Hi,大家好,我是半亩花海。在上一个任务中,我们逐行精读baseline,掌握了利用AI工具提升学习效率,并制作了话剧连环画,初步了解Secpter WebUI。今天,我们将深入探讨微调的基本原理及其参数,旨在优化效果。同时,介绍文生图工作流平台ComfyUI,帮助实现更高度定制的文生图生成,进一步提升我们的创作和应用能力。
一、初探ComfyUI工具
1.了解ComfyUI
1.1 ComfyUI概念
GUI是 "Graphical User Interface"(图形用户界面)的缩写。简单来说,GUI就是你在电脑屏幕上看到的那种有图标、按钮和菜单的交互方式。
ComfyUI是GUI的一种,是基于节点工作的用户界面,主要用于操作图像的生成技术,ComfyUI的特别之处在于它采用了一种模块化的设计,把图像生成的过程分解成了许多小的步骤,每个步骤都是一个节点。这些节点可以连接起来形成一个工作流程,这样用户就可以根据需要定制自己的图像生成过程。
ComfyUI工具的具体介绍详情看下面的视频:1 万字系统剖析ComfyUI | Stable Diffusion:GUI全盘点 | ComfyUI系统性教程原理篇04 | Ai+建筑_哔哩哔哩_bilibili
1.2 ComfyUI核心模块
核心模块由模型加载器、提示词管理器、采样器、解码器组成。
(1)模型加载器:Load Checkpoint用于加载基础的模型文件,包含Model、CLIP、VAE三部分。

(2)提示词管理器:CLIP模块将文本类型的输入变为模型可以理解的latent space embedding作为模型的输入。

(3)采样器:用于控制模型生成图像,不同的采样取值会影响最终输出图像的质量和多样性。采样器可以调节生成过程的速度和质量之间的平衡。

这里重点讲讲采样器,主要是介绍Stable Diffusion部分。
Stable Diffusion的基本原理是通过降噪的方式(如完全的噪声图像),将一个原本的噪声信号变为无噪声的信号(如人可以理解的图像)。其中的降噪过程涉及到多次的采样。采样的系数在KSampler中配置:
- seed:控制噪声产生的随机种子
- control_after_generate:控制seed在每次生成后的变化
- steps:降噪的迭代步数,越多则信号越精准,相对的生成时间也越长
- cfg:classifier free guidance决定了prompt对于最终生成图像的影响有多大。更高的值代表更多地展现prompt中的描述。
- denoise: 多少内容会被噪声覆盖 sampler_name、scheduler:降噪参数。
(4)解码器:VAE模块的作用是将Latent space中的embedding解码为像素级别的图像。

1.3 ComfyUI图片生成流程
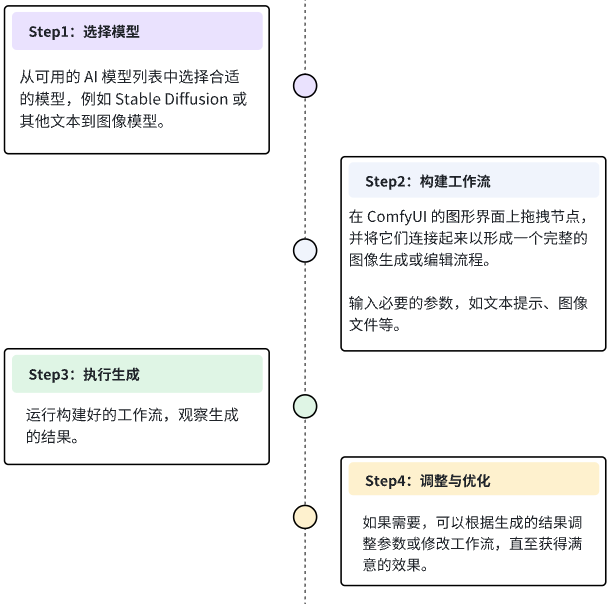
ComfyUI图片生成流程:
- 第一步:选择模型
- 从可用的AI模型列表中选择合适的模型,例如Stable Diffusion或其他文本到图像模型。
- 第二步:构建工作流
- 在ComfyUl的图形界面上拖拽节点,并将它们连接起来以形成一个完整的图像生成或编辑流程。
- 输入必要的参数,如文本提示、图像文件等。
- 第三步:执行生成
- 运行构建好的工作流,观察生成的结果。
- 第四步:调整与优化
- 如果需要,可以根据生成的结果调整参数或修改工作流,直至获得满意的效果。
1.4 ComfyUI的优势
- 模块化和灵活性:ComfyUI 提供了一个模块化的系统,用户可以通过拖放不同的模块来构建复杂的工作流程。这种灵活性允许用户根据自己的需求自由组合和调整模型、输入、输出、和其他处理步骤。
- 可视化界面:ComfyUI 提供了直观的图形界面,使得用户能够更清晰地理解和操作复杂的 AI 模型和数据流。这对没有编程背景的用户特别有帮助,使他们能够轻松构建和管理工作流程。
- 多模型支持:ComfyUI 支持多个不同的生成模型,用户可以在同一平台上集成和切换使用不同的模型,从而实现更广泛的应用场景。
- 调试和优化:通过其可视化界面,ComfyUI 使得调试生成过程变得更简单。用户可以轻松地追踪数据流,识别并解决问题,从而优化生成结果。
- 开放和可扩展:ComfyUI 是一个开源项目,具有高度的可扩展性。开发者可以根据需要编写新的模块或插件,扩展系统功能,并根据项目需求进行定制。
- 用户友好性:尽管其功能强大,但 ComfyUI 仍然保持了用户友好性,即使对于复杂任务,也能以相对简单的方式完成,使其成为生成式 AI 工作流程管理的有力工具。
2. 20分钟速通安装ComfyUI
在这里,我们依旧选择使用魔搭社区提供的Notebook(链接:我的Notebook · 魔搭社区 (modelscope.cn))和免费的GPU算力体验来体验ComfyUI。

2.1 下载脚本代码文件
下载安装ComfyUI的执行文件和task1中微调完成Lora文件。
git lfs install
git clone https://www.modelscope.cn/datasets/maochase/kolors_test_comfyui.git
mv kolors_test_comfyui/* ./
rm -rf kolors_test_comfyui/
mkdir -p /mnt/workspace/models/lightning_logs/version_0/checkpoints/
mv epoch=0-step=500.ckpt /mnt/workspace/models/lightning_logs/version_0/checkpoints/ (1)在file中创建一个terminal(左侧) (2)粘贴代码,下载文件(右侧)


2.2 进入ComfyUI的安装文件
我们双击进入ComfyUI的安装文件:

2.3 一键执行安装程序(大约10min)


2.4 进入预览界面
当执行到最后一个节点的内容输出了一个访问的链接的时候(即 This is the URL to access ComfyUI: 后面的链接 https://pension-democrats-designated-campbell.trycloudflare.com),复制链接到浏览器中访问。
PS:如果链接访问白屏,或者报错,就等一会再访问重试,程序可能没有正常启动完毕。


注意:到这里还不能生成图片哦,要完成接下来的操作才可以。
3. 浅尝ComfyUI工作流
3.1 不带LoRA的工作流样例
