2024年5月,关于推荐模型自动编译优化的论文《RECom: A Compiler Approach to Accelerate Recommendation Model Inference with Massive Embedding Columns》在系统领域顶会ASPLOS 2024上中选并进行了展示,并被授予了Distinguished Artifact Award 荣誉,以表彰RECom的易用性与结果的可复现性。

RECom是一个旨在加速GPU上深度推荐模型推理的机器学习编译器,解决了已有机器学习编译器无法有效优化推荐模型中重要的嵌入层计算的问题。RECom提出了一种新颖的面向子图间并行的融合方法,以在单个GPU内核中生成处理大量嵌入列的高效代码,大幅减少了内核启动的开销并显著提升了GPU的利用率。通过一个形状计算简化模块来解决动态形状下形状计算带来挑战,并通过一个嵌入列子图优化模块来消除冗余计算。在阿里巴巴的四个真实的内部生产推荐模型和两个生成模型上评估了RECom,实验表明,RECom在端到端推理延迟和吞吐量方面分别优于TensorFlow基线6.61倍和1.91倍。
背景
基于深度学习的推荐模型在各大企业的业务中变得越来越重要。通过为用户推荐合适的商品,能够帮助提升客户体验,增加销售额,以及提高客户保留率。典型的推荐模型包括两部分,即嵌入层和深度神经网络层(DNN)。 在生产环境中,嵌入层通常由对应不同特征字段的大量嵌入列(即通过查表将输入特征转换为嵌入向量的子图,如下图中虚线方框所示)组成,它能将输入的特征(比如用户ID,商品ID等)映射到低维的连续向量。
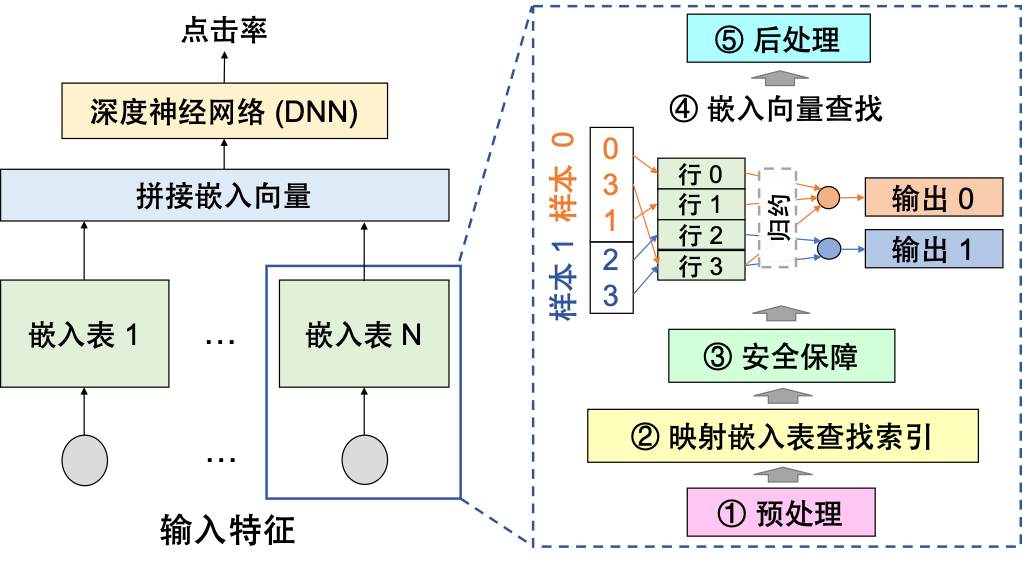
为了获得更高的模型精度,开发人员通常会生成数千个统计特征,并使用不同的嵌入列来处理它们。 然而,处理如此大量的嵌入列是昂贵的。 例如,我们在阿里巴巴的模型上进行的实验表明,嵌入列可以占据GPU上99%以上的端到端推理延迟。 因此,业务中迫切需要对推荐模型中的海量嵌入列进行优化。
挑战
虽然目前已有一些加速嵌入层计算的手写算子库[1],但它们很难在真实业务中被广泛应用,因为它们不可能在库中遍历嵌入层中所有可能的算子组合。此外,出于隐私考虑,实际业务中经常要求根据模型的计算图IR(比如TensorFlow GraphDef)而非源代码来进行优化。然而,一个公司的业务中通常会包含大量具有不同嵌入列结构的模型,并且一个模型可以包含上百万行的IR。因此,基于这些IR再手工地使用这些算子库来重新搭建所有的业务模型是不现实的。
另一方面,机器学习编译器,如XLA[2]等被广泛地应用于自动加速机器学习模型的计算。然而,目前的机器学习编译器主要关注于DNN的计算,而无法为嵌入层中包含的大量嵌入列提供有效的优化。它们主要存在以下三个问题:
