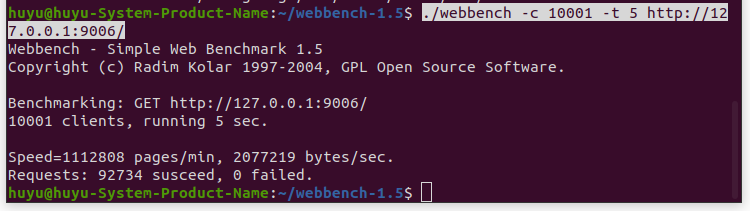
人工智能咨询培训老师叶梓 转载标明出处
临床计算器在医疗保健中扮演着至关重要的角色,它们通过提供准确的基于证据的预测来辅助临床医生进行诊断和预后评估。然而,由于可用性挑战、传播不畅和功能受限,这些工具的广泛应用常常受限。为了克服这些障碍并提高工作效率,来自美国国立卫生研究院(NIH)、马里兰大学、耶鲁大学和佛罗里达州立大学的研究团队提出了AgentMD,这是一种新型语言代理,能够跨不同临床情境整理和应用临床计算器。
AgentMD利用已发布的文献,自动整理了2,164种不同的临床计算器,这些计算器具有可执行的功能和结构化文档,统称为RiskCalcs。手动评估显示,RiskCalcs工具在三个质量指标上达到了超过80%的准确率。在推理时,AgentMD能够自动选择并应用与任何患者描述相关的RiskCalcs工具。在新建立的RiskQA基准测试中,AgentMD显著优于GPT-4的链式思维提示(87.7%对比40.9%的准确率)。此外,AgentMD也被应用于分析真实世界的临床记录,以洞察患者特征。
AgentMD的架构涵盖了两个角色:作为工具制造者,它自动筛选PubMed文章以识别相关的风险计算器,然后创建和验证这些工具,最终形成一个结构化风险计算器工具库(RiskCalcs)。作为工具使用者,AgentMD采用一种与LLM无关的框架,能够根据患者记录选择、计算和总结合适的风险计算器的输出结果。
AgentMD通过三个步骤自动化地从PubMed摘要中整理风险计算器工具:筛选(Screening)、起草(Drafting)和验证(Verification)。首先,AgentMD使用布尔查询在PubMed数据库中搜索相关文章,查询语句为“patient AND (risk OR mortality) AND (score OR point OR rule OR calculator)”,时间范围从2000年1月到2023年4月,共筛选出339,952篇文章。然后,使用GPT-3.5进一步筛选可能描述新风险评分或计算器的文章,最终得到33,033篇潜在文章。接下来,GPT-4根据这些文章撰写结构化的医学计算器,包括标题、目的、适用性、主题、计算逻辑(用Python编写的函数)、结果解释和效用等关键部分。例如,图2a展示了基于PMID: 1272815522摘要生成的RiskCalcs计算器的一个实例。由于起草的计算器可能包含错误,AgentMD进一步使用GPT-4进行验证,确保计算器的准确性。

图1d展示了AgentMD如何从2,164个候选计算器中为给定的患者记录计算风险,包括三个主要步骤:选择、计算和总结。在工具选择步骤中,AgentMD首先使用MedCPT检索与患者记录最相关的前10个计算器,然后使用LLMs选择合适的工具。对于每个选定的工具,AgentMD通过生成调用RiskCalcs中相关和可重用工具函数的Python代码来计算患者的风险。AgentMD与Python解释器交互,解释器返回打印结果或在执行AgentMD编写的代码时的错误消息。根据代码解释器返回的消息,AgentMD会重试其他代码操作或将整个交互历史总结成一段风险计算结果。