Step1:下载工作流脚本
👇请下载工作流脚本(kolors_example.json)👇
需加载到刚刚安装的comfyUI上(json文件可以找我要或者详见Datawhale (linklearner.com))
{
"last_node_id": 15,
"last_link_id": 18,
"nodes": [
{
"id": 11,
"type": "VAELoader",
"pos": [
1323,
240
],
"size": {
"0": 315,
"1": 58
},
"flags": {},
"order": 0,
"mode": 0,
"outputs": [
{
"name": "VAE",
"type": "VAE",
"links": [
12
],
"shape": 3
}
],
"properties": {
"Node name for S&R": "VAELoader"
},
"widgets_values": [
"sdxl.vae.safetensors"
]
},
{
"id": 10,
"type": "VAEDecode",
"pos": [
1368,
369
],
"size": {
"0": 210,
"1": 46
},
"flags": {},
"order": 6,
"mode": 0,
"inputs": [
{
"name": "samples",
"type": "LATENT",
"link": 18
},
{
"name": "vae",
"type": "VAE",
"link": 12,
"slot_index": 1
}
],
"outputs": [
{
"name": "IMAGE",
"type": "IMAGE",
"links": [
13
],
"shape": 3,
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "VAEDecode"
}
},
{
"id": 14,
"type": "KolorsSampler",
"pos": [
1011,
371
],
"size": {
"0": 315,
"1": 222
},
"flags": {},
"order": 5,
"mode": 0,
"inputs": [
{
"name": "kolors_model",
"type": "KOLORSMODEL",
"link": 16
},
{
"name": "kolors_embeds",
"type": "KOLORS_EMBEDS",
"link": 17
}
],
"outputs": [
{
"name": "latent",
"type": "LATENT",
"links": [
18
],
"shape": 3,
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "KolorsSampler"
},
"widgets_values": [
1024,
1024,
1000102404233412,
"fixed",
25,
5,
"EulerDiscreteScheduler"
]
},
{
"id": 6,
"type": "DownloadAndLoadKolorsModel",
"pos": [
201,
368
],
"size": {
"0": 315,
"1": 82
},
"flags": {},
"order": 1,
"mode": 0,
"outputs": [
{
"name": "kolors_model",
"type": "KOLORSMODEL",
"links": [
16
],
"shape": 3,
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "DownloadAndLoadKolorsModel"
},
"widgets_values": [
"Kwai-Kolors/Kolors",
"fp16"
]
},
{
"id": 3,
"type": "PreviewImage",
"pos": [
1366,
468
],
"size": [
535.4001724243165,
562.2001106262207
],
"flags": {},
"order": 7,
"mode": 0,
"inputs": [
{
"name": "images",
"type": "IMAGE",
"link": 13
}
],
"properties": {
"Node name for S&R": "PreviewImage"
}
},
{
"id": 12,
"type": "KolorsTextEncode",
"pos": [
519,
529
],
"size": [
457.2893696934723,
225.28656056301645
],
"flags": {},
"order": 4,
"mode": 0,
"inputs": [
{
"name": "chatglm3_model",
"type": "CHATGLM3MODEL",
"link": 14,
"slot_index": 0
}
],
"outputs": [
{
"name": "kolors_embeds",
"type": "KOLORS_EMBEDS",
"links": [
17
],
"shape": 3,
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "KolorsTextEncode"
},
"widgets_values": [
"cinematic photograph of an astronaut riding a horse in space |\nillustration of a cat wearing a top hat and a scarf |\nphotograph of a goldfish in a bowl |\nanime screencap of a red haired girl",
"",
1
]
},
{
"id": 15,
"type": "Note",
"pos": [
200,
636
],
"size": [
273.5273818969726,
149.55464588512064
],
"flags": {},
"order": 2,
"mode": 0,
"properties": {
"text": ""
