训练模型使得它能够理解并预测人类偏好是一项比较复杂的任务。诸如 SFT (Supervised finetuning) 的传统的方法一般都需要耗费较大成本,因为这些算法需要对数据打上特定的标签。而偏好优化 (Preference Optimization) 作为一种替代选项,通常可以简化这一过程,并产出更准确的结果。通过对候选回答的对比和排序,而不是赋予固定的标签,偏好优化使得模型能更高效地捕捉人类偏好中的细微差别。
偏好优化已经在大语言模型中广泛使用了,但现在,它也可以用在视觉语言模型 (VLM) 上。得益于 TRL 的开发,现在我们可以 使用 TRL 对 VLM 进行直接偏好优化 (Direct Preference Optimization)。本文将会介绍使用 TRL 和 DPO 对视觉语言模型进行训练的全过程。
偏好数据集
进行偏好优化,首先我们需要有一个能体现用户偏好的数据集。在双项选择的设定下,相应的数据一般包含一个提示词 (Prompt) 和两个候选回答,两个回答中一个被记为选中 (chosen),另一个被记为淘汰 (rejected)。模型将要去学习着给出选中的回答,而不是被淘汰的那个。下图就是一个例子:

图片来自 openbmb/RLAIF-V-Dataset 数据集
❔ Question: How many families?
- ❌ Rejected: The image does not provide any information about families.
- ✅ Chosen: The image shows a Union Organization table setup with 18,000 families.
需要注意的是,尽管选中的回答也不是完全正确的 (回答 18000 个家庭还是不对,应该是 18000000),但它也好于那个被淘汰的回答。
本文将使用 openbmb/RLAIF-V-Dataset 作为示例数据集,它包含了超过 83000 条标注的数据。可以通过下面代码查看一下数据集:
>>> from datasets import load_dataset
>>> dataset = load_dataset("openbmb/RLAIF-V-Dataset", split="train[:1%]")
>>> sample = dataset[1]
>>> sample["image"].show()
>>> sample["question"]
'how many families?'
>>> sample["rejected"]
'The image does not provide any information about families.'
>>> sample["chosen"]
'The image shows a Union Organization table setup with 18,000 families.'
我们将要训练的 VLM 模型需要文本和图像同时作为输入,所以这里的第一步还是要对数据集格式进行改造。一条数据应该被结构化成能模拟人机对话的形式。用户提供一个提示语,其中包含一张图片和一个问题,然后模型需要能够给出一个回答。我们用以下代码实现格式转换:
from datasets import features
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("HuggingFaceM4/idefics2-8b", do_image_splitting=False)
def format(example):
# Prepare the input for the chat template
prompt = [
{
"role": "user",
"content": [{"type": "image"}, {"type": "text", "text": example["question"]}],
},
]
chosen = [
{
"role": "assistant",
"content": [{"type": "text", "text": example["chosen"]}],
},
]
rejected = [
{
"role": "assistant",
"content": [{"type": "text", "text": example["rejected"]}],
},
]
# Apply the chat template
prompt = processor.apply_chat_template(prompt, tokenize=False)
chosen = processor.apply_chat_template(chosen, tokenize=False)
rejected = processor.apply_chat_template(rejected, tokenize=False)
# Resize the image to ensure it fits within the maximum allowable
# size of the processor to prevent OOM errors.
max_size = processor.image_processor.size["longest_edge"]
example["image"].thumbnail((max_size, max_size))
return {"images": [example["image"]], "prompt": prompt, "chosen": chosen, "rejected": rejected}
# Apply the formatting function to the dataset,
# remove columns to end up with only "images", "prompt", "chosen", "rejected" columns
dataset = dataset.map(format, remove_columns=dataset.column_names)
# Make sure that the images are decoded, it prevents from storing bytes.
# More info here https://github.com/huggingface/blog/pull/2148#discussion_r1667400478
f = dataset.features
f["images"] = features.Sequence(features.Image(decode=True)) # to avoid bytes
dataset = dataset.cast(f)
完成了格式转换,我们来看看第一条数据:
>>> dataset[1]
{'images': [<PIL.JpegImagePlugin.JpegImageFile image mode=L size=980x812 at 0x154505570>],
'prompt': 'User:<image>how many families?<end_of_utterance>\n',
'rejected': 'Assistant: The image does not provide any information about families.<end_of_utterance>\n',
'chosen': 'Assistant: The image shows a Union Organization table setup with 18,000 families.<end_of_utterance>\n'}
OK!接下来准备好 GPU,训练马上开始。
训练
我们将使用 Idefics2-8b 作为我们的示例模型,但 TRL 里的 DPO 也是能用在像 Llava 1.5 和 PaliGemma 这样的模型上的 (可参考这篇文章: Finetuning Llava 1.5, PaliGemma and others)。不过训练之前,我们先检查一下我们的 GPU 显存是否够用:
训练需要多大的 GPU 显存?
