文章目录
- week52 Distribution Shift of GNN
- 摘要
- Abstract
- 一、文献阅读
- 1. 题目
- 2. Abstract
- 3. 预测标准
- 3.1 问题提出
- 3.2 图结构
- 3.3 分布转移
- 4. 文献解读
- 4.1 Introduction
- 4.2 创新点
- 4.3 实验过程
- 5. 结论
- 二、若依框架
- 1. 框架概述
- 2. 核心功能
- 3. 技术栈
- 4. 框架特点
- 优缺点
- 小结
- 参考文献
week52 Distribution Shift of GNN
摘要
本周阅读了题为PM2.5 forecasting under distribution shift: A graph learning approach的论文。这项工作提出了一个新的PM2.5预测数据集,其特征是随时间的分布变化。使用这个新的基准,在两种数据分割设置(按时间分割和随机分割)下评估了一组基于图和非基于图的机器学习模型。第一种设置提出了分布移位的挑战,而第二种设置旨在消除分布移位的影响。实验结果表明,基于图的机器学习模型比非基于图的模型更容易受到分布变化的影响。
Abstract
This week’s weekly newspaper decodes the paper entitled PM2.5 forecasting under distribution shift: A graph learning approach. This work introduces a novel PM2.5 forecasting dataset characterized by temporal distribution changes. Leveraging this new benchmark, a set of graph-based and non-graph-based machine learning models were evaluated under two data splitting settings: temporal splitting and random splitting. The first setting poses a challenge of distribution shift, whereas the second setting aims to mitigate the impact of distribution shift. Experimental results demonstrate that graph-based machine learning models are more vulnerable to distribution changes compared to non-graph-based models.
一、文献阅读
1. 题目
标题:PM2.5 forecasting under distribution shift: A graph learning approach
作者:Yachuan Liu; Jiaqi Ma; Paramveer Dhillon1; Qiaozhu Mei
发布:AI Open Volume 5, 2024, Pages 23-29(中科院二区)(JCR一区)
链接:https://doi.org/10.1016/j.aiopen.2023.11.001
2. Abstract
