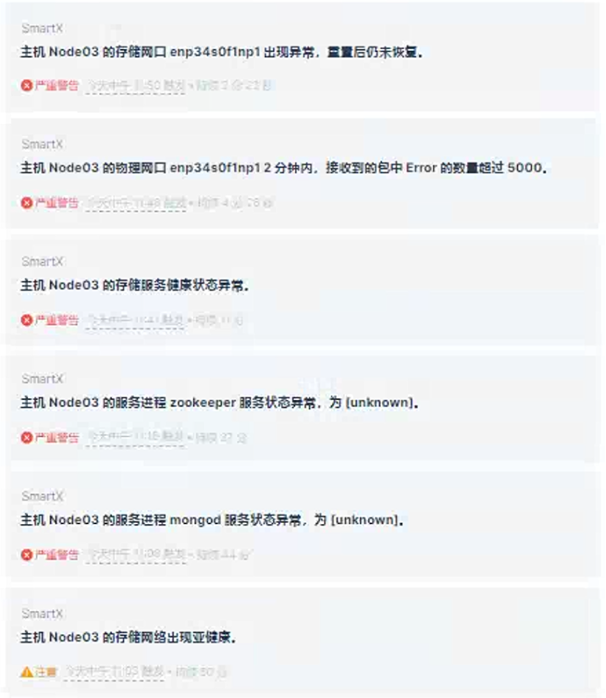
一、进度概述
1、机器学习常识1-11,以及相关代码复现
二、详情
1、不确定性
所谓不确定性, 是指我们在进行预测的时候, 不能够保证 100% 的准确。而机器学习,比的就是谁 “猜的更准”。
不确定性,可能由信息不足、信息模糊等原因产生。
对于过于复杂的确定性问题,会使用启发式算法之类求次优解。
2、数据类型
基本数据元素的类型:布尔型(Y/N)、枚举型、实型等。
常见的数据类型:
(1)结构化数据:指每个实例/instance (样本/sample)用同一组特征/feature (属性/attribute) 进行描述。
另一种说法是关系模型数据,而关系数据库,则指的是上学期所学的数据库中的关系模型。

(2)图像数据:本身可以用一个矩阵来表示(这也是为什么会用到 numpy 库等)。
(3)序列数据:由枚举型或实型组成。它与结构化数据的区别在于: 不可以混用枚举型与实型, 长度不是固定的。
(4)视频数据:是图像组成的序列数据。
(5)图数据:指数据用结点和边表示。如最典型的树状图,流程图等
3、分类、回顾、聚类
数据类型从输入数据的角度来进行讨论, 这里从输出数据, 或者目标的角度来讨论。
(1)分类是指将一个样本预测为给定类别之一.,也称为该样本打标签。根据标签数量可分为二分类问题和多分类问题
(2)回归是指为一个输出为实型值的预测。这与统计学中的回归分析是同一个概念。
(3)聚类是指根据样本的属性, 把给定的样本集合划分为若干个子集.
聚类与分类 (回归) 之间存在本质的区别, 它不进行新样本的预测。这是迫不得已的事情, 因为很多数据并没有人类先给的标签, 导致缺乏一个确定的目标, 机器只有根据自己理解来划分。
4、分类问题的训练与测试
这部分通过实例理解十分清晰,故直接参考原文:机器学习常识 4: 分类问题的训练与测试_机器学习 训练 测试-CSDN博客
不整理并不代表这一节不重要,相反,是这一节的逻辑太重要了,同时原文逻辑太好了,故直接使用。
5、性能评价指标
详细讲解参考原文:机器学习常识 5: 性能评价指标_机器学习性能评价-CSDN博客
这里整理一些个人理解以及注意事项:
(1)评价指标不是单一化的,没有绝对的第一,关键在于这个评价指标能否体现出你关心的问题的好坏。
(2)多方面的评价指标能使得研究更加丰富。
(3)对于回归问题,有明确的数学定义上的评价指标,如平均绝对误差,如均方根误差。对于聚类问题,则有内部和外部两种没有客观标准的指标。
6、kNN
对于 NN,从图的角度来理解会比较方便,参考以下文章,所运行出来的结果能十分清楚的表达其基本思想,求最小距离度量。
机器学习之KNN最邻近分类算法_knn分类-CSDN博客
结合上学期所学的线性回归分析,我们知道,极端值是很能影响这类算法的,所以归一化是个十分重要的步骤,同时要注意到,对原数据集的质量要保证。
7、决策树
概念很好理解,需要注意的是
(1)机器学习着重于如何从数据中构建决策树,而不是人为构造(这涉及问题相关专业知识)
(2)构建决策树的本质是不完全归纳,要根据数据量合理选择穷举法或者启发式方法。
(3)决策树越小越好(不要一开始就陷入信息增益的圈子中)
关于结合理论的代码复现,参考的是以下文章:【机器学习实战】3、决策树_为训练数据集建立决策树-CSDN博客
这里也有个实战训练,能够帮助自己更好的理解决策树:【机器学习】决策树(实战)_决策树算法jupyter实现-CSDN博客
8、kMeans
Means 是数据分布未知时最合适的聚类算法。
其基本思想是:最大化簇的内聚性 (即同一簇的点距离较近), 最小化簇间的耦合性 (即不同簇的点距离较远)。
从算法上感性理解,先通过确定随机的 k 各点作为中心点,分的多个簇(任意对象距离 k 各点中谁最近,则所属于谁),在通过各个中心点确定最终的中心点,最后判断收敛。
需要注意的是:
(1)与 NN 的共同点在于, 都使用某个距离度量。
(2)涉及迭代, 因此比 k kkNN 复杂。
(3)初始点的选择会影响最终的结果. 很可能只收敛到局部最优解。
(4)适合"球型"数据. 即每一簇从三维的角度来看都像一个球. 而并不适合于有较多离群点的数据. 所谓离群点, 可以认为是指离所有聚类中心的都挺远的数据点. 它会对 k kkMeans 的重心计算产生较大影响.
(5)并不是在所有的数据集上, 都能很快收敛. 我试过的数据中, 有 50 轮都未收敛的, 干脆就凑合了.
相关代码联系参考的是以下文章:K-means聚类算法原理及python实现_python kmeans-CSDN博客
9、 如何定义机器学习问题
多数机器学习问题可以按照如下约束满足问题进行定义:
- 输入
- 输出
- 优化目标
- 约束条件
10、线性回归
这一部分在已经学过的线性回归分析中讲的更细致,可以回顾相关课件,这里的总结更侧重于理解线性回归在机器学习中的意义。
- 是机器学习问题定义的一个典型案例.
- 线性模型及其变种在很多地方被采用. 也不是因为线性模型的拟合能力强 (其实它是最弱的), 而是因为它简单, 易于计算.
- 给出了一个典型的优化目标.
- 能从优化目标直接获得最优解, 对于绝大多数机器学习问题, 这点无法做到.
- 给出了一个典型的正则项
我们注意到,结合之前对 NN 和
Means 中的基本思想,其实其数学本质就是一个线性回归问题,机器学习的作用在于将过程全权交给效率,准确率更高的计算机来完成。
11、logistic 回归
广义线性回归同样在已经学过的线性回归分析中讲过,需要的话回顾相关课件,这里不做展开。
对于线性回归和广义线性回归,这两个概念及相关数学原理还是需要理解的,虽然现在大部分工作都有专门的软件可以帮你计算,如 R,但是只有理解原理,才能更好的运用。学的时间有点久了,建议多回去看看。
后记