一个 80GB VRAM 的 GPU 足够用来对 Idefics2-8b 进行 DPO 训练吗?我们可以先计算一下:
我们用 NNN 表示参数的数量,用 PPP 表示训练使用的精度。训练过程中,下列部分需要共同放入显存中:
- 要训练的模型: N×PN \times PN×P
- 用以防止模型产生偏离的参考模型: 和要训练的模型一样大,所以也是 N×PN \times PN×P
- 梯度: 我们对所有参数都进行训练,所以每个参数都有梯度: N×PN \times PN×P
- 优化器的状态量: 我们使用 AdamW,一个参数会保存两个状态量,所以需要: 2×N×P2 \times N \times P2×N×P
Idefics2-8b 有 80 亿 (8B) 参数,我们使用 float32 精度,每个参数占 4 个字节。所以总的显存需求是:
| 参数来源 | 计算公式 | 显存需求 |
|---|---|---|
| 要训练的模型 | 8×109×48 \times 10^9 \times 48×109×4 | 32 GB |
| 参考模型 | 8×109×48 \times 10^9 \times 48×109×4 | 32 GB |
| 梯度 | 8×109×48 \times 10^9 \times 48×109×4 | 32 GB |
| 优化器状态量 | 2×8×109×42 \times 8 \times 10^9 \times 42×8×109×4 | 64 GB |
| 合计 | 160 GB |
这远超我们前面说的 80GB 显存了!幸运的是,我们可以使用量化、LoRA 等技术来大幅度地减少显存需求,让训练可以进行。接下来我们将介绍这些技术。
量化
量化会降低模型权重和激活值的精度,但也同时显著减少内存需求。将精度从 float32 改为 bfloat16 ,会让每个参数需要的比特数从 4 比特减少到 2 比特。这一策略不仅能减少内存使用,还会显著加速训练,确保以最小代价保证足够高的性能。具体做法如下:
import torch
from transformers import AutoModelForVision2Seq
model = AutoModelForVision2Seq.from_pretrained("HuggingFaceM4/idefics2-8b", torch_dtype=torch.bfloat16)
通过如下 bf16=True 的设置, bfloat16 也可以被用在优化器上:
from transformers import TrainingArguments
training_args = TrainingArguments(..., bf16=True)
LoRA
LoRA 对参数矩阵进行低秩分解; 在训练时,固定住原参数矩阵,仅训练分解出的两个矩阵。是一种大规模减少 LLM 训练参数的方法。LoRA 已被集成在了 PEFT 库里,使用非常方便:
from transformers import AutoModelForVision2Seq
+ from peft import get_peft_model, LoraConfig
model = AutoModelForVision2Seq.from_pretrained("HuggingFaceM4/idefics2-8b")
+ peft_config = LoraConfig(target_modules="all-linear")
+ model = get_peft_model(model, peft_config)
PEFT 像是给原模型进行了一次封装 (代码中称为 adapter )。训练时,实际上是这个 adapter 在被训练,而原有的模型保持不动。我们现在算算 LoRA 帮我们减少了多少要训练的参数:
>>> model.print_trainable_parameters()
trainable params: 55,348,736 || all params: 8,458,116,848 || trainable%: 0.6543860411799315
它帮我们把要训练的参数从八十亿降到了五千五百万!差距真大!这将显著减少显存需求。
使用 bfloat16 和 LoRA 后的显存需求
现在我们来算算新的显存需求:
| 参数来源 | 计算公式 | 显存需求 |
|---|---|---|
| 要训练的模型 | 8G×28 \mathrm{G} \times 28G×2 | 16 GB |
| 参考模型 | 8G×28 \mathrm{G} \times 28G×2 | 16 GB |
| 梯度 | 55M×255 \mathrm{M} \times 255M×2 | 0.1 GB |
| 优化器状态量 | 2×55M×22 \times 55 \mathrm{M} \times 22×55M×2 | 0.2 GB |
| 合计 | 32.3 GB |
现在我们仅需 32GB 的显存就可以训练我们的 Idefics2-8b 模型了。这合理多了,用 80GB 显存的 GPU 就可以训练了。
训练时 batch size 怎么设定?