},
"widgets_values": [
"Text encoding takes the most VRAM, quantization can reduce that a lot.\n\nApproximate values I have observed:\nfp16 - 12 GB\nquant8 - 8-9 GB\nquant4 - 4-5 GB\n\nquant4 reduces the quality quite a bit, 8 seems fine"
],
"color": "#432",
"bgcolor": "#653"
},
{
"id": 13,
"type": "DownloadAndLoadChatGLM3",
"pos": [
206,
522
],
"size": [
274.5334274291992,
58
],
"flags": {},
"order": 3,
"mode": 0,
"outputs": [
{
"name": "chatglm3_model",
"type": "CHATGLM3MODEL",
"links": [
14
],
"shape": 3
}
],
"properties": {
"Node name for S&R": "DownloadAndLoadChatGLM3"
},
"widgets_values": [
"fp16"
]
}
],
"links": [
[
12,
11,
0,
10,
1,
"VAE"
],
[
13,
10,
0,
3,
0,
"IMAGE"
],
[
14,
13,
0,
12,
0,
"CHATGLM3MODEL"
],
[
16,
6,
0,
14,
0,
"KOLORSMODEL"
],
[
17,
12,
0,
14,
1,
"KOLORS_EMBEDS"
],
[
18,
14,
0,
10,
0,
"LATENT"
]
],
"groups": [],
"config": {},
"extra": {
"ds": {
"scale": 1.1,
"offset": {
"0": -114.73954010009766,
"1": -139.79705810546875
}
}
},
"version": 0.4
}Step2:加载模型,并完成第一次生图
PS:首次点击生成图片会加载资源,时间较长,大家耐心等待。
(1)加载工作流(左侧) (2)执行生成图片(右侧)


3.2 带LoRA的工作流样例
工作流脚本(带LoRA训练)(kolors with lora_example.json)
(json文件可以找我要或者详见Datawhale (linklearner.com))
{
"last_node_id": 16,
"last_link_id": 20,
"nodes": [
{
"id": 11,
"type": "VAELoader",
"pos": [
1323,
240
],
"size": {
"0": 315,
"1": 58
},
"flags": {},
"order": 0,
"mode": 0,
"outputs": [
{
"name": "VAE",
"type": "VAE",
"links": [
12
],
"shape": 3
}
],
"properties": {
"Node name for S&R": "VAELoader"
},
"widgets_values": [
"sdxl.vae.safetensors"
]
},
{
"id": 10,
"type": "VAEDecode",
"pos": [
1368,
369
],
"size": {
"0": 210,
"1": 46
},
"flags": {},
"order": 7,
"mode": 0,
"inputs": [
{
"name": "samples",
"type": "LATENT",
"link": 18
},
{
"name": "vae",
"type": "VAE",
"link": 12,
"slot_index": 1
}
],
"outputs": [
{
"name": "IMAGE",
"type": "IMAGE",
"links": [
13
],
"shape": 3,
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "VAEDecode"
}
},
{
"id": 15,
"type": "Note",
"pos": [
200,
636
],
"size": {
"0": 273.5273742675781,
"1": 149.5546417236328
},
"flags": {},
"order": 1,
"mode": 0,
"properties": {
"text": ""
},
"widgets_values": [
"Text encoding takes the most VRAM, quantization can reduce that a lot.\n\nApproximate values I have observed:\nfp16 - 12 GB\nquant8 - 8-9 GB\nquant4 - 4-5 GB\n\nquant4 reduces the quality quite a bit, 8 seems fine"
],
"color": "#432",
"bgcolor": "#653"
},
{
"id": 13,
"type": "DownloadAndLoadChatGLM3",
"pos": [
206,
522
],
"size": {
"0": 274.5334167480469,
"1": 58
},
"flags": {},
"order": 2,
"mode": 0,
"outputs": [
{
"name": "chatglm3_model",
"type": "CHATGLM3MODEL",
"links": [
14
],
"shape": 3
}
],
"properties": {
"Node name for S&R": "DownloadAndLoadChatGLM3"
},
"widgets_values": [
"fp16"
]
},
{
"id": 6,
"type": "DownloadAndLoadKolorsModel",
"pos": [
201,
368
],
"size": {
"0": 315,