该文提出了一个基于图的机器学习的新基准任务,旨在预测地理分布的环境传感器网络观察到的未来空气质量(PM2.5浓度)。虽然之前的工作已经成功地将图神经网络(gnn)应用于广泛的时空预测任务,但本文引入的新的基准任务带来了一个在基于图的时空学习背景下研究较少的技术挑战:分布在很长一段时间内的变化。该文的一个重要目标是了解gnn在分布移位下的时空行为。该文对基于图和非基于图的机器学习模型在两种数据分割方法下进行了全面的比较研究,一种会导致分布偏移,另一种不会。实证结果表明,与非基于图的模型相比,GNN模型更容易受到分布偏移的影响,这需要在实践中部署时空GNN时特别注意。
3. 预测标准
3.1 问题提出
PM2.5预测的目标是使用观测到的空气质量记录、气象数据(例如温度、湿度和风力水平)和其他来自二进制数据中心监测站的环境数据来预测未来整个感兴趣地区的空气PM2.5浓度。监测站网络可以表示为无向图 G = ( V , E , A ) \mathcal G = (V,E,A) G=(V,E,A)。V为节点(即监测站)的集合, ∣ V ∣ = N |V|=N ∣V∣=N。其中,E是边缘的集合,而变量A是一个加权邻接矩阵 A ∈ R N × N A∈R^{N\times N} A∈RN×N,它是基于监测站之间的地理邻近性和/或历史相关性而建立的。假设监测站每隔一段时间(例如每小时)记录一次空气质量和其他气象数据。然后在任何记录的时间戳t,有 X t ∈ R N × F X_t\in R^{N\times F} Xt∈RN×F,其中的F是从记录中提取的特征的数量,以及PM2.5浓度 Y t ∈ R N Y_t\in R^N Yt∈RN。图1提供了数据结构的可视化。tip:文中所说的样本是指与某个时间戳相关联的(所有站点的)数据。

在任意时间点𝑡,给定各站点过去的PM2.5浓度的观测值和气象数据,以及监测站网络信息 G = ( V , E , A ) \mathcal G = (V,E,A) G=(V,E,A),目标是通过预测函数 h ( ⋅ ) h(\cdot) h(⋅)预测未来时间点 t + T t+T t+T最可能的PM2.5浓度 Y t + T Y_{t+T} Yt+T,即:

3.2 图结构
将监测站视为图中的节点,如果来自另一个监测站的信息有助于底层监测站的预测,我们希望将两个监测站连接起来。考虑到这一点,可以通过地理邻近性和历史PM2.5浓度相关性来构建相邻矩阵。
地理位置邻接。加权邻接矩阵可以根据监测站之间的距离计算。使用高斯核可以形成各元,其中, A i j A_{ij} Aij为边缘 E i j E_{ij} Eij的权重。其中, σ \sigma σ为高斯核的标准差, ϵ \epsilon ϵ为控制图稀疏度的阈值。
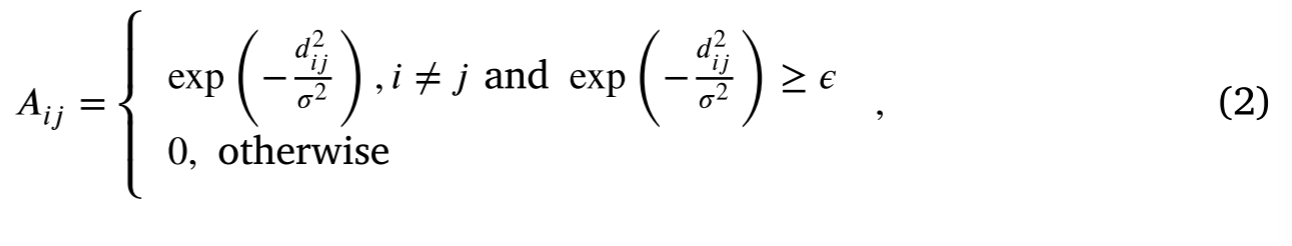
构建的图有415个节点,边的个数和边的平均权值如表1所示。在构造中,使用φ = 100,图中邻接矩阵条目即权重的分布如图2所示。将是一个超参数。

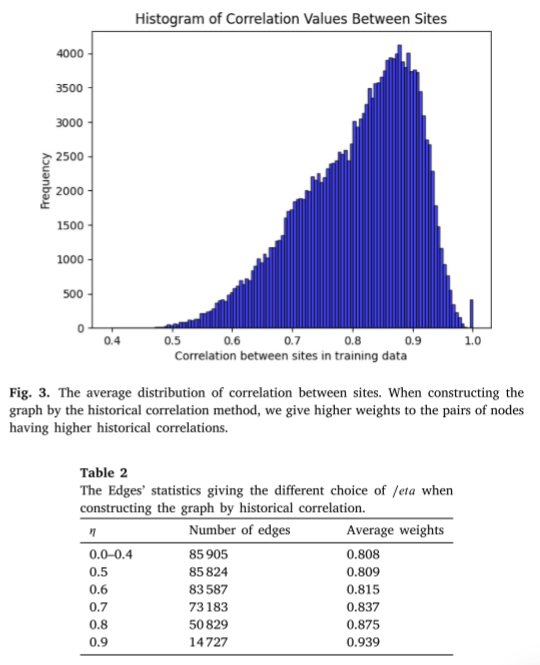
通过历史数据关联。监测站之间的距离有时不能正确反映其PM2.5浓度的相似性。由于两个站点周围和之间的外部地理特征,例如地形,可能会出现例外情况。为了避免这一问题,另一种构建图表的方法可以利用站间历史PM2.5浓度的相关性。在这种情况下,可以将其组成为:

构建的图有415个节点,边的个数和边的平均权值如表2所示。在构造中,使用 ϕ \phi ϕ = 100,图中邻接矩阵条目即权重的分布如图3所示。 η \eta η将是一个超参数。
3.3 分布转移
图4显示了按时间分段设置下的分布位移。上图显示了所有站点的每小时PM2.5浓度平均值,它清楚地显示出随时间变化的非平稳模式。下图进一步可视化了训练集、验证集和测试集中标签的直方图,直接反映了分布的变化。

4. 文献解读
4.1 Introduction
该文提出了一个新的空气质量预测数据集作为基于图的时空学习的一个新的基准任务。空气污染物数据通常是从地理上分布的环境传感器或监测站收集的。在每个站点,数据被表示为一个时间序列。因此,监测网络(例如,一个城市或一个州的各个地点)收集的空气污染物数据自然是时空数据。
该数据集的一个关键特征是预测目标在很长一段时间内具有分布移位,这是时间序列数据通常具有的特性
对近年来发展的时空gnn进行了分布移位的实证评价。特意设计了两个数据分割设置来研究分布移位的影响。在第一种设置中,我们按时间顺序将数据分为训练集、验证集和测试集,这是处理时间序列数据时的常用做法。在第二种设置中,作为控制设置,将所有时间戳随机分成三组,而不考虑时间顺序。这样,我们在很大程度上消除了训练集和测试集之间的分布偏移效应。实验结果表明,一般来说,测试的时空gnn在第二种设置中优于非基于图的机器学习方法,但在第一种设置中表现不如非基于图的机器学习方法。这一现象需要特别关注时空gnn部署中的分布转移问题。本研究中使用的代码和数据可在GitHub上公开获取。
4.2 创新点
该文的主要贡献如下:
- 提出了评估时空序列数据的新标准
- 给出了新的基于PM2.5的数据集
- 通过实验证明了时空GNN的分布转移性,即在实验中通过消除训练集和测试集之间的分布偏移效应,GNN相较于非基于图方法表现更优;相应的,当考虑数据的时间顺序时,不如非基于图方法
4.3 实验过程
Dataset:
使用的数据集来自中国北方的一个主要城市。全市及周边共有534个监测站。在每个站点,每小时从传感器读数中自动记录PM2.5、温度、湿度、风速和风向等五个特征。地理位置也与每个站点相关联。数据集的时间跨度为2018年9月1日至2018年12月1日。我们承认,短时间是这个数据集的一个限制。然而,短时间跨度放大了分布偏移现象,这给基于图的深度模型的预测任务带来了问题。
在数据预处理中,过滤掉缺失值超过30%的站点,剩下415个站点。然后用线性插值填充缺失值。
对于预测任务,使用过去24 h的观测值预测每个站点提前一天的PM2.5浓度,即在式(1)中设置 t = 24 , T = 24 t=24,T=24 t=24,T=24
参数设置:
以6:2:2的比例将数据集分成训练集、验证集和测试集,并在两种设置下进行分割:按时间分割或随机分割。按时间分割设置通常用于时间序列预测,它在时间范围内用两个分割点分割数据集。在这种设置下,训练集、验证集和测试集覆盖不相交的时间间隔,并且出现分布移位问题。另一方面,随机分割设置会对(不同时间戳的)样本进行洗牌,并将它们随机分割为训练集、验证集和测试集。在此设置下,样本可以被视为独立和同分布(i.i.d)。从而在很大程度上消除了训练、验证和测试数据集之间的分布偏移问题。
使用模型:
- 朴素(Naive):朴素模型只是将当前的观察结果作为未来一天的预测。
- LR:线性回归。
- ARIMA:自回归综合移动平均。在这种情况下,由于ARIMA只能预测一个时间步,因此我们使用它递归地获得𝑇步的预估。
