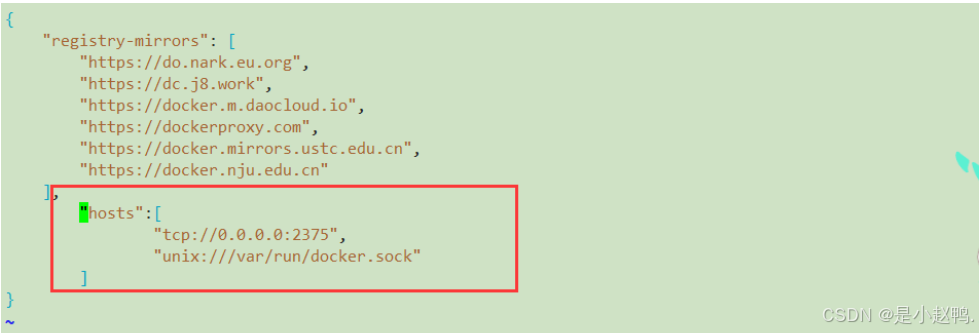
看图!
看图!

预训练与微调是现代深度学习模型,特别是自然语言处理模型,常用的两个阶段。
预训练:
在这个阶段,模型在大量的广泛文本数据上进行训练,学习语言的基本结构、语法、词汇和上下文关系。这个过程通常是无监督的,模型通过预测下一个单词或填补句子中的空白来进行训练。
预训练的目标是让模型掌握一般的语言知识,使其具备较强的语言理解能力。
微调:
微调是在特定的任务或数据集上对预训练模型进行进一步的训练。这个过程通常是有监督的,利用标注好的数据来调整模型的参数,以便更好地适应特定任务(如情感分析、问答系统等)。
微调可以显著提高模型在特定任务上的表现,因为模型已经具备了良好的基础知识。
通过这两个阶段,模型能够在保持通用性的同时,针对特定应用场景进行优化。
大语言模型(LLM,Large Language Model)是一种基于深度学习的人工智能技术,旨在理解和生成自然语言。这些模型通过分析大量文本数据进行训练,从而学习语言的结构、语法和语义。以下是LLM的一些关键特征:
规模大:LLM通常包含数十亿到数千亿个参数,使其能够捕捉复杂的语言模式。
预训练与微调:模型首先在广泛的文本数据上进行预训练,然后可以通过微调来适应特定的任务或领域。
多功能性:LLM可以用于多种任务,包括文本生成、翻译、问答、摘要等。
上下文理解:这些模型能够理解上下文,从而生成更加连贯和相关的回复。
应用广泛:LLM被广泛应用于聊天机器人、内容创作、教育、客服等领域。
总的来说,LLM是一种强大的工具,能够帮助人们更高效地处理和生成语言信息。