小罗碎碎念
在统计学和数据可视化领域,探索两个定量变量之间的关系是一种常见的需求。为了更深入地理解这种关系,我们可以使用多种图形表示方法,这些方法在本质上是对传统图形的扩展和变体。
-
散点图:这是最基本的图形,用于展示两个变量之间的关系。在散点图中,每个数据点在X轴和Y轴上的坐标分别对应两个变量的值。通过观察数据点的分布,我们可以初步了解变量之间的相关性。
-
六边形分箱图(Hexbin Plot):这种图形使用六边形的格子来代替传统的矩形格子。每个六边形区域内的数据点数量通过颜色的深浅来表示,从而提供了一种更平滑的视觉效果。六边形分箱图特别适合于展示数据的局部密度,因为它可以减少边界效应。
-
二维直方图(2D Histogram):与一维直方图类似,二维直方图通过在X轴和Y轴上划分区间,计算每个小矩形区域内的数据点数量。这种图形可以直观地展示数据在不同区间的分布情况,但可能会因为边界效应而产生误导。
-
二维密度图(2D Density Plot):这种图形通过计算数据点的局部密度来展示变量之间的关系。与直方图不同,密度图使用平滑的曲线来表示数据点的分布,从而提供了更连续的视觉效果。
-
核密度估计(Kernel Density Estimation, KDE):这是一种非参数方法,用于估计数据的概率密度函数。在二维空间中,KDE可以生成一个平滑的曲面,展示两个变量的联合分布。这种方法不依赖于事先定义的区间,因此可以更灵活地适应数据的分布。
-
等高线图(Contour Plot):等高线图通过连接具有相同密度估计值的点来形成等值线。这种图形可以清晰地展示数据的局部模式和趋势,尤其是在数据点分布不均匀的情况下。
-
热力图(Heatmap):热力图是一种颜色编码的矩阵,通常用于展示两个分类变量之间的关系。在二维空间中,热力图可以扩展为展示两个定量变量的联合分布,其中颜色的深浅代表数据点的密度。
-
散点图矩阵(Scatterplot Matrix):这是一种将多个散点图组合在一起的图形,用于同时探索多个变量之间的关系。每个散点图都代表两个变量之间的配对关系,而矩阵的对角线上可以放置直方图或箱线图来展示单个变量的分布。
通过这些图形的组合和变体,我们可以从不同角度和层面上分析和理解数据,从而获得更深入的洞察。每种图形都有其独特的优势和局限性,因此在实际应用中需要根据数据的特点和分析的目的来选择合适的图形表示方法。
一、图形展示
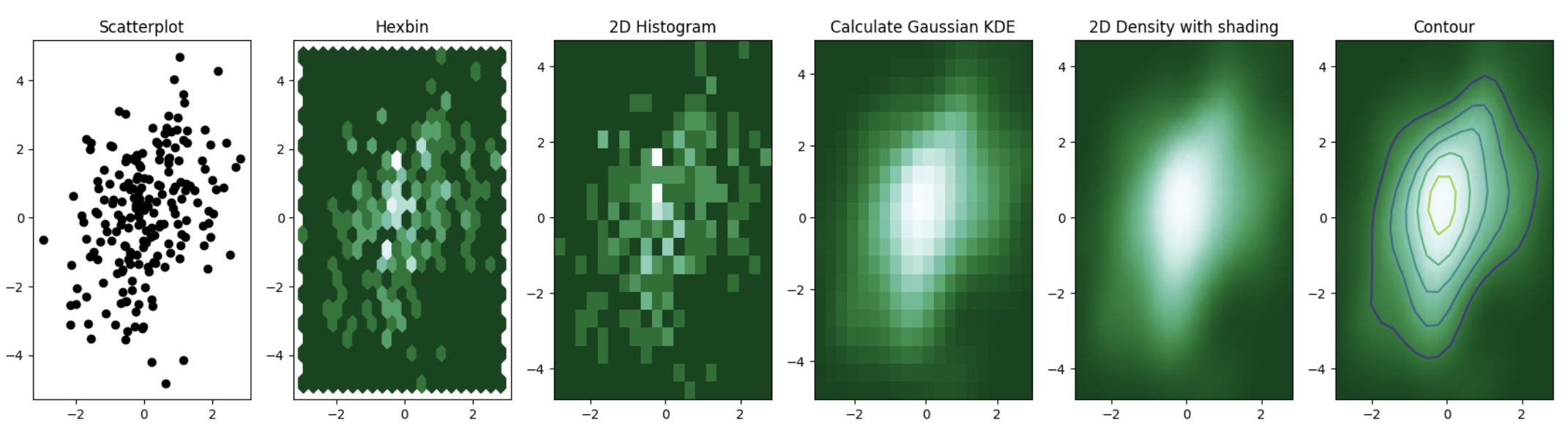
这段代码主要展示了如何使用Python的matplotlib和scipy库来绘制二维数据的散点图、六边形图、二维直方图以及高斯核密度估计(Gaussian KDE)的密度图和等高线图。