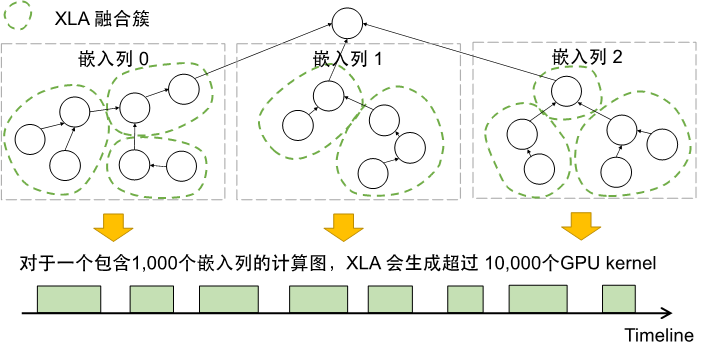
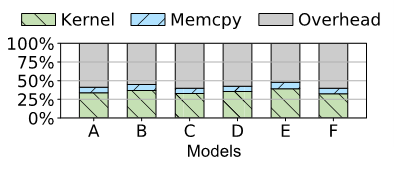
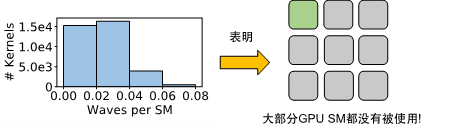
首先,在 GPU 上为数千个嵌入列中的大量算子生成有效的代码是一项挑战。现有编译器的算子融合策略既无法有效消除模型中大量的非计算开销(包括内核启动与算子调度),也无法充分利用模型中子图间的并行性。我们在一个特定模型的实验上发现,XLA 可以为该模型生成超过10,000个GPU内核,这会引入大量的非计算开销,进而导致GPU的活跃时间仅占33%。并且,线上推理时输入的batch size通常不会太大,导致大多数生成的GPU内核的Waves per SM都非常小(小于 0.06),意味着大部分的GPU SM在执行中都没有被利用。
其次,推荐模型通常具有动态形状(dynamic shapes)。传统的机器学习编译器通常依赖张量的形状来进行各种优化,而推荐模型的计算图中的张量形状一般无法在编译期获取。一方面,动态形状造成的张量间形状关系信息缺失阻碍一些编译优化的pass。另一方面,动态形状场景下,部分算子(如SparseReshape)需要形状的输入,继而引入了大量形状计算。形状计算与张量计算的耦合使得计算图变得复杂,阻碍了后续的图优化。
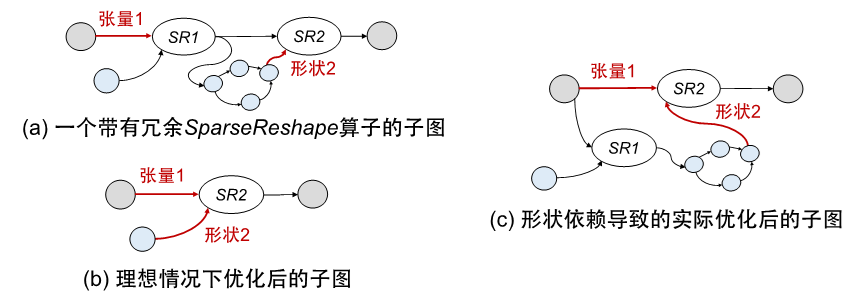
下图(a)展示了一个级联SparseReshape的子图,其中蓝色的算子表示形状计算。由于SR1输出的sparse tensor的消费者只有SR2,因此第一次reshape是冗余的。理想情况下,编译器检测到这样的情况后可以直接把SR1的输入张量(即张量1)连接到SR2,越过冗余的SR1,如(b)中所示。然而,由于形状计算与张量计算的耦合,导致实际转化后的图会如(c)中所示,SR1并不能被正确的优化掉。
第三,现有的机器学习编译器忽视了推荐模型中存在的大量冗余计算。通过对业务模型的分析,我们观察到现有模型普遍存在大量的冗余计算。例如,使用TensorFlow框架进行嵌入表查找时会引入一些边界检查的计算,而这些检查在整个嵌入列子图的上下文里可能是冗余的,因为在经过哈希/分桶等操作后,用于嵌入表查找的索引已经满足了要求。在极端情况下,一个嵌入列中80%的GPU计算时间可能都是冗余的。
破局
我们提出了第一个端到端的推荐模型优化编译器RECom来解决以上的问题。
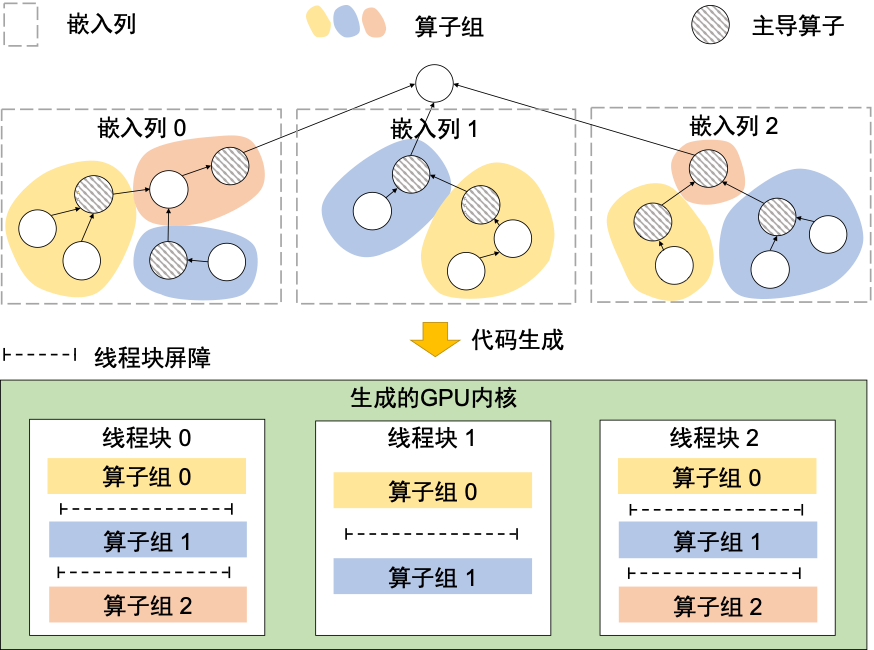