图3展示了RiskCalcs中计算器的评估结果。研究者手动评估了两个代表性的RiskCalcs子集:被引用次数最多的前50个计算器(图2a)和随机抽取的其他50个计算器(图2b)。对于每个计算器,三名注释者被雇佣来评估工具的质量、覆盖范围和问题回答(QA)的正确性。三名注释者的共识被用作真实标签。计算器的PubMed ID可以在补充材料中找到。质量评估包括三个方面:原始摘要、计算逻辑和结果解释。总体而言,RiskCalcs工具在三个方面的准确性都很高:原始摘要、计算逻辑和结果解释的平均正确性分别为87.0%、87.6%和89.0%。
在RiskQA上评估AgentMD,这是本工作中引入的一个新数据集,遵循多选医学问题回答的格式,通常用于评估生物医学LLM。构建RiskQA数据集时,研究者重新使用了350个手动验证的RiskCalcs计算器的正确计算逻辑和结果解释的参数集。对于每个参数集和验证的计算,研究者进一步使用GPT-4将它们扩展成临床情景、可能的选择和正确答案,风格类似于美国医学执照考试(USMLE)问题。与之前计算逻辑评估不同,RiskQA要求系统选择合适的风险计算器,进行正确的计算,并提供适当的解释。

实验结果如图4所示。在这项任务中,AgentMD首先从RiskCalcs集合中选择一个工具,然后使用它来计算给定患者的风险并预测答案选择,如图4a所示。研究者首先将AgentMD与链式思维(Chain-of-Thought,CoT)进行了比较,这是一种广泛使用的LLM提示策略。AgentMD在准确率上超过了CoT 70.1%(0.546对0.321,图2b)和114.4%(0.877对0.409,图2c),分别以GPT-3.5和GPT-4作为基础模型。令人惊讶的是,即使使用GPT-3.5,AgentMD的性能也超过了使用GPT-4的CoT(0.546对0.409)。这些结果清楚地表明,当提供经过良好整理的临床计算器工具箱时,大型语言模型可以准确地选择适当的计算器,并有效地执行医学计算任务。
研究者将AgentMD应用于MIMIC-III数据库中的9,822份ICU患者的入院记录。AgentMD首先为每位患者生成潜在风险及其定量可能性的列表,然后按每位患者应用的1,039个风险计算器聚合AgentMD结果。对于每个计算器,AgentMD根据与特异性、严重性、紧急性和笔记中缺失情况相关的一组度量标准对符合条件的患者进行排名。图5c显示了每位患者应用的计算器数量的分布,其大致遵循正态分布,平均值为4.6。另一方面,每个工具符合条件的患者数量遵循长尾分布,如图5d所示。

图5e展示了AgentMD最常应用的两个计算器的患者结果分布。第一个计算器预测慢性心力衰竭急性加重的短期死亡率。尽管平均特异性较低,表明大多数所需参数缺失于患者记录中,但其紧急性和严重性分布具有较高的平均值。计算器的缺失分布有两个峰值——较高的接近100,较低的接近0——这表明短期死亡率在大多数符合条件的患者记录中未被评估。第二个计算器预测老年人的4年死亡率。与短期死亡率不同,大多数4年死亡率预测的患者结果并不紧急,严重性也以不同的方式分布,平均值较低。正如预期的那样,它们大多不在患者记录中。这两个例子展示了不同的计算器结果如何提供有关合格人群特定风险的独特见解。
图5f显示了不同类型风险计算器应用到的患者数量。总体而言,在MIMIC-III数据集中,死亡风险是ICU患者最常考虑的风险,超过60%的患者(6,060名中的9,822名)至少符合一个与死亡风险相关的计算器。心脏事件(3,174)和中风风险(3,005)也经常计算,其次是呼吸系统事件(2,284)、出血(2,260)和感染(2,227)。对于每个具体的风险,可以可视化类似于图5e的计算结果分布,以研究个体风险水平的队列特征。
这些结果展示了AgentMD在自动化整理临床计算器、应用于患者记录、以及在风险预测任务中的准确性和实用性方面的潜力。尽管AgentMD展现了临床语言代理与临床决策工具整合的前景,但该研究也存在一些局限性。例如,计算器工具的创建局限于PubMed摘要,没有考虑全文文章中更详细的描述。未来的工作应该扩大工具开发的数据来源。另外AgentMD使用GPT-4作为核心LLM,由于其高昂的运营成本和部署上的挑战,可能会引起数据隐私和安全的担忧。当前的评估是在相对较小规模上进行的,未来的研究应该专注于开发更现实的临床计算任务,并在更大规模的患者群体上验证AgentMD的有效性。
论文链接:https://arxiv.org/abs/2402.13225