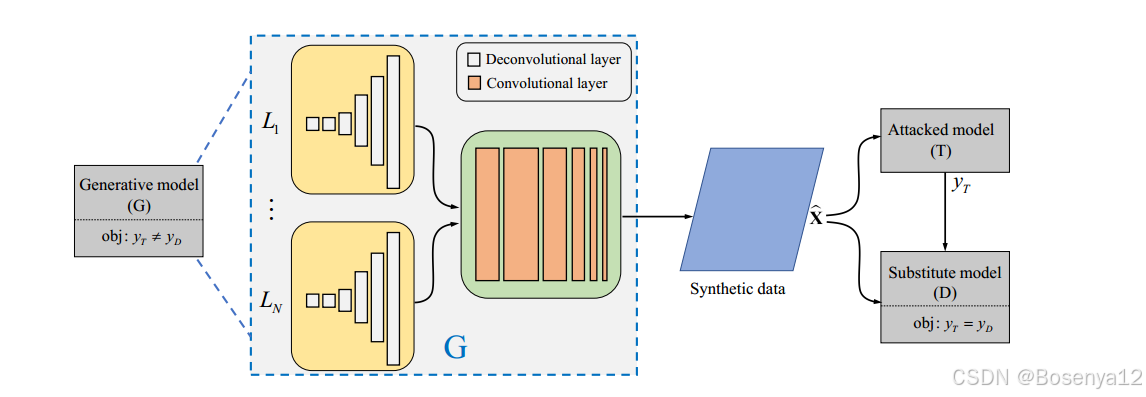
前言
StarRocks 中每次数据摄入都会生成一个新的数据版本,而查询时需要将所有版本数据进行合并才能获得一个正确的结果,如果历史数据版本太多,那么查询时需要读取的文件数也会很多,造成查询效率低下。因而 StarRocks 存在内部任务定期将历史数据版本进行整合,消除重复数据记录,我们称之为 Compaction。
Compaction 是为了将不同版本的数据文件进行整合,合并成大文件的动作,减少系统中小文件数量,进而提升查询效率。相比于存算一体表,StarRocks 存算分离实现了新的 Compaction 调度机制,表现为:
- Compaction 调度由 FE 发起,BE执行。FE 按照 Partition 为单位来发起 Compaction 任务
- Compaction 会生成一个新版本,也走导入的写数据、commit、publish version 这套完整流程
本文旨在描述 StarRocks 存算分离表 Compaction 基本实现原理,帮助开发和运维人员能更好地理解并根据实际需要调整 Compaction 相关配置,以在实践中取得更好地效果。
背景介绍