- MLP:具有RELU激活的2层多层感知器。MLP分别考虑每个站点。因此不使用图结构。
- GCN (Kipf and Welling, 2016):具有2层谱图核的图卷积神经网络。图卷积被期望聚合空间信息。
- STGCN (Yu et al., 2018):时空图卷积网络,最初设计用于流量预测。图卷积可以聚合空间依赖性,并嵌入到一维CNN模型中。
- 时域模型:与STGCN相同的模型结构,但没有图卷积。向STGCN提供一个全零的邻接矩阵,这意味着认为所有的台站在预测中都是独立的。这里,时态模型作为STGCN的比较。
- ASTGCN (Guo et al., 2019):基于注意的时空图卷积网络(Attention-Based spatial-temporal Graph Convolution Network),将空间注意和时间注意机制结合起来,更好地捕捉时空特征
对于所有的非时间模型,过去24小时的特征的连接被用作输入。

评估标准:
来评估不同模型性能的度量是RMSE(均方根误差)
邻接矩阵的构建:
使用上述两种方法构建邻接矩阵,并从列表[0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]中调整图稀疏度参数。对于所有基于图的模型,将具有地理邻近邻接矩阵的模型表示为[model Name]-geo,将具有历史相关邻接矩阵的模型表示为[model Name]-cor。
实验结果:
在随机分割设置下。randomsplit设置下的结果如表3所示。首先观察到,STGCN和GCN分别优于非基于图的同行Temporal和MLP。特别是,GCN相对于MLP的优势相当大。STGCN在所有模型中也给出了最好的性能。在这种情况下,图形信息的使用似乎是对PM2.5预测任务的有用补充。
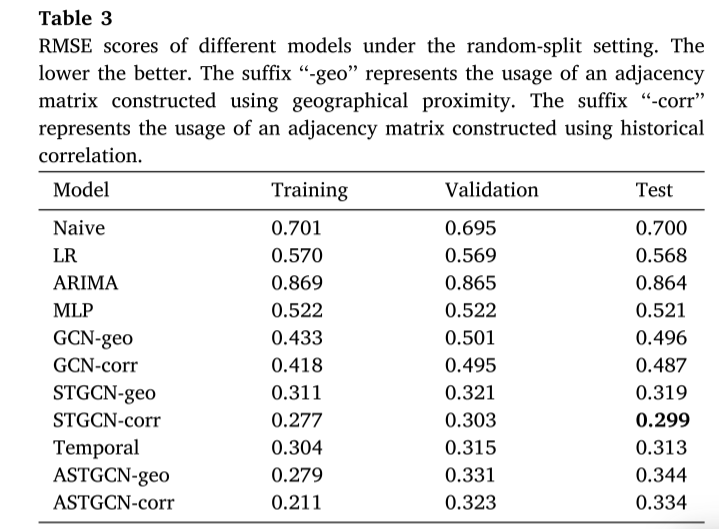
此外,观察到每个模型的训练、验证和测试集的RMSE分数相对一致,这表明训练和验证误差是测试误差的良好估计。
对于所有基于图的模型,对于使用不同邻接矩阵的相同模型,“-corr”比“-geo”具有更好的性能。
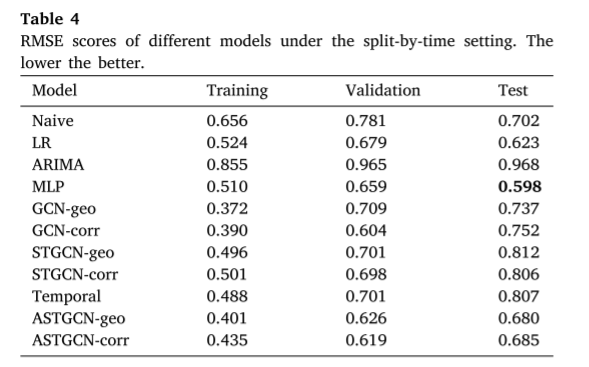
在按时间分割设置下。按时间分割设置的结果如表4所示。与随机分割设置下的结果相反,我们观察到由于分布移位的影响,每个模型的训练集、验证集和测试集的RMSE分数有很大不同。此外,一个关键的观察是,基于图的机器学习模型通常在性能上失去了统治地位。这表明基于图表的模型更容易受到分布变化的影响。对于所有基于图的模型,对于使用不同邻接矩阵的同一模型,在按时间分割设置下,没有看到哪种邻接矩阵更适合使用的明显趋势。
5. 结论
这项工作提出了一个新的PM2.5预测数据集,其特征是随时间的分布变化。使用这个新的基准,在两种数据分割设置(按时间分割和随机分割)下评估了一组基于图和非基于图的机器学习模型。第一种设置提出了分布移位的挑战,而第二种设置旨在消除分布移位的影响。实验结果表明,基于图的机器学习模型比非基于图的模型更容易受到分布变化的影响。
二、若依框架
若依框架(RuoYi)是一个基于Spring Boot的快速开发平台,旨在为企业提供一种快速构建应用程序的方式。以下是对若依框架的详细介绍:
1. 框架概述
- 技术基础:若依框架基于Spring Boot、MyBatis、Thymeleaf等经典技术组合,同时融入了Spring Security、Apache Shiro等多种安全框架和Mybatis、JPA等流行持久化框架。