# 导入所需的库
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import gaussian_kde as kde
# 创建数据:200个二维正态分布的点
data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200)
x, y = data.T # 将数据转置,方便后续处理
# 创建一个包含6个子图的图形
fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5))
# 绘制散点图
axes[0].set_title('Scatterplot')
axes[0].plot(x, y, 'ko')
# 绘制六边形图
nbins = 20
axes[1].set_title('Hexbin')
axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r)
# 绘制二维直方图
axes[2].set_title('2D Histogram')
axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r)
# 计算高斯核密度估计
k = kde(data.T)
xi, yi = np.mgrid[x.min():x.max():nbins*1j, y.min():y.max():nbins*1j]
zi = k(np.vstack([xi.flatten(), yi.flatten()]))
# 绘制高斯核密度估计的密度图
axes[3].set_title('Calculate Gaussian KDE')
axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), cmap=plt.cm.BuGn_r)
# 绘制带有阴影的高斯核密度估计的密度图
axes[4].set_title('2D Density with shading')
axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r)
# 绘制高斯核密度估计的等高线图
axes[5].set_title('Contour')
axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r)
axes[5].contour(xi, yi, zi.reshape(xi.shape))
这段代码首先创建了一个包含200个二维正态分布点的数组,然后使用matplotlib库绘制了散点图、六边形图和二维直方图。接下来,使用scipy库中的高斯核密度估计函数计算数据的密度,并将结果绘制为密度图和等高线图。这些图表可以帮助我们更好地理解数据的分布和密度。
二、二维分布图
二维分布图是一种强大的工具,它可以帮助我们更清晰地理解两个变量之间的关系,尤其是在数据点数量众多且存在大量重叠时。
2-1:散点图的局限性
在传统的散点图中,当两个变量之间存在强相关性或者数据点非常密集时,许多点可能会重叠在一起,形成一个密集的簇。
这会导致视觉上的混淆,使得我们难以分辨个别数据点,也难以识别数据中的模式或趋势。
例如,如果两个变量之间存在线性关系,但是数据点过于集中,我们可能无法直观地看到这个关系。
2-2:二维分布图的优势
二维分布图通过使用颜色梯度或者等高线来表示数据点的密度,从而有效地解决了散点图中的重叠问题。
以下是一些二维分布图的优势:
-
数据点密度的可视化:通过颜色的深浅或者等高线的密集程度,我们可以直观地看到数据点在不同区域的分布密度。
-
模式和趋势的揭示:在二维分布图中,即使数据点非常密集,我们也能够通过颜色的变化或者等高线的分布来识别出潜在的模式和趋势。
-
边界效应的减少:与二维直方图相比,二维密度图使用平滑的核函数来估计数据点的密度,从而减少了边界效应,提供了更平滑的视觉效果。
-
多尺度分析:二维分布图可以同时展示宏观和微观层面的数据特征,帮助我们理解数据的整体结构和局部细节。
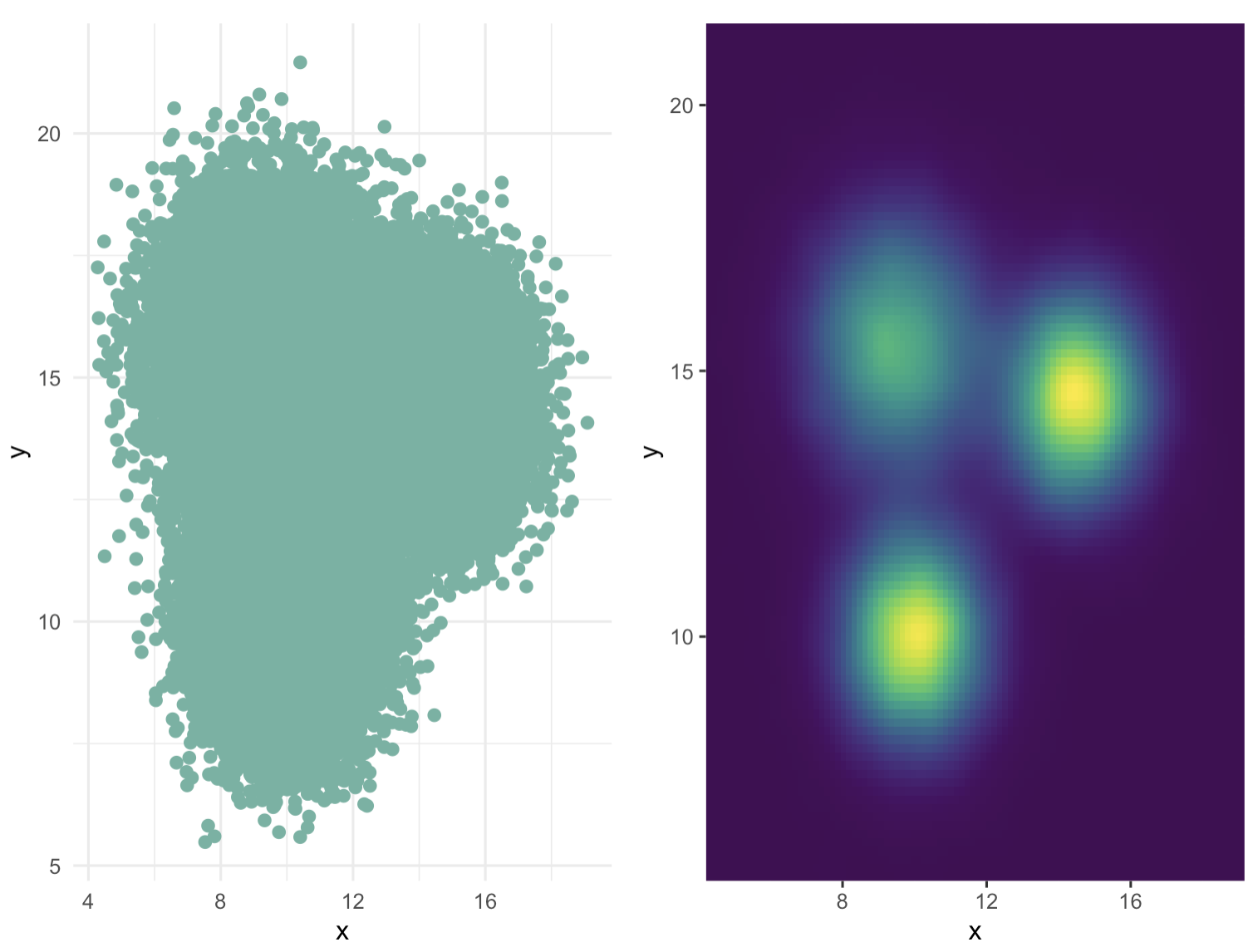
2-3:示例:重叠散点图与二维密度图的比较
假设我们有一个包含数千个数据点的数据集,这些数据点在散点图上高度重叠,使得我们难以识别任何模式。当我们将这些数据点转换为二维密度图时,情况会有很大的不同:
-
重叠散点图:数据点密集地聚集在一起,形成了一个几乎无法区分个别点的黑色或深色区域。这种图很难提供有用的信息。
-
二维密度图:通过颜色梯度,我们可以看到数据点的分布呈现出某种模式。例如,如果数据点在某些区域的密度明显高于其他区域,这可能表明两个变量之间存在某种非线性关系或者交互效应。
2-4:隐藏模式的显现
在二维密度图中,原本在散点图中被隐藏的模式可能会变得非常明显。例如:
-
聚类:如果数据点在某些区域形成了高密度的簇,这可能表明存在某些未观察到的分组或类别。
-
非线性关系:如果数据点的密度呈现出某种曲线或者非线性模式,这可能揭示了两个变量之间的复杂关系。
-
异常值:在某些情况下,二维密度图可以帮助我们识别出异常值或者离群点,这些在散点图中可能不容易被发现。
2-5:代码演示