前面说过,每次导入都会在 FE 内生成一个新版本,而该版本被标记在 Partition 之上。一旦导入事务成功提交,便会更新 Partition 的可见数据版本号,Partition 的数据版本号单调递增。
需要注意的是,一个 Partition 内可能存在多个 Tablet,这些 Tablet 都共享相同的数据版本号,即使一次导入可能只涉及其中部分 Tablet,一旦导入事务成功提交,Partition 下所有的 Tablet 的版本都会相应地得到提升。
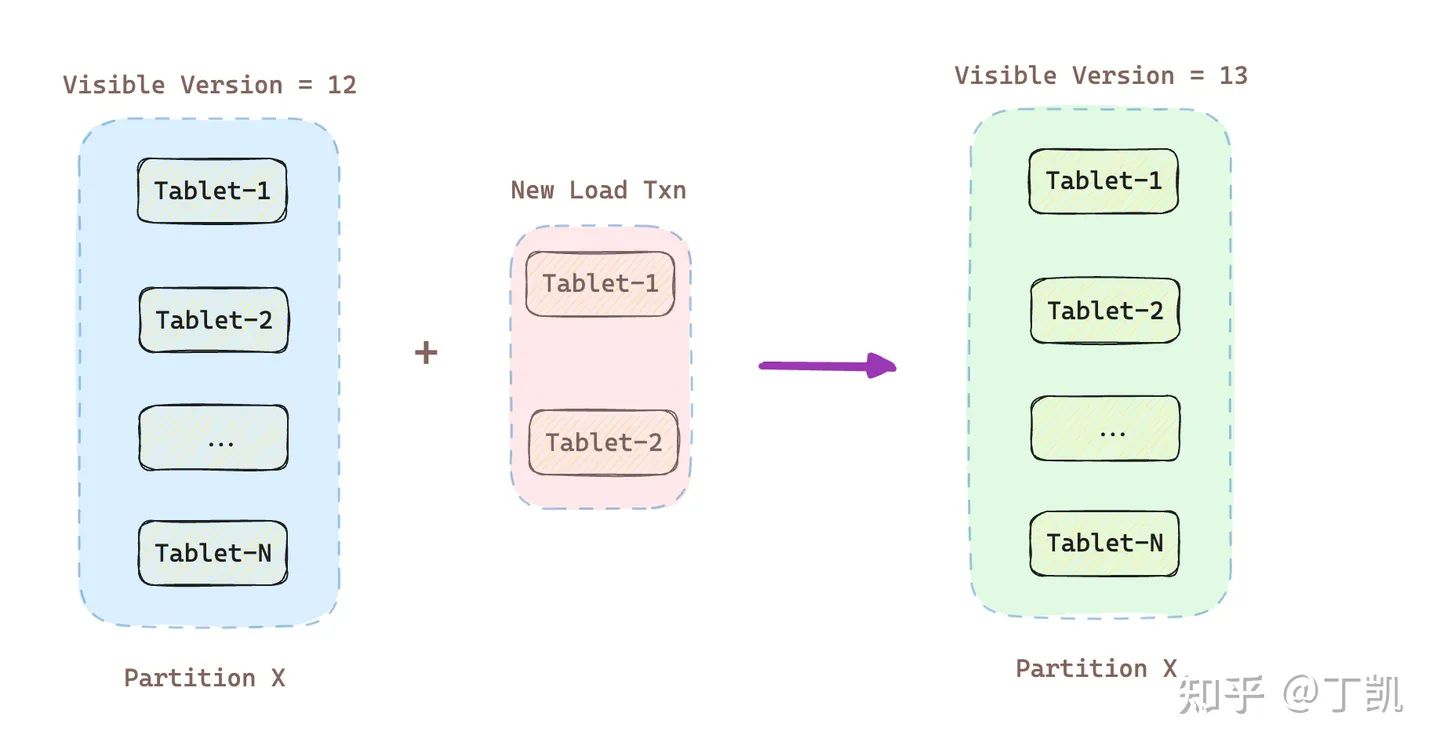
例如上图中,Partition X 内含 Tablet 1 ~ N,当前的可见版本为12,一旦产生新的导入事务 New Load Txn,且该事务成功提交,那么 Partition X 的可见版本就变成了 13。
基本框架
StarRocks 存算分离表 Compaction 由两个角色组成:调度者(Compaction Scheduer)和执行者(Compaction Executor)。调度者通过 RPC 发起 Compaction 任务(Compaction Job),而执行者负责执行 Compaction Job。