上述关于显存占用的计算还不算准确,因为实际训练时,激活值也需要占用显存。激活值是神经网络各层的输出。作为中间产物,它们的显存占用量取决于模型结构和训练时的 batch size。准确计算这些显存需求还是很困难的,我们一般依赖实验观察。
若想找到一个合适的 batch size ( per_device_train_batch_size ),你可以先随便选取一个你认为合适的数值 (比如 64) 然后试着开始训练。当然这大多数情况下会爆显存 (OOM)。如果这样,你可以减半 batch size,同时将 gradient_accumulation_steps 翻倍,以获得和原先 batch size 设定相同的效果。反复重复这一过程,最终当 OOM 不再出现时,你就可以训练了。我们的实验参数是: per_device_train_batch_size 设为 2, gradient_accumulation_steps 设为 32。
你还可以使用 gradient_checkpointing 来减少激活值所需的内存。这一技术在计算梯度时,会重新计算一遍前向过程,而不是在前向过程中保存用于计算梯度的中间结果。需要使用时,设置 gradient_checkpointing=True 即可。
完整训练代码
一切就绪,我们可以开始训练了。下面是我们的完整训练代码。除了上面提到的部分外,我们还设置了 dataset_num_proc 和 dataloader_num_workers 等参数,用于加速数据预处理。
# dpo_idefics2-8b.py
from datasets import features, load_dataset
from transformers import AutoModelForVision2Seq, AutoProcessor
import torch
from trl import DPOConfig, DPOTrainer
from peft import LoraConfig
def main():
# Load the model and processor
model = AutoModelForVision2Seq.from_pretrained("HuggingFaceM4/idefics2-8b", torch_dtype=torch.bfloat16)
processor = AutoProcessor.from_pretrained("HuggingFaceM4/idefics2-8b", do_image_splitting=False)
# Load the dataset
dataset = load_dataset("openbmb/RLAIF-V-Dataset", split="train")
def format(example):
# Prepare the input for the chat template
prompt = [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": example["question"]}]}]
chosen = [{"role": "assistant", "content": [{"type": "text", "text": example["chosen"]}]}]
rejected = [{"role": "assistant", "content": [{"type": "text", "text": example["rejected"]}]}]
# Apply the chat template
prompt = processor.apply_chat_template(prompt, tokenize=False)
chosen = processor.apply_chat_template(chosen, tokenize=False)
rejected = processor.apply_chat_template(rejected, tokenize=False)
# Resize the image to ensure it fits within the maximum allowable
# size of the processor to prevent OOM errors.
max_size = processor.image_processor.size["longest_edge"]// 2
example["image"].thumbnail((max_size, max_size))
return {"images": [example["image"]], "prompt": prompt, "chosen": chosen, "rejected": rejected}
# Apply the formatting function to the dataset
dataset = dataset.map(format, remove_columns=dataset.column_names, num_proc=32)
