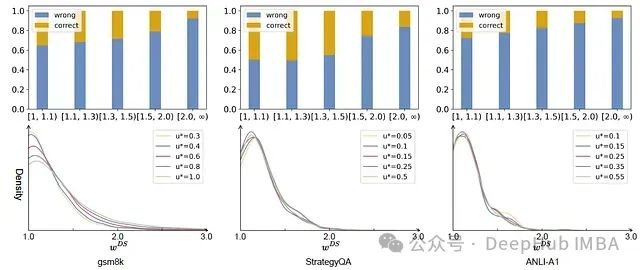
Transformer的Softmax函数
Transformer的Softmax函数: 用于将原始注意力分数转换为输入标记的概率分布。这种分布将较高的注意力权重分配给更相关的标记,并将较低的权重分配给不太相关的标记。Transformers通过Softmax在生成输出时,使用注意力机制来权衡不同输入标记的重要性。

Transformer的Softmax函数
Softmax的数学原理: 对于一个给定的实数向量,它首先计算每一个元素的指数(e的幂),然后每个元素的指数与所有元素指数总和的比值,就形成了softmax函数的输出。这种计算方式不仅使输出值落在0到1之间,还保证了所有输出值的总和为1。
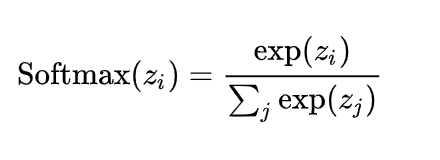
Softmax的数学原理
Softmax在Transformer的位置:
在Transformer模型中,Softmax函数主要在两个关键位置被使用:
- 自注意力机制(Self-Attention Mechanism):
(1)自注意力机制是Transformer模型中的核心组件之一,它允许模型处理输入序列中的依赖关系,而不需要考虑序列中元素的顺序。
(2)在自注意力机制中,模型首先计算输入序列中每个位置(token)与其他所有位置的的相似度分数(也称为注意力分数)。这些分数通常通过点积、缩放点积或其他相似度函数计算得到。
(3)使用Softmax函数对这些相似度分数进行归一化,生成一个权重分布,该分布表示了在计算当前位置(query)的表示时,应赋予其他位置(keys)多大的关注程度。
(4)这些权重最终被用来计算加权和,生成当前位置的上下文向量,该向量将作为该位置在后续层中的输入。
- 输出层(Output Layer):
(1)在Transformer的解码器部分,输出层负责根据解码器的状态生成目标序列。
(2)当进行词汇预测或生成任务时(如机器翻译中的下一个词预测),解码器的最后一层通常会产生一个未经归一化的分数向量(logits),其中每个元素对应于词汇表中一个词的概率。
(3)Softmax函数被应用于这个分数向量,将其转换为概率分布,其中每个元素表示生成对应词汇的概率。这使得模型可以生成一个分布,并从中选择最可能的词作为预测结果。
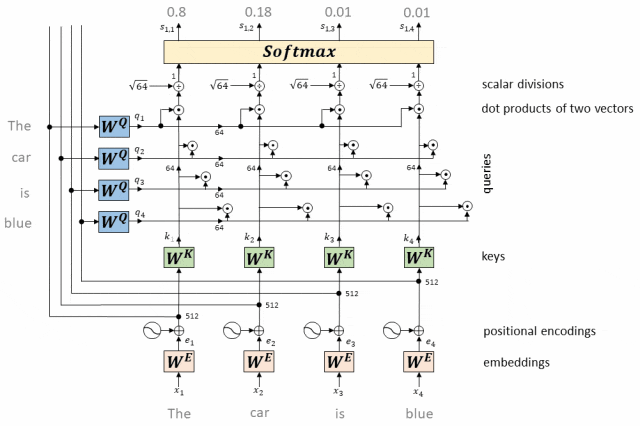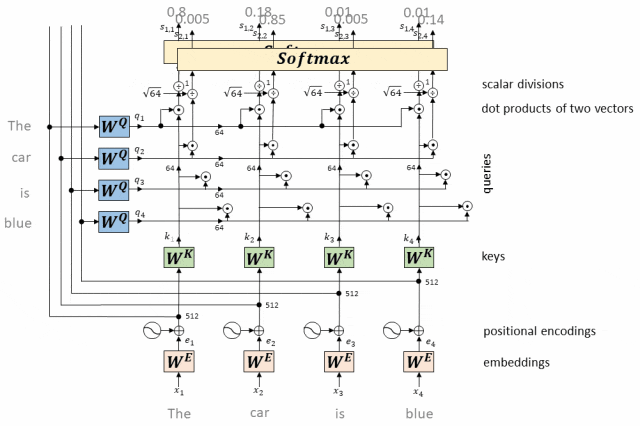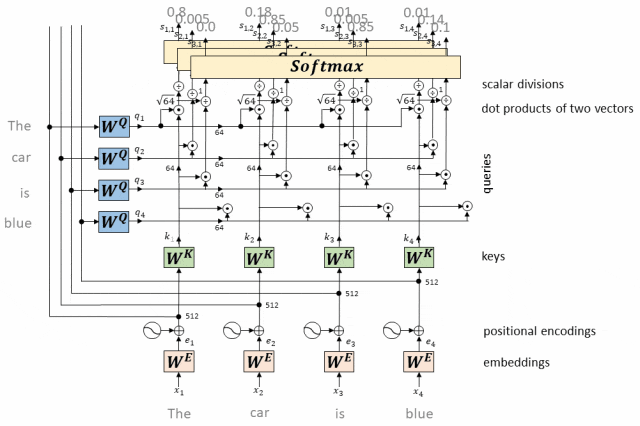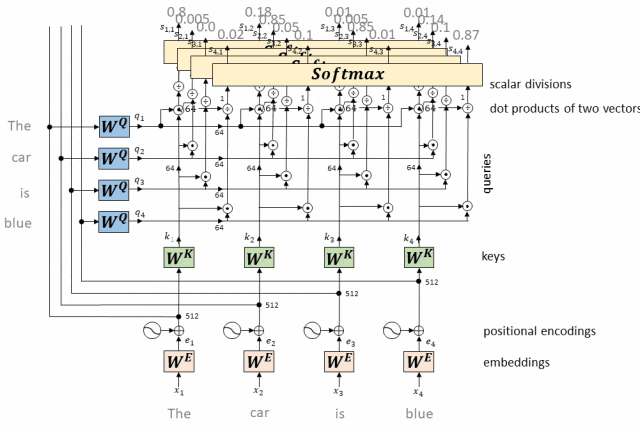
Softmax在Transformer的位置
Softmax在Transformer的作用:
-
归一化: Softmax函数将原始分数转换为概率分布,确保所有概率之和为1,使得输出结果可以解释为概率。
-
平滑化: 通过指数函数,Softmax能够将大的分数差距转换为相对平滑的概率分布,从而避免了“赢家通吃”的情况,即一个分数远大于其他分数时,其他分数几乎被忽略。
-
可解释性: 输出的概率分布使得模型预测结果更加直观和可解释,我们可以直接查看模型为每个可能输出分配的概率。
-
稳定性: 在训练过程中,Softmax有助于保持梯度的稳定性,因为概率分布的变化通常比原始分数更加平滑。

Softmax在Transformer的作用
注释
Transformer动画素材来源于3Blue1Brown,想了解更多查看参考资料网址。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈






![[创业之路-141] :产品经理 - NPDP概述](https://img-blog.csdnimg.cn/img_convert/417b8b507676305ad57eed857c4dc536.png)