在 StarRocks 存算分离中,FE 作为 Compaction Scheduler,而 BE 或者 CN 都作为 Compaction Executor。每个 Compaction Excutor 内都存在一个线程池专门用于执行 Compaction Job。
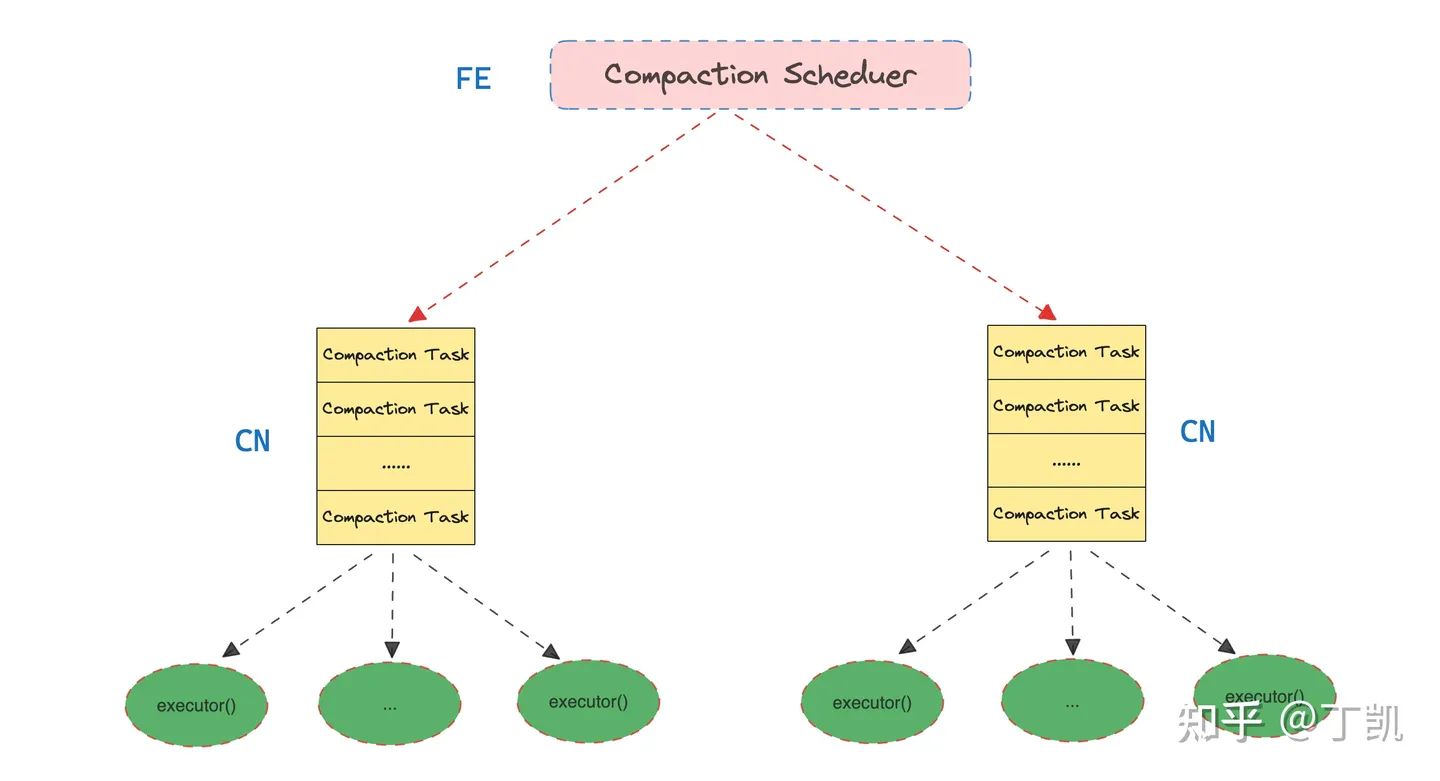
Compaction Scheduer 调度
FE 上存在一个周期性运行线程 Compaction Scheduer,负责调度发起所有的 Compaction Task。FE 以 Partition 为调度的基本单位。
FE 上掌握了每个 Partition 的 Compaction Score 信息,该信息用来表示 Partition 内所有 Tablet 的需要进行 Compaction 的优先级,Compaction Score 越高,表示 Partition 需要合并的紧急程度越高。
每次 Compaction Scheduer 线程运行时,会挑选出当前 Compaction Score 最高的 Partition,并为这些 Partition 构造 Compaction Task。当然,Compaction Scheduer 也会控制每次最多发起的 Compaction Task 数量。