二维分布图在避免散点图中数据点重叠方面非常有用。以下是一个示例,展示了重叠散点图与二维密度图之间的区别。在第二种情况下,一个非常明显的隐藏模式显现出来:
# 导入所需的库
library(tidyverse) # tidyverse包提供了数据整理和图形制作的工具
library(hrbrthemes) # hrbrthemes包提供了一些美观的主题
library(viridis) # viridis包提供了一系列颜色渐变方案
library(patchwork) # patchwork包允许你组合多个图形
# 创建数据集
a <- data.frame( x=rnorm(20000, 10, 1.2), y=rnorm(20000, 10, 1.2), group=rep("A",20000))
b <- data.frame( x=rnorm(20000, 14.5, 1.2), y=rnorm(20000, 14.5, 1.2), group=rep("B",20000))
c <- data.frame( x=rnorm(20000, 9.5, 1.5), y=rnorm(20000, 15.5, 1.5), group=rep("C",20000))
data <- do.call(rbind, list(a,b,c)) # 将三个数据框合并为一个
# 创建第一个图形p1:散点图
p1 <- data %>%
ggplot( aes(x=x, y=y)) + # 使用ggplot2语法创建图形,并指定x和y变量
geom_point(color="#69b3a2", size=2) + # 添加散点图层,设置颜色和大小
theme_minimal() + # 使用最小化主题
theme(
legend.position="none" # 移除图例
)
# 创建第二个图形p2:二维密度图
p2 <- ggplot(data, aes(x=x, y=y) ) +
stat_density_2d(aes(fill = ..density..), geom = "raster", contour = FALSE) + # 计算二维密度并添加到图形中
scale_x_continuous(expand = c(0, 0)) + # 设置x轴的范围和扩展
scale_y_continuous(expand = c(0, 0)) + # 设置y轴的范围和扩展
scale_fill_viridis() + # 使用viridis颜色渐变方案
theme(
legend.position='none' # 移除图例
)
# 将p1和p2组合成一个图形
p1 + p2