- 设计原则:采用模块化设计,便于模块的升级、增减,同时Maven多项目依赖使得项目结构更加清晰。
- 应用场景:适用于企业级应用程序开发、快速原型开发以及中小型企业信息化建设等场景。
2. 核心功能
- 权限管理:若依框架提供了完善的权限管理模块,包括角色管理、权限分配、数据范围控制等功能,确保系统的安全性和灵活性。
- 代码生成:内置代码生成器,支持根据数据库表结构自动生成实体类、Mapper、Service、Controller等代码,提高开发效率。
- 前后端分离:采用前后端分离的设计思路,前端使用Vue.js等框架开发,通过RESTful API与后端交互,提高系统的可维护性和扩展性。
- 多数据源支持:简单配置即可实现多数据源的切换,满足复杂应用场景的需求。
- 系统监控:支持服务监控、数据监控和缓存监控功能,帮助开发人员及时发现和解决系统问题。
3. 技术栈
- 后端技术:Spring Boot、Spring MVC、Spring Security、MyBatis、Hibernate Validation等。
- 前端技术:Vue.js、Bootstrap、Thymeleaf等。
- 微服务相关:Spring Cloud Alibaba、Nacos、RocketMQ、Sentinel、Seata等。
- 其他组件:Redis、MySQL、Druid、MyBatis Plus、Dynamic Datasource等。
4. 框架特点
- 高效率:通过前后端分离、代码生成等功能,提高开发效率。
- 安全性:完善的权限管理模块和XSS防范机制,确保系统安全。
- 灵活性:模块化设计使得系统易于扩展和维护。
- 国际化:服务端及客户端均支持国际化,满足不同语言环境的需求。
优缺点
优点:
- 高度集成的开发框架,支持快速开发和部署。
- 代码简单清晰明了,易于维护。
- 提供了自定义组件等功能,可满足各种需求。
- 前后端分离的设计思路,使应用更加灵活,易于扩展。
小结
对近年来发展的时空gnn进行了分布移位的实证评价。特意设计了两个数据分割设置来研究分布移位的影响。在第一种设置中,按时间顺序将数据分为训练集、验证集和测试集,这是处理时间序列数据时的常用做法。在第二种设置中,作为控制设置,将所有时间戳随机分成三组,而不考虑时间顺序。这样,在很大程度上消除了训练集和测试集之间的分布偏移效应。实验结果表明,一般来说,测试的时空gnn在第二种设置中优于非基于图的机器学习方法,但在第一种设置中表现不如非基于图的机器学习方法。这一现象需要特别关注时空gnn部署中的分布转移问题。
参考文献
[1] Yachuan Liu; Jiaqi Ma; Paramveer Dhillon1; Qiaozhu Mei; PM2.5 forecasting under distribution shift: A graph learning approach. AI Open Volume 5, 2024, Pages 23-29 https://doi.org/10.1016/j.aiopen.2023.11.001








![[240822] X-CMD 发布 v0.4.7: 新增 htop 、btop 和 ncdu 模块;优化 colr 和 scoop 模块](https://i-blog.csdnimg.cn/direct/4ce6e4234eca4b76b2b522963fb94d1d.png#pic_center)