构造 Compaction Task 的逻辑相对比较简单,对于每个 Partition,Scheduler 会获得其所有的 Tablet,然后为每个 CN 构造一个 Compaction Task,Task 内包含需要在该 CN 上执行 Compaction 任务的 Tablet 列表,然后发送 Task 给 CN 节点。
整个流程如下图所示:
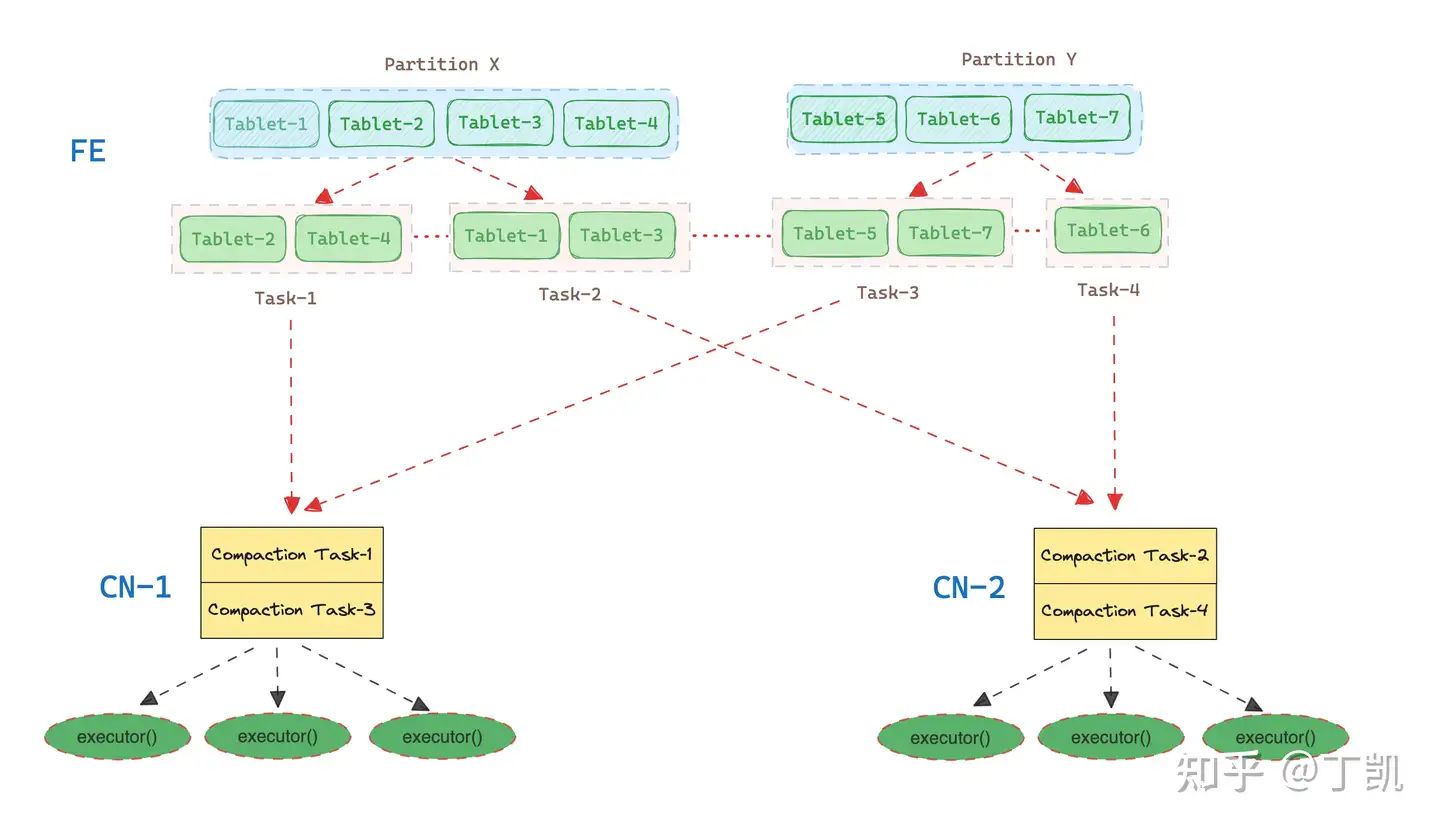
在上图中,FE 上存在两个 Partition 需要执行 Compaction,分别为 Partition X 和 Partition Y。Partition X 内含4个 Tablet(1 ~ 4),而 Partition Y 内含3个 Tablet(5~7)。
Scheduer 通过计算发现:
Partition X 内,Tablet-2 和 Tablet-4 位于相同的 CN-1,而 Tablet-1 和 Tablet-3 位于相同的 CN-2,于是为 Partition X 构造了两个 Compaction Task(Task-1 与 Task-2),其中 Task-1 内包含 Tablet-2 和 Tablet-4,而 Task-2 内包含 Tablet-1 和 Tablet-3。