"1": 82
},
"flags": {},
"order": 3,
"mode": 0,
"outputs": [
{
"name": "kolors_model",
"type": "KOLORSMODEL",
"links": [
19
],
"shape": 3,
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "DownloadAndLoadKolorsModel"
},
"widgets_values": [
"Kwai-Kolors/Kolors",
"fp16"
]
},
{
"id": 12,
"type": "KolorsTextEncode",
"pos": [
519,
529
],
"size": {
"0": 457.28936767578125,
"1": 225.28656005859375
},
"flags": {},
"order": 4,
"mode": 0,
"inputs": [
{
"name": "chatglm3_model",
"type": "CHATGLM3MODEL",
"link": 14,
"slot_index": 0
}
],
"outputs": [
{
"name": "kolors_embeds",
"type": "KOLORS_EMBEDS",
"links": [
17
],
"shape": 3,
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "KolorsTextEncode"
},
"widgets_values": [
"二次元,长发,少女,白色背景",
"",
1
]
},
{
"id": 3,
"type": "PreviewImage",
"pos": [
1366,
469
],
"size": {
"0": 535.400146484375,
"1": 562.2001342773438
},
"flags": {},
"order": 8,
"mode": 0,
"inputs": [
{
"name": "images",
"type": "IMAGE",
"link": 13
}
],
"properties": {
"Node name for S&R": "PreviewImage"
}
},
{
"id": 16,
"type": "LoadKolorsLoRA",
"pos": [
606,
368
],
"size": {
"0": 317.4000244140625,
"1": 82
},
"flags": {},
"order": 5,
"mode": 0,
"inputs": [
{
"name": "kolors_model",
"type": "KOLORSMODEL",
"link": 19
}
],
"outputs": [
{
"name": "kolors_model",
"type": "KOLORSMODEL",
"links": [
20
],
"shape": 3,
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "LoadKolorsLoRA"
},
"widgets_values": [
"/mnt/workspace/models/lightning_logs/version_0/checkpoints/epoch=0-step=500.ckpt",
2
]
},
{
"id": 14,
"type": "KolorsSampler",
"pos": [
1011,
371
],
"size": {
"0": 315,
"1": 266
},
"flags": {},
"order": 6,
"mode": 0,
"inputs": [
{
"name": "kolors_model",
"type": "KOLORSMODEL",
"link": 20
},
{
"name": "kolors_embeds",
"type": "KOLORS_EMBEDS",
"link": 17
},
{
"name": "latent",
"type": "LATENT",
"link": null
}
],
"outputs": [
{
"name": "latent",
"type": "LATENT",
"links": [
18
],
"shape": 3,
"slot_index": 0
}
],
"properties": {
"Node name for S&R": "KolorsSampler"
},
"widgets_values": [
1024,
1024,
0,
"fixed",
25,
5,
"EulerDiscreteScheduler",
1
]
}
],
"links": [
[
12,
11,
0,
10,
1,
"VAE"
],
[
13,
10,
0,
3,
0,
"IMAGE"
],
[
14,
13,
0,
12,
0,
"CHATGLM3MODEL"
],
[
17,
12,
0,
14,
1,
"KOLORS_EMBEDS"
],
[
18,
14,
0,
10,
0,
"LATENT"
],
[
19,
6,
0,
16,
0,
"KOLORSMODEL"
],
[
20,
16,
0,
14,
0,
"KOLORSMODEL"
]
],
"groups": [],
"config": {},
"extra": {
"ds": {
"scale": 1.2100000000000002,
"offset": {
"0": -183.91309381910426,
"1": -202.11110769225016
}
}
},
"version": 0.4
}执行操作:
- 这里的Lora是我们Task1微调训练出来的文件
- 地址是:/mnt/workspace/models/lightning_logs/version_0/checkpoints/epoch=0-step=500.ckpt
- 大家如有有其他的Lora文件,可以在下面截图Lora文件地址区域更换成自己的地址
(1)加载工作流(左侧) (2)执行生成图片(右侧)


4. 自我学习,快速提升
4.1 资源网站
| 名称 | 链接地址 |
| 在魔搭使用ComfyUI,玩转AIGC! | https://modelscope.cn/headlines/article/429 |
