介绍
生物信息学分析,简称生信分析,是一个结合了生物学、计算机科学、信息学和统计学的多学科领域,旨在处理、分析和解释海量的生物数据。随着现代生物技术的发展,尤其是高通量测序(Next-Generation Sequencing, NGS)技术的广泛应用,生物研究的维度和深度都发生了巨大的变化。生信分析因此成为生物医学研究中不可或缺的一部分,不仅推动了基础研究的进展,还对临床应用产生了深远影响。


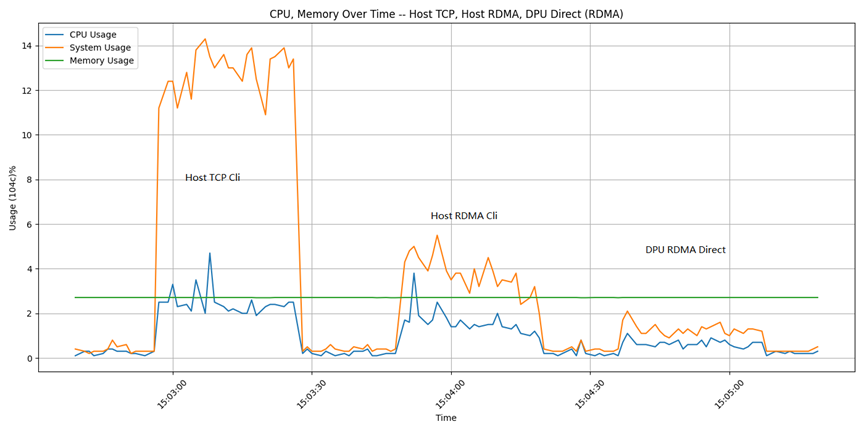
生信圆桌服务器
生信分析的核心步骤
生信分析通常包括多个步骤,每个步骤都对数据的最终解释至关重要:
- 数据收集: 数据收集是生信分析的第一步。生物学研究者可以从多个来源获取数据,包括公共数据库(如GenBank、Ensembl)、实验数据(如RNA-seq、ChIP-seq)和临床数据。数据类型多种多样,包括DNA序列、RNA表达数据、蛋白质结构信息等。这些数据为后续的分析提供了原始素材。
- 数据预处理: 收集到的数据通常需要经过预处理,以保证其准确性和可用性。预处理步骤可能包括去除低质量的读段、消除技术性偏差、标准化数据以及去除重复数据等。对于不同类型的生物数据,预处理方法可能有所不同,但目标都是为了确保分析结果的可靠性。
- 序列比对与注释: 在生信分析中,序列比对是一项关键技术。通过将目标序列与参考基因组或已知序列库进行比对,研究者可以识别出基因、变异位点或其他功能区域。比对算法如BLAST、Bowtie和BWA被广泛应用于基因组学研究。序列注释是比对的后续步骤,目的是为序列赋予生物学功能,这通常涉及将比对的序列映射到已知基因或功能域上。
- 基因组组装与分析: 对于新物种或未完全测序的基因组,基因组组装是生信分析的一个重要步骤。基因组组装的目标是将数百万到数十亿个短序列片段拼接成完整的染色体。组装后的基因组需要进一步分析,以识别功能基因、重复序列、结构变异等。
- 差异表达分析: 差异表达分析是研究不同条件(如疾病状态与健康状态)下基因表达变化的主要方法。通过比较不同样本的RNA-seq数据,研究者可以识别出显著差异表达的基因,这些基因可能与特定的生物学过程或疾病相关。常用的差异表达分析工具包括DESeq2、edgeR和limma。
- 蛋白质相互作用网络分析: 蛋白质相互作用网络分析旨在揭示蛋白质之间的物理或功能相互作用。通过构建网络图,研究者可以识别关键蛋白质节点,这些节点通常在生物过程中发挥重要作用。蛋白质相互作用网络还可以帮助理解疾病的分子机制,提供药物靶点建议。
生信分析的应用领域
生信分析在生物学和医学研究中发挥着越来越重要的作用,其应用领域涵盖了基因组学、转录组学、蛋白质组学、代谢组学等多个“组学”层次。
- 基因组学: 在基因组学中,生信分析被用于人类基因组计划等大型项目。通过比较不同个体或物种的基因组,研究者可以识别出进化保守的基因、结构变异、单核苷酸多态性(SNPs)等,这为疾病研究和个性化医疗提供了重要依据。
- 转录组学: 转录组学分析聚焦于细胞或组织中所有RNA分子的表达情况。生信分析工具如RNA-seq分析帮助研究者解读基因表达调控、识别新型转录本和非编码RNA,并探讨基因表达的时空动态变化。
- 蛋白质组学: 在蛋白质组学中,生信分析被用于蛋白质的鉴定和定量分析。质谱数据的生信处理可以帮助研究者识别出大量的蛋白质分子,了解它们的翻译后修饰以及在不同条件下的丰度变化。
- 临床应用: 生信分析在临床应用中也展现出了巨大的潜力,特别是在癌症基因组学、遗传病诊断和药物靶点发现等领域。通过整合多种生物数据,生信分析可以帮助医生为患者量身定制治疗方案,实现精准医疗。
生信分析的未来发展
随着人工智能和机器学习技术的发展,生信分析正在向更加智能化和自动化的方向迈进。未来,随着数据规模的进一步扩大和算法的不断优化,生信分析将在更加复杂的生物学问题中发挥关键作用。此外,数据共享与标准化也将进一步推动生信分析在全球范围内的协作与应用。
总的来说,生信分析已经并将继续改变生命科学研究的方式,为人类理解生命现象和治疗疾病提供新的视角和工具。