Partition Y 内,Tablet-5 和 Tablet-7 位于相同的 CN-1,而 Tablet-6 位于另外一个CN-2,于是为 Partition Y 也构造了两个 Compaction Task(Task-3 与 Task-4),其中 Task-3 内包含 Tablet-5 和 Tablet-7,而 Task-4 内包含 Tablet-6。
最终,每个 Task 被发往自己所属的 CN。
Compaction Executor 执行 Task
前面说过,FE 的 Compaction Scheduler 生成 Compaction Task,并发往 CN / BE 节点。CN / BE 节点上存在专有线程池来处理这些 Task,且线程池数量可配置(即将支持动态配置)。每个线程会从 Compaction Task 任务队列中获取下一个要被执行的 Task。
所谓 Compaction,其本质是将多个数据文件进行整理合并,删除其中的重复记录,并形成一个更大的数据文件。如下图所示:
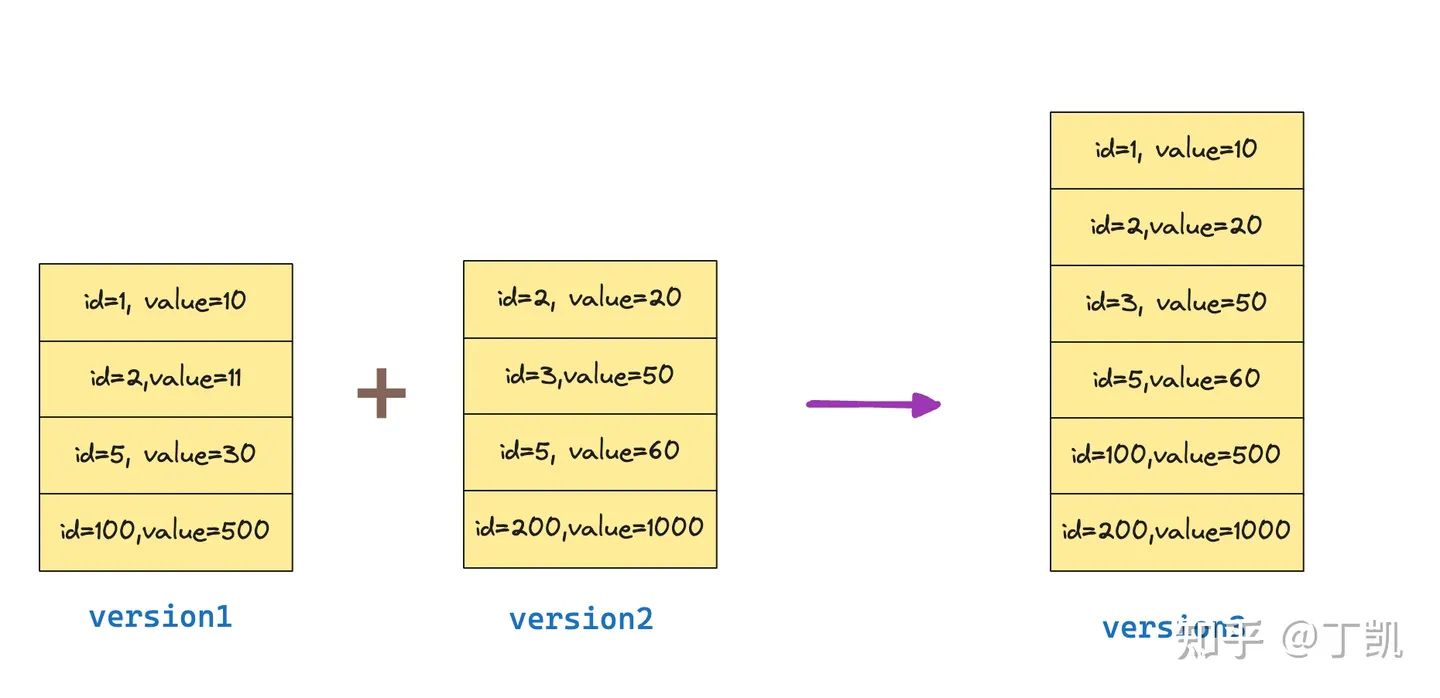