针对大量嵌入列的GPU代码生成,RECom 提出了一种子图间并行性导向的算子融合方法,将嵌入层中数千个嵌入列包含的大量算子全部融合(fuse)到一个GPU kernel中。一方面,这种方法使得RECom 能够消除频繁的内核启动与框架调度,显著减少嵌入层执行时的非计算开销。另一方面,为了生成具有高并行性的代码,RECom 将独立的嵌入列映射到不同组的GPU 线程中。每个线程组中的线程协作处理一个嵌入列,并利用GPU 的层次存储来进行中间数据缓冲和线程间通信。通过这种方式,RECom 可以有效地利用GPU 来挖掘推荐模型嵌入层中算子内部和嵌入列间的并行性。
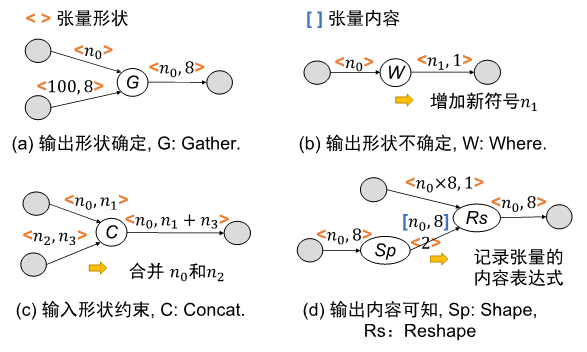
为了解决动态形状与形状计算带来的问题,RECom提出了一种基于符号表达式的方法。类似于BladeDISC[3],RECom 通过下图中的四种pattern构建了嵌入列的全局符号形状表达式,并利用这些表达式来确定不同张量的形状间关系。
得到形状的符号表达式后,RECom进一步将所有形状计算子图用统一的算子进行重构。重构后的ShapeConstruct算子仅依赖于生成所需符号的算子,而非依赖于原计算子图的输入。这样,RECom得以解耦张量计算与形状计算来简化计算图。回到之前冗余SparseReshap的例子,再经过形状计算重构后,SR2输入形状对SR1的依赖被消除,因此在经过原来的编译优化pass后,我们能得到下图的结果,成功去除了冗余的SR1。

对于嵌入层中存在的大量冗余计算,我们在RECom中开发了一个嵌入列子图优化模块,针对性地为常见的冗余计算设计了优化。具体细节可以参考我们的论文。
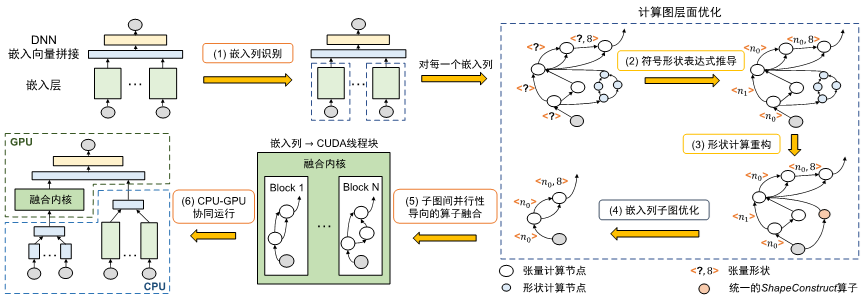
RECom的整个编译优化流程如下图所示。
与此同时,阿里云PAI团队与悉尼大学合作的论文《MonoNN: Enabling a New Monolithic Optimization Space for Neural Network Inference Tasks on Modern GPU-Centric Architectures》在OSDI2024中选,论文创新性地提出了MonoNN,这是第一个能够为单个GPU上的常见静态神经网络(NN)推理任务提供新的整体设计和优化空间的机器学习优化编译器。MonoNN可以将整个神经网络容纳到单个GPU核心中,大大减少了非计算开销,并从新形成的整体优化空间提供进一步细粒度的优化机会。最重要的是,MonoNN确定了各种NN运算符之间的资源不兼容性问题,这是创建这样一个整体优化空间的关键设计瓶颈。