这段代码首先创建了一个包含60000个数据点的数据集,其中每个数据点都有x和y坐标以及一个分组标签(A、B或C)。然后,它创建了两个图形:一个是散点图(p1),显示了所有数据点的位置;另一个是二维密度图(p2),显示了数据点在二维空间中的分布密度。最后,使用patchwork包将这两个图形组合成一个复合图形。
三、变体
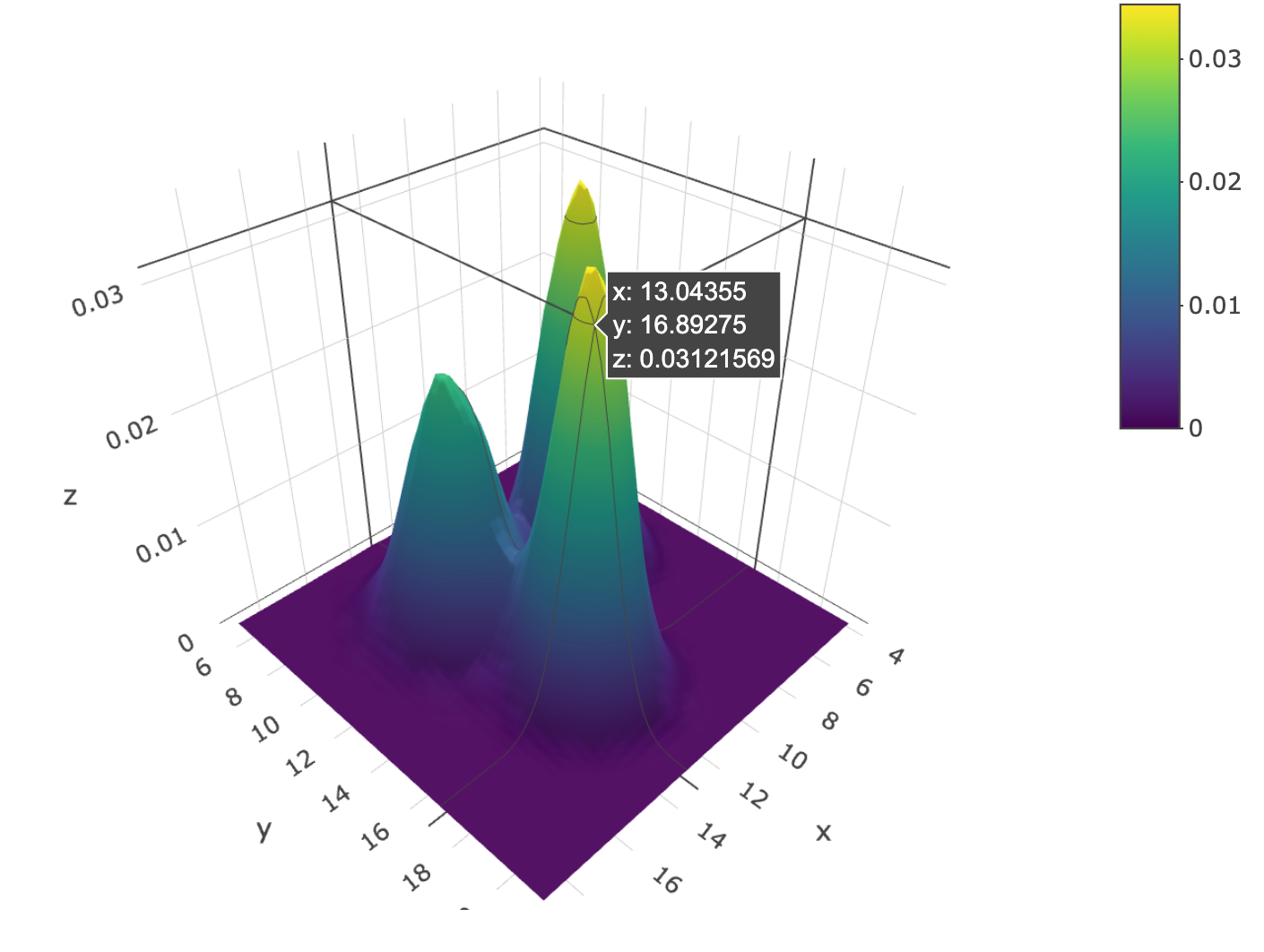
在数据可视化领域,二维分布图的三维表现形式确实是一种在特定情况下非常有用的工具。通过将传统的散点图信息转换为三维表面图,我们可以更直观地观察数据点在三维空间中的分布情况。
3-1:三维表面图的构建
首先,我们可以将数据点分布在一个网格上,这个网格可以由六边形或正方形组成,类似于二维直方图或六边形分箱图。
接着,不是简单地通过颜色渐变来表示数据点的密度,而是通过计算每个网格单元内的数据点数量,将其转换为三维空间中的一个高度值。
这样,每个网格单元的密度就通过其在Z轴上的高度来表示,形成了一个三维表面 。
3-2:群组的识别
通过这种三维表面图,我们可以更容易地识别数据中的群组。
例如,如果数据中存在三个不同的群组,它们可能会在三维表面图中形成三个明显的高峰。
这些高峰在视觉上非常突出,使得我们能够快速地识别出数据的聚类结构 。
3-3:数据的深度洞察
三维表面图不仅帮助我们识别群组,还可以提供对数据分布深度的洞察。
通过观察不同高度的表面,我们可以了解每个群组的密度和大小,甚至可以分析群组之间的相对位置和可能的关联 。
3-4:交互性和动态性
现代的数据可视化工具,如Echarts,允许用户与三维散点分布图进行交互,例如通过旋转、缩放来从不同角度观察数据。
这种交互性极大地增强了我们对数据的理解,并使得复杂的数据集更加易于探索和分析 。
3-5:代码演示
# 导入所需的库
library(plotly) # plotly库用于创建交互式图形
library(MASS) # MASS库包含了kde2d函数,用于计算二维核密度估计
# 假设data是一个已经存在的数据框,其中包含x和y两列数据
# 计算二维核密度估计
kd <- with(data, MASS::kde2d(x, y, n = 50))
# 使用plotly绘制三维曲面图
plot_ly(x = kd$x, y = kd$y, z = kd$z) %>% add_surface()
这段代码使用了R语言的plotly和MASS库来计算二维数据的核密度估计(KDE)并绘制三维曲面图。


![[Python可视化]空气污染物浓度地图可视化](https://i-blog.csdnimg.cn/direct/9ae234d7ce834bd0b5f2086270e225cb.png)