| ComfyUI的官方地址 | https://github.com/comfyanonymous/ComfyUI |
| ComfyUI官方示范 | https://comfyanonymous.github.io/ComfyUI_examples/ |
| 别人的基础工作流示范 | https://github.com/cubiq/ComfyUI_Workflows |
| https://github.com/wyrde/wyrde-comfyui-workflows | |
| 工作流分享网站 | https://comfyworkflows.com/ |
| 推荐一个比较好的comfyui的github仓库网站 | https://github.com/ZHO-ZHO-ZHO/ComfyUI-Workflows-ZHO?tab=readme-ov-file |
4.2 魔搭官方教程
2.2ComfyUI应用场景探索_哔哩哔哩_bilibili
二、Lora微调
1. Lora简介
LoRA (Low-Rank Adaptation) 微调是一种用于在预训练模型上进行高效微调的技术。它可以通过高效且灵活的方式实现模型的个性化调整,使其能够适应特定的任务或领域,同时保持良好的泛化能力和较低的资源消耗。这对于推动大规模预训练模型的实际应用至关重要。
1.1 Lora微调的原理
LoRA通过在预训练模型的关键层中添加低秩矩阵来实现。这些低秩矩阵通常被设计成具有较低维度的参数空间,这样它们就可以在不改变模型整体结构的情况下进行微调。在训练过程中,只有这些新增的低秩矩阵被更新,而原始模型的大部分权重保持不变。
一个 LORA 模型,它由三部分组成:
lora_down.weight(下层权重)lora_up.weight(上层权重)alpha(缩放系数)
具体可以参考下面视频,对 Lora 的原理讲的比较通俗易懂:通俗易懂理解全量微调和LoRA微调_哔哩哔哩_bilibili。
1.2 Lora微调的优势
(1)快速适应新任务
在特定领域有少量标注数据的情况下,也可以有效地对模型进行个性化调整,可以迅速适应新的领域或特定任务。
(2)保持泛化能力
LoRA通过微调模型的一部分,有助于保持模型在未见过的数据上的泛化能力,同时还能学习到特定任务的知识。
(3)资源效率
LoRA旨在通过仅微调模型的部分权重,而不是整个模型,从而减少所需的计算资源和存储空间。
2. Lora详解
现在我们来针对可图比赛中的微调代码进行一个深入的了解。
2.1 Task2中的微调代码
import os
cmd = """
python DiffSynth-Studio/examples/train/kolors/train_kolors_lora.py \ # 选择使用可图的Lora训练脚本DiffSynth-Studio/examples/train/kolors/train_kolors_lora.py
--pretrained_unet_path models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors \ # 选择unet模型
--pretrained_text_encoder_path models/kolors/Kolors/text_encoder \ # 选择text_encoder
--pretrained_fp16_vae_path models/sdxl-vae-fp16-fix/diffusion_pytorch_model.safetensors \ # 选择vae模型
--lora_rank 16 \ # lora_rank 16 表示在权衡模型表达能力和训练效率时,选择了使用 16 作为秩,适合在不显著降低模型性能的前提下,通过 LoRA 减少计算和内存的需求
--lora_alpha 4.0 \ # 设置 LoRA 的 alpha 值,影响调整的强度
--dataset_path data/lora_dataset_processed \ # 指定数据集路径,用于训练模型
--output_path ./models \ # 指定输出路径,用于保存模型
--max_epochs 1 \ # 设置最大训练轮数为 1
--center_crop \ # 启用中心裁剪,这通常用于图像预处理
--use_gradient_checkpointing \ # 启用梯度检查点技术,以节省内存
--precision "16-mixed" # 指定训练时的精度为混合 16 位精度(half precision),这可以加速训练并减少显存使用
""".strip()
os.system(cmd) # 执行可图Lora训练 2.2 参数详情表
| 参数名称 | 参数值 | 说明 |
|
| models/kolors/Kolors/unet/diffusion_pytorch_model.safetensors | 指定预训练UNet模型的路径 |
|
| models/kolors/Kolors/text_encoder | 指定预训练文本编码器的路径 |
|
| models/sdxl-vae-fp16-fix/diffusion_pytorch_model.safetensors | 指定预训练VAE模型的路径 |
|
| 16 | 设置LoRA的秩(rank),影响模型的复杂度和性能 |
|
| 4 | 设置LoRA的alpha值,控制微调的强度 |
|
| data/lora_dataset_processed | 指定用于训练的数据集路径 |
|
| ./models | 指定训练完成后保存模型的路径 |
|
| 1 | 设置最大训练轮数为1 |
|
| 启用中心裁剪,用于图像预处理 | |
|
| 启用梯度检查点,节省显存 | |
|
| "16-mixed" | 设置训练时的精度为混合16位精度(half precision) |
2.3 UNet、VAE和文本编码器的协作关系
- UNet:负责根据输入的噪声和文本条件生成图像。在Stable Diffusion模型中,UNet接收由VAE编码器产生的噪声和文本编码器转换的文本向量作为输入,并预测去噪后的噪声,从而生成与文本描述相符的图像
- VAE:生成模型,用于将输入数据映射到潜在空间,并从中采样以生成新图像。在Stable Diffusion中,VAE编码器首先生成带有噪声的潜在表示,这些表示随后与文本条件一起输入到UNet中