例如上图中,version 1 和 version 2 数据文件进行 Compaction 后,消除了 version 1 中的旧版本数据(id = 2, value = 11, id = 5, value = 30),最终生成了新的数据版本文件 version 3。
Compaction 后的数据清理
目前 StarRocks 存算分离表使用了数据多版本技术,整体上的存储结构如下图所示:
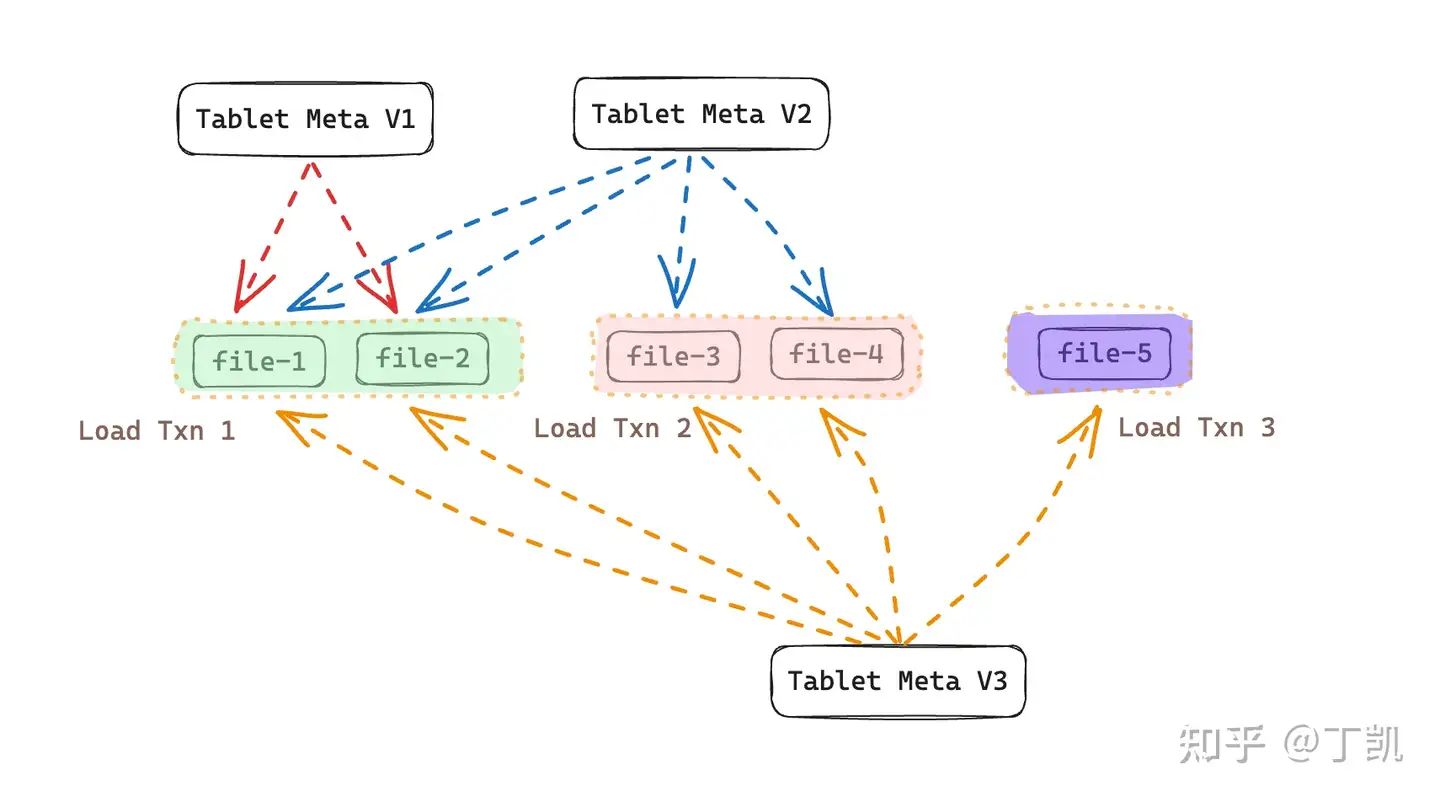
上图中共产生了三次数据导入事务,其中:
- Load Txn 1: 在事务数据写入阶段,生成了新数据文件 file 1 & file 2,且该事务提交后生成了 Tablet Meta V1,其中记录该版本可见的文件列表为 {file-1, file-2}
- Load Txn 2: 在事务数据写入阶段,生成了新数据文件 file 3 & file 4。在提交时,根据前一个版本(即 Tablet Meta V1)然后加上本次导入事务生成的新数据文件(file-3 & file-4),生成了新的 Tablet Meta V2,因此,该版本可见的文件列表为 {file-1, file-2, file-3, file-4}