# Make sure that the images are decoded, it prevents from storing bytes.
# More info here https://github.com/huggingface/blog/pull/2148#discussion_r1667400478
f = dataset.features
f["images"] = features.Sequence(features.Image(decode=True))
dataset = dataset.cast(f)
# Train the model
training_args = DPOConfig(
output_dir="idefics2-8b-dpo",
bf16=True,
gradient_checkpointing=True,
per_device_train_batch_size=2,
gradient_accumulation_steps=32,
num_train_epochs=1,
dataset_num_proc=32, # tokenization will use 32 processes
dataloader_num_workers=32, # data loading will use 32 workers
logging_steps=10,
)
trainer = DPOTrainer(
model,
ref_model=None, # not needed when using peft
args=training_args,
train_dataset=dataset,
tokenizer=processor,
peft_config=LoraConfig(target_modules="all-linear"),
)
trainer.train()
if __name__ == "__main__":
main()
启动脚本开始训练,接下来就等待结果吧 🚀
accelerate launch dpo_idefics2-8b.py
结果
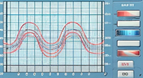
训练需要几小时的时间。当训练完成后,我们可以看看训练相关指标的变化曲线:

In DPO, we focus on several metrics to assess the quality of the training:
在 DPO 中,为了评估训练,我们关注这几个指标:
- 精度 (Accuracy): 在训练样本中,模型更愿意输出被选中的回答而不是被淘汰的回答,这个比率有多少。我们可以看到随着训练,精度在提升,这是个好的信号。
- 奖励 (Rewards): 这一指标与一个回答 (选中或淘汰) 被选中的概率呈正相关,读者可以参考 DPO 论文 , 第 5 部分。我们希望被选中的回答对应的奖励高于被淘汰的回答。我们可以通过两者奖励的差值 ( reward margin ) 来看: 图中这一差值逐渐变大, 这也是个好的信号。
评测
推理代码
训练完成后,我们接下来就要在一些样本上评测一下了。这会让我们了解模型学习得怎么样、预测有效性如何。下面的代码可以用来在测试样本上进行评测:
from transformers import AutoModelForVision2Seq, AutoProcessor
from PIL import Image
model = AutoModelForVision2Seq.from_pretrained("HuggingFaceM4/idefics2-8b").to("cuda")
processor = AutoProcessor.from_pretrained("HuggingFaceM4/idefics2-8b", do_image_splitting=False)
model.load_adapter("HuggingFaceH4/idefics2-8b-dpo-rlaif-v-v0.3") # <-- Load the adapter we've just trained
# Process
user_message = ...
image_path = ...
data = [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": user_message}]}]
prompts = processor.apply_chat_template(data, add_generation_prompt=True) # add_generation_prompt=True to end the prompt with "ASSISTANT:"
images = [Image.open(image_path)]
inputs = processor(prompts, images, return_tensors="pt")
inputs = {k: v.to("cuda") for k, v in inputs.items()}
# Generate
generated_ids = model.generate(**inputs, max_new_tokens=500)
response_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response_text)
前面提到的 openbmb/RLAIF-V-Dataset 这个数据集是用来减少大模型幻觉的。但真实训练效果如何呢?我们可以使用 AMBER benchmark 这个评测基准,该数据集专门被用来评估 VLM 的幻觉情况。我们列出 Idefics2 和 Idefics2+DPO 的结果,并和其它模型对比。
| Accuracy | F1 | |
|---|---|---|
| GPT-4o | 88.8 | 91.6 |
| Idefics2+DPO | 85.9 | 89.4 |
| Idefics2 | 85.8 | 89.1 |
| GPT-4v | 83.4 | 87.4 |
| MiniGemini | 82.6 | 87.6 |
| LLaVA-NeXT | 81.4 | 85.4 |
| QWEN-VL | 81.9 | 86.4 |
| LURE | 73.5 | 77.7 |
| OPERA | 75.2 | 78.3 |
| Less-is-more | 72.4 | 75.8 |
| VCD | 71.8 | 74.9 |
总的来看,有点作用!幻觉似乎减少了点。训练看来还是成功的。
下面我们也列出一些可视化结果出来:
| Image | Question | Idefics2 | Idefics2+DPO |
|---|---|---|---|
| Are there two ships in this image? | Yes | No | |
 | |||
| Is the ground uneven in this image? | No | Yes | |
 | |||
| Is there one shovel in this image? | Yes | No | |
 |
你也可以自己找些例子来测试一下这个模型!

微调 Llava 1.5 和 PaliGemma 等模型
截至本文完稿时,TRL 的 DPO 实现已支持 Idefics2、Llava 1.5 和 PaliGemma,同时 TRL 也在努力支持更多的模型。最简单的调用方法还是使用 TRL 提供的 示例脚本。例如,如果你想微调 PaliGemma,你可以这样:
accelerate launch examples/scripts/dpo_visual.py \
--dataset_name HuggingFaceH4/rlaif-v_formatted \
--model_name_or_path google/paligemma-3b-pt-224 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 32 \
--dataset_num_proc 32 \
--output_dir dpo_paligemma_rlaif-v \
--bf16 \
--torch_dtype bfloat16 \
--gradient_checkpointing \
--use_peft \
--lora_target_modules=all-linear
更多关于 PaliGemma 微调的信息可以在 smol-vision 这个项目里看到。
🚀🚀 好了!你现在已经会使用 DPO 微调 VLM 模型了!
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。