- 文本编码器:将文本输入转换为模型可以理解的向量表示。在Stable Diffusion模型中,文本编码器使用CLIP模型将文本提示转换为向量,这些向量与VAE生成的噪声一起输入到UNet中,指导图像的生成过程
3. 上传LoRA模型
LoRA 上传地址:模型创建 · 魔搭社区 (modelscope.cn)。
(1)移动结果文件
新建 Terminal(File→New→Terminal),粘贴如下命令,回车执行。
mkdir /mnt/workspace/output & cd
cp /mnt/workspace/models/lightning_logs/version_0/checkpoints/epoch=0-step=500.ckpt /mnt/workspace/output/
cp /mnt/workspace/1.png /mnt/workspace/output/(2)下载结果文件
双击进入output文件夹,分别下载两个文件到本地。


(3)创建并上传模型
点击链接:模型创建 · 魔搭社区 (modelscope.cn),创建模型,英文名称建议格式:xxx-LoRA;中文名称建议格式:队伍名称-可图Kolors训练-xxx。
我这里英文和中文的命名分别是 lora1_LoRA 和 Test03-可图Kolors训练-lora1 。


我的LoRA模型链接:Test03-可图Kolors训练-lora1 · 模型库 (modelscope.cn) 。
三、如何准备一个高质量的数据集
当我们进行图片生成相关的工作时,选择合适的数据集是非常重要的。如何找到适合自己的数据集呢,这里给大家整理了一些重要的参考维度,希望可以帮助你快速找到适合的数据集:
1. 明确你的需求和目标
- 关注应用场景:确定你的模型将被应用到什么样的场景中(例如,艺术风格转换、产品图像生成、医疗影像合成等)。
- 关注数据类型:你需要什么样的图片?比如是真实世界的照片还是合成图像?是黑白的还是彩色的?是高分辨率还是低分辨率?
- 关注数据量:考虑你的任务应该需要多少图片来支持训练和验证。
2. 数据集来源整理
以下渠道来源均需要考虑合规性问题,请大家在使用数据集过程中谨慎选择。
| 来源类型 | 推荐 |
| 公开的数据平台 | 魔搭社区内开放了近3000个数据集,涉及文本、图像、音频、视频和多模态等多种场景,左侧有标签栏帮助快速导览,大家可以看看有没有自己需要的数据集。
其他数据平台推荐:
|
| 使用API或爬虫获取 |
|
| 数据合成 | 利用现有的图形引擎(如Unity、Unreal Engine)或特定软件生成合成数据,这在训练某些类型的模型时非常有用。 最近Datawhale联合阿里云天池,做了一整套多模态大模型数据合成的学习,欢迎大家一起交流。从零入门多模态大模型数据合成 |
| 数据增强 | 对于较小的数据集,可以通过旋转、翻转、缩放、颜色变换等方式进行数据增强。 |
| 购买或定制 | 如果你的应用是特定领域的,比如医学影像、卫星图像等,建议从靠谱的渠道购买一些数据集。 |

四、ComfyUI样例完整代码
1. 下载并安装 ComfyUI
# #@title Environment Setup
from pathlib import Path
OPTIONS = {}
UPDATE_COMFY_UI = True #@param {type:"boolean"}
INSTALL_COMFYUI_MANAGER = True #@param {type:"boolean"}
INSTALL_KOLORS = True #@param {type:"boolean"}
INSTALL_CUSTOM_NODES_DEPENDENCIES = True #@param {type:"boolean"}
OPTIONS['UPDATE_COMFY_UI'] = UPDATE_COMFY_UI
OPTIONS['INSTALL_COMFYUI_MANAGER'] = INSTALL_COMFYUI_MANAGER
OPTIONS['INSTALL_KOLORS'] = INSTALL_KOLORS
OPTIONS['INSTALL_CUSTOM_NODES_DEPENDENCIES'] = INSTALL_CUSTOM_NODES_DEPENDENCIES
current_dir = !pwd
WORKSPACE = f"{current_dir[0]}/ComfyUI"
%cd /mnt/workspace/
![ ! -d $WORKSPACE ] && echo -= Initial setup ComfyUI =- && git clone https://github.com/comfyanonymous/ComfyUI
%cd $WORKSPACE
if OPTIONS['UPDATE_COMFY_UI']:
!echo "-= Updating ComfyUI =-"
!git pull
if OPTIONS['INSTALL_COMFYUI_MANAGER']:
%cd custom_nodes
![ ! -d ComfyUI-Manager ] && echo -= Initial setup ComfyUI-Manager =- && git clone https://github.com/ltdrdata/ComfyUI-Manager
%cd ComfyUI-Manager
!git pull
if OPTIONS['INSTALL_KOLORS']:
%cd ../
![ ! -d ComfyUI-KwaiKolorsWrapper ] && echo -= Initial setup KOLORS =- && git clone https://github.com/kijai/ComfyUI-KwaiKolorsWrapper.git
%cd ComfyUI-KwaiKolorsWrapper
!git pull
%cd $WORKSPACE
if OPTIONS['INSTALL_CUSTOM_NODES_DEPENDENCIES']:
!pwd
!echo "-= Install custom nodes dependencies =-"
![ -f "custom_nodes/ComfyUI-Manager/scripts/colab-dependencies.py" ] && python "custom_nodes/ComfyUI-Manager/scripts/colab-dependencies.py"
