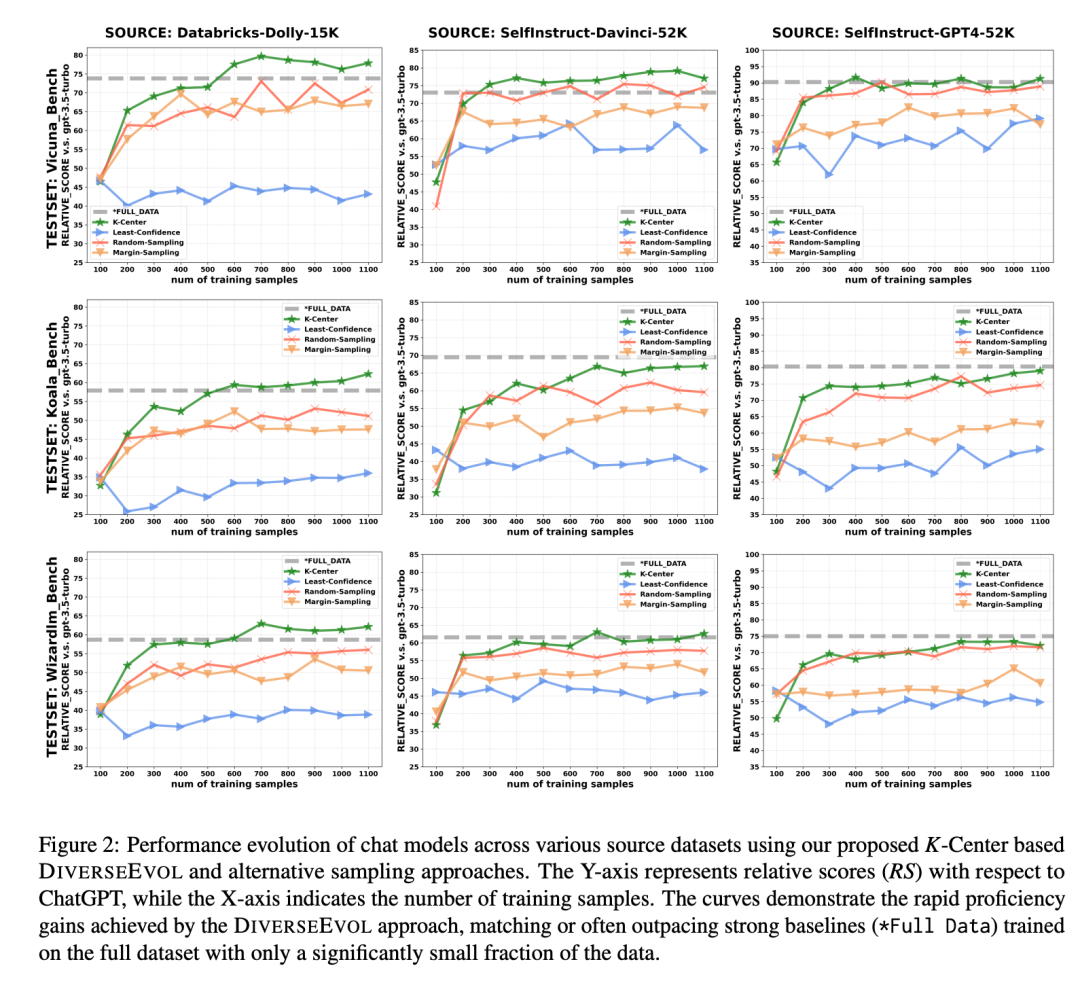
实验表明:模型在不到8%的原始数据集上进行训练,与完整数据训练相比,可以保持或提高性能。提供了实验证据来分析sft训练数据集多样性的重要性以及迭代采样方案相对于一次采样的的重要性。
二、方法
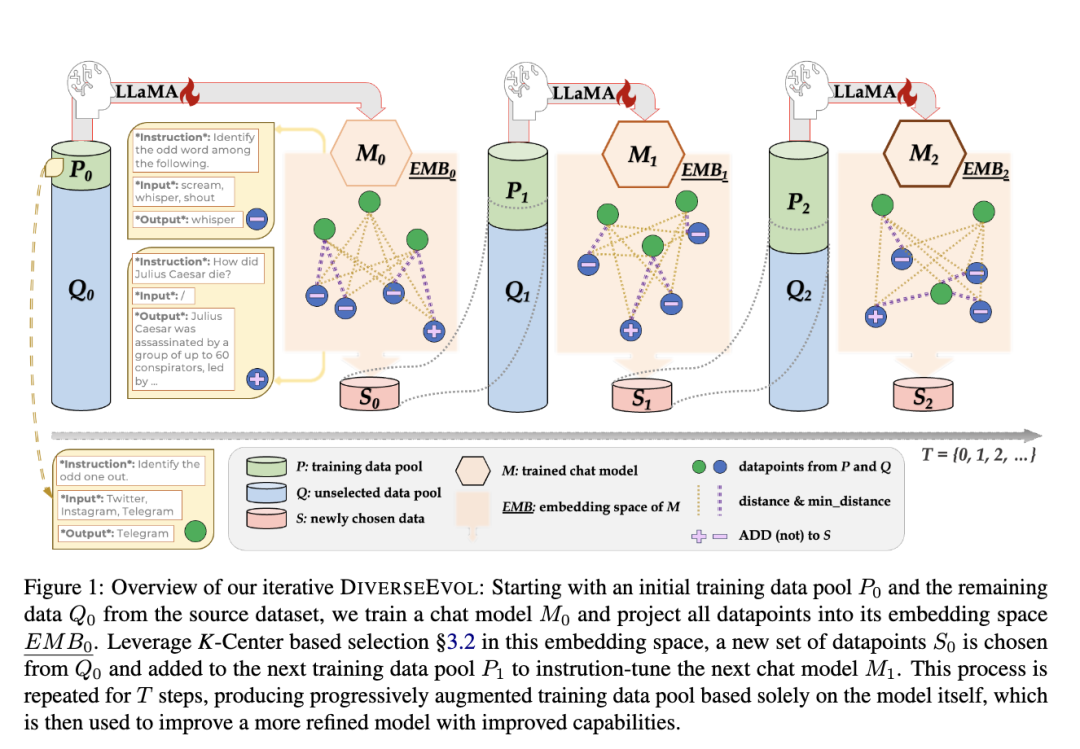
目标是将指令数据挖掘形式化为一个迭代过程,根据策略逐步从庞大的源指令数据集中提取训练集进行训练
各种公式我就不一一讲了,主要的思想就是以下几步:
2.1 步骤
首先有一个训练集,其中一个是现有的P0训练集,之外还有个待挑选的数据集Q0
通过用P0训练集进行训练模型M0
用模型M0对P0的数据和Q0的数据做向量化
挑选Q0中k个距离P0距离最远的点,当作下一批训练数据加入到P0中,成为P1,迭代1-2-3步骤即可,不断的提升模型能力
有点子boosting的意思了,不停的拟合残差
2.2 最远的点