- Load Txn 3: 在事务写入阶段,产生了新数据文件 file 5。该事务提交时,根据前一个版本(即 Tablet Meta V2)然后加上本次导入事务生成的新数据文件(file-5),产生了新的 Tablet Meta V3,因此,该版本的可见文件列表为 {file-1, file-2, file-3, file-4, file-5}
除了用户导入事务产生了新的数据版本,在存算分离表中,系统后台 Compaction 任务也会产生新数据版本。Compaction 的目的有二: 1). 将多个版本的小文件合并为大文件,减少查询时的随机 IO 次数,2). 消除重复数据记录,减少数据总量。
在存算分离表中,每次 Compaction 也会产生一个全新的版本。依然以上面为例,假如在上面 Txn 3 之后新的事务 Txn 4 为一次 Compaction 任务,并且将 file1 ~ file4 这4个文件合并成为 file-6,那么该事务提交时,生成的新版本 Tablet Meta V4 内记录的文件列表为 {file-5, file-6}。
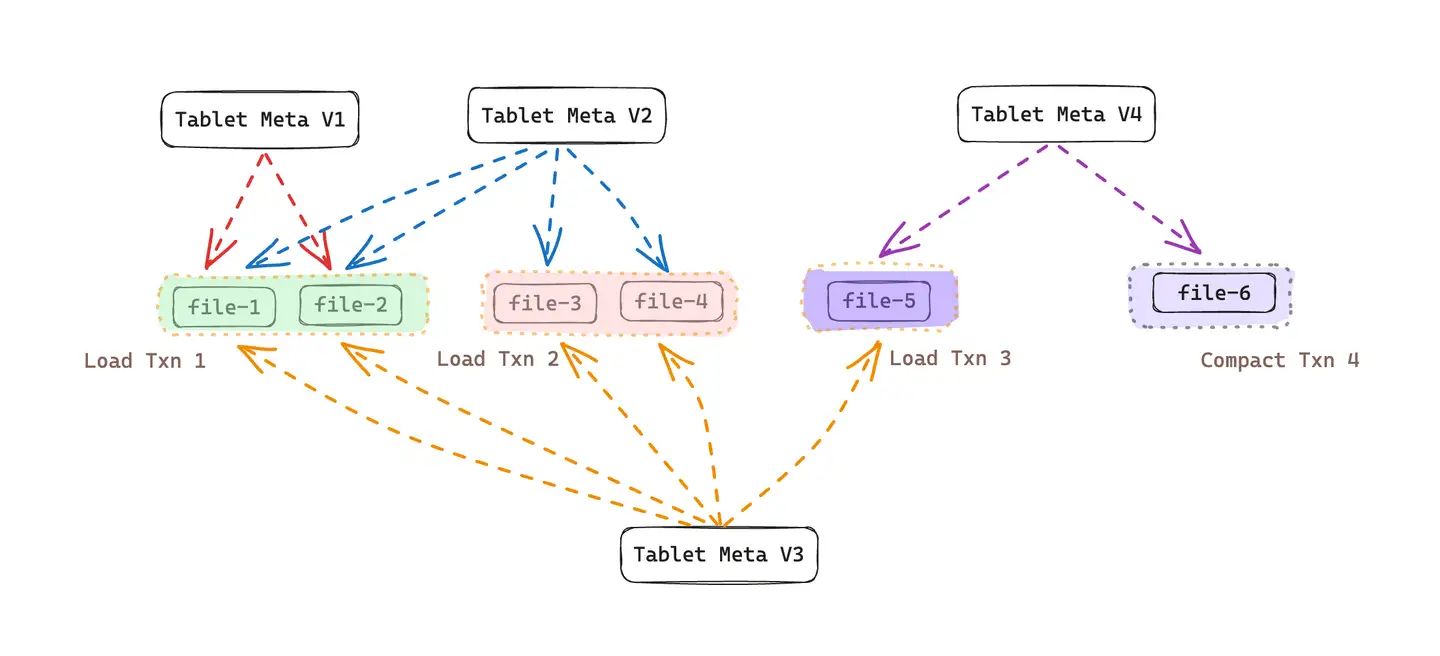