!wget "https://modelscope.oss-cn-beijing.aliyuncs.com/resource/cloudflared-linux-amd64.deb"
!dpkg -i cloudflared-linux-amd64.deb2. 下载模型
#@markdown ###Download standard resources
OPTIONS = {}
#@markdown **unet**
!wget -c "https://modelscope.cn/models/Kwai-Kolors/Kolors/resolve/master/unet/diffusion_pytorch_model.fp16.safetensors" -P ./models/diffusers/Kolors/unet/
!wget -c "https://modelscope.cn/models/Kwai-Kolors/Kolors/resolve/master/unet/config.json" -P ./models/diffusers/Kolors/unet/
#@markdown **encoder**
!modelscope download --model=ZhipuAI/chatglm3-6b-base --local_dir ./models/diffusers/Kolors/text_encoder/
#@markdown **vae**
!wget -c "https://modelscope.cn/models/AI-ModelScope/sdxl-vae-fp16-fix/resolve/master/sdxl.vae.safetensors" -P ./models/vae/ #sdxl-vae-fp16-fix.safetensors
#@markdown **scheduler**
!wget -c "https://modelscope.cn/models/Kwai-Kolors/Kolors/resolve/master/scheduler/scheduler_config.json" -P ./models/diffusers/Kolors/scheduler/
#@markdown **modelindex**
!wget -c "https://modelscope.cn/models/Kwai-Kolors/Kolors/resolve/master/model_index.json" -P ./models/diffusers/Kolors/
3. 安装 LoRA 节点
lora_node = """
import torch
from peft import LoraConfig, inject_adapter_in_model
class LoadKolorsLoRA:
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"kolors_model": ("KOLORSMODEL", ),
"lora_path": ("STRING", {"multiline": False, "default": "",}),
"lora_alpha": ("FLOAT", {"default": 2.0, "min": 0.0, "max": 4.0, "step": 0.01}),
},
}
RETURN_TYPES = ("KOLORSMODEL",)
RETURN_NAMES = ("kolors_model",)
FUNCTION = "add_lora"
CATEGORY = "KwaiKolorsWrapper"
def convert_state_dict(self, state_dict):
prefix_rename_dict = {
"blocks.7.transformer_blocks": "down_blocks.1.attentions.0.transformer_blocks",
"blocks.10.transformer_blocks": "down_blocks.1.attentions.1.transformer_blocks",
"blocks.15.transformer_blocks": "down_blocks.2.attentions.0.transformer_blocks",
"blocks.18.transformer_blocks": "down_blocks.2.attentions.1.transformer_blocks",
"blocks.21.transformer_blocks": "mid_block.attentions.0.transformer_blocks",
"blocks.25.transformer_blocks": "up_blocks.0.attentions.0.transformer_blocks",
"blocks.28.transformer_blocks": "up_blocks.0.attentions.1.transformer_blocks",
"blocks.31.transformer_blocks": "up_blocks.0.attentions.2.transformer_blocks",
"blocks.35.transformer_blocks": "up_blocks.1.attentions.0.transformer_blocks",
"blocks.38.transformer_blocks": "up_blocks.1.attentions.1.transformer_blocks",
"blocks.41.transformer_blocks": "up_blocks.1.attentions.2.transformer_blocks",
}
suffix_rename_dict = {
".to_out.lora_A.default.weight": ".to_out.0.lora_A.default.weight",
".to_out.lora_B.default.weight": ".to_out.0.lora_B.default.weight",
}
state_dict_ = {}
for name, param in state_dict.items():
for prefix in prefix_rename_dict:
if name.startswith(prefix):
name = name.replace(prefix, prefix_rename_dict[prefix])