如何判断是最远的点?
其实很多paper这块的处理基本上没啥区别,主要把数据向量化了,那就是找最能代表一块空间的点留下(尽可能让一块空间有一个数据代表),重叠的或者离的近的去掉。
这里用的是最常用的k-center算法:https://zhuanlan.zhihu.com/p/711917766
最远点:每个新数据点与现有的P中的数据之间最小距离的最大化即可,就是离目前训练集最远的点:

2.3 k-center-sampling
该算法讲解:https://zhuanlan.zhihu.com/p/711917766
最主要的思想是,可以用k个中心点来代表目前的数据分布。

三、实验
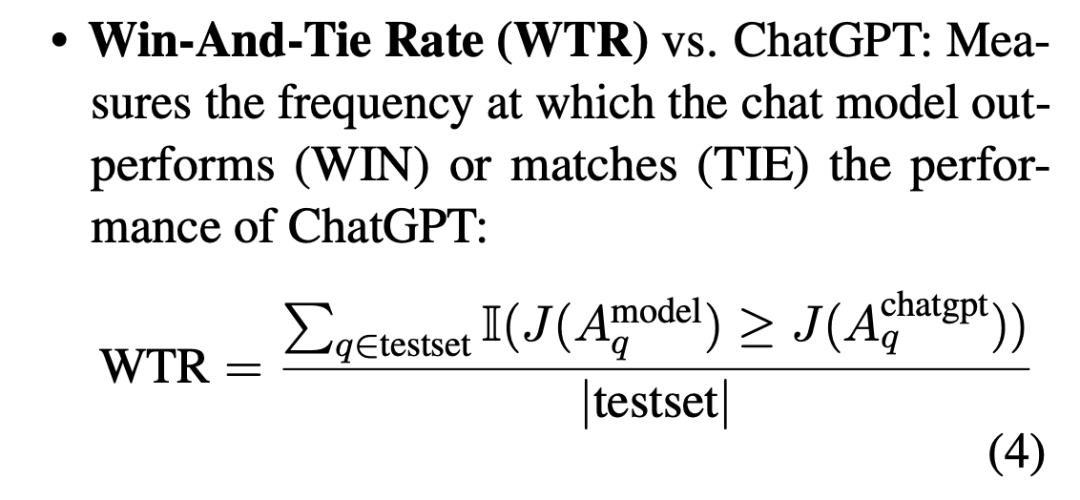
3.1 评价方式
依然是winrate-chatgpt
3.2 结果
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书