MonoNN通过系统地探索和利用跨不同类型的NN计算的并行补偿策略和资源权衡,并提出了一种新的独立于调度的群体调谐技术来显著缩小极其庞大的调谐空间。评估表明,MonoNN的平均加速比比最先进的框架和编译器提高了2.01倍。具体而言,就端到端推理性能而言,MonoNN在TVM、TensorRT、XLA和AStitch方面的表现分别高达7.3倍、5.9倍、1.7倍和2.9倍。目前,MonoNN已开源,如需获取MonoNN源代码请前往GitHub - AlibabaResearch/mononn;
论文地址:RECom: A Compiler Approach to Accelerating Recommendation Model Inference with Massive Embedding Columns | Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 4
论文信息
论文标题:《RECom: A Compiler Approach to Accelerating Recommendation Model Inference with Massive Embedding Columns》
论文地址:RECom: A Compiler Approach to Accelerating Recommendation Model Inference with Massive Embedding Columns | Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 4
参考文献
[1] NVIDIA. NVIDIA-Merlin/HugeCTR. https://github.com/NVIDIA-Merlin/HugeCTR, 2023.
[2] Google. XLA: Optimizing Compiler for Machine Learning. https://www.tensorflow.org/xla, 2023.
[3] Zhen Zheng, Zaifeng Pan, Dalin Wang, Kai Zhu, Wenyi Zhao, Tianyou Guo, Xiafei Qiu, Minmin Sun, Junjie Bai, Feng Zhang, Xiaoyong Du, Jidong Zhai, and Wei Lin. BladeDISC: Optimizing Dynamic Shape Machine Learning Workloads via Compiler Approach. Proc. ACM Manag. Data, 1(3), nov 2023.


