for suffix in suffix_rename_dict:
if name.endswith(suffix):
name = name.replace(suffix, suffix_rename_dict[suffix])
state_dict_[name] = param
lora_rank = state_dict_["up_blocks.1.attentions.2.transformer_blocks.1.attn2.to_q.lora_A.default.weight"].shape[0]
return state_dict_, lora_rank
def load_lora(self, model, lora_rank, lora_alpha, state_dict):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=lora_alpha,
init_lora_weights="gaussian",
target_modules=["to_q", "to_k", "to_v", "to_out.0"],
)
model = inject_adapter_in_model(lora_config, model)
model.load_state_dict(state_dict, strict=False)
return model
def add_lora(self, kolors_model, lora_path, lora_alpha):
state_dict = torch.load(lora_path, map_location="cpu")
state_dict, lora_rank = self.convert_state_dict(state_dict)
kolors_model["pipeline"].unet = self.load_lora(kolors_model["pipeline"].unet, lora_rank, lora_alpha, state_dict)
return (kolors_model,)
NODE_CLASS_MAPPINGS = {
"LoadKolorsLoRA": LoadKolorsLoRA,
}
NODE_DISPLAY_NAME_MAPPINGS = {
"LoadKolorsLoRA": "Load Kolors LoRA",
}
__all__ = ["NODE_CLASS_MAPPINGS", "NODE_DISPLAY_NAME_MAPPINGS"]
""".strip()
import os
os.makedirs("/mnt/workspace/ComfyUI/custom_nodes/ComfyUI-LoRA", exist_ok=True)
with open("/mnt/workspace/ComfyUI/custom_nodes/ComfyUI-LoRA/__init__.py", "w", encoding="utf-8") as f:
f.write(lora_node)4. 启动 ComfyUI
- 启动后,通过代码输出的链接查看 UI 页面
- 点击右侧“Load”,加载“kolors_example.json”(不带 LoRA)或者 “kolors_with_lora_example.json”(带 LoRA)
- 加载 LoRA 时,请在“lora_path”处填入 LoRA 模型的路径,例如
/mnt/workspace/models/lightning_logs/version_0/checkpoints/epoch=0-step=500.ckpt
%cd /mnt/workspace/ComfyUI
import subprocess
import threading
import time
import socket
import urllib.request
def iframe_thread(port):
while True:
time.sleep(0.5)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
result = sock.connect_ex(('127.0.0.1', port))
if result == 0:
break
sock.close()
print("\nComfyUI finished loading, trying to launch cloudflared (if it gets stuck here cloudflared is having issues)\n")
p = subprocess.Popen(["cloudflared", "tunnel", "--url", "http://127.0.0.1:{}".format(port)], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
for line in p.stderr:
l = line.decode()
if "trycloudflare.com " in l:
print("This is the URL to access ComfyUI:", l[l.find("http"):], end='')
#print(l, end='')
threading.Thread(target=iframe_thread, daemon=True, args=(8188,)).start()
!python main.py --dont-print-server五、总结与感悟
1. 数据集有多重要?
数据集对实验至关重要。尽管Alpaca数据集受欢迎,且包含50k的数据,但是只有1k数据的LIMA数据集表现出了更好的性能。
2. 如何选择最佳的LoRA的参数r?
选择LoRA的参数r是个需要实验的超参数,太大可能导致过拟合,太小可能不足以处理数据集中的任务多样性。
3. 如何避免过拟合?
减小r或增加数据集大小可以帮助减少过拟合。还可以尝试增加优化器的权重衰减率或LoRA层的dropout值。
4. LoRA权重是否可以合并?
可以将多套LoRA权重合并。训练中保持LoRA权重独立,并在前向传播时添加,训练后可以合并权重以简化操作。
5. 是否可以逐层调整LoRA的最优rank?
理论上,可以为不同层选择不同的LoRA rank(即“k”),类似于为不同层设定不同学习率,但由于增加了调优复杂性,实际中很少执行。