观察上例并思考可知,如果系统在运行过程中一直不会进行 Compaction。那么系统中的数据文永远也无法被删除。试想上例中我们可以将 Tablet Meta V1,Tablet Meta V2 文件删除,但我们无法删除 file-1、file-2、file-3 以及 file-4,因为这些文件依然被 Tablet Meta V3 所引用。
但有了数据合并(Compaction)后,情况就变得不一样了。上例中,由于发生了一次 Compaction(上图中的 Compact Txn 4),将 file-1、file-2、file-3、file-4 合并生成了新文件 file-6 并生成了新的 Tablet Meta V4,由于 file-1 至 file-4 中的内容已经在 file-6 中存在,因而,一旦版本 V1、V2、V3 不再被访问,file-1 至 file-4 便可以被安全删除。此时的数据版本情况如下图所示:
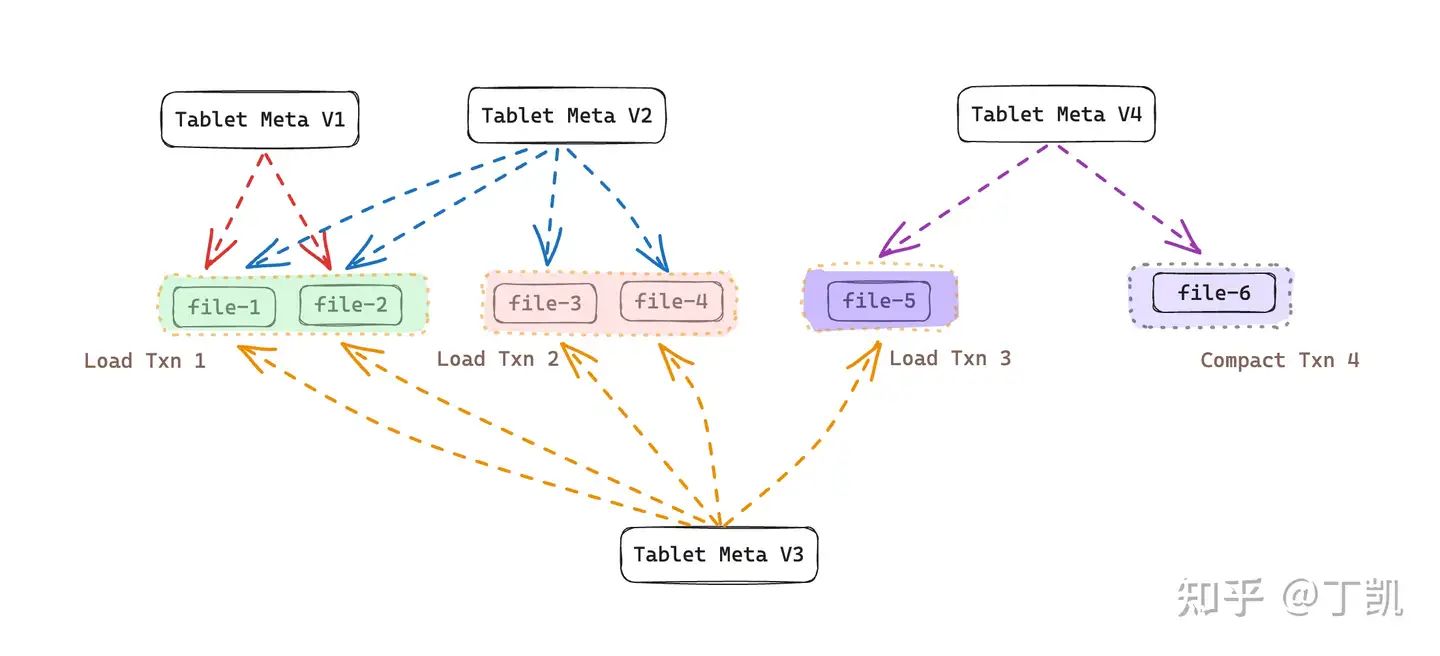
因此,综合上面的讨论,我们可以发现,只有在 Compaction 完成后原始的数据文件方可被删除。因而,判断数据文件能否安全删除的最直观的规则是:该数据文件不再被任何 Tablet Meta 所引用。