标题党一下,Python 程序员成千上万,当然有很多人学得会。这里说的“你”,是指职场中的非专业人员。
职场人员一般会用 Excel 处理数据,但也会有很多无助的情况,比如复杂计算、重复计算、自动处理等,再遇上个死机没保存,也常常能把人整得崩溃。如果学会了程序语言,这些问题就都不是事了。那么,该学什么呢?
无数培训机构和网上资料都会告诉我们:Python!
Python 代码看起来很简单,只要几行就能解决许多麻烦的 Excel 问题,看起来真不错。
但真是如此吗?作为非专业人员,真能用 Python 来协助我们工作吗?
嘿嘿,只是看上去很美!
事实上,Python 并不合适职场人员,因为它太难了,作为职场非专业人员的你就学不会,甚至,Python 的难度可能会大到让你连 Python 为什么会难到学不会的道理都理解不了的地步。
日常工作中碰到的数据大都是 Excel 表格那种,称为结构化数据。程序语言要想用来协助日常工作,就需要有较强的结构化数据处理功能。
Python 用来处理结构化数据需要有一个叫 Pandas 的开源包,这东西不是 Python 的固有组件,你得自己再下载安装,过程就不太简单了,要配一堆让初学者晕死的东西。当然还可以借助第三方程序,但这些第三方程序本身的安装又是个问题,启动起来又有一堆工程环境配置让人不知所措(人家设计出来是做大型应用的)。还有调试,你不可能一下子就把代码写对,Python 开发环境的调试功能本来就不太好,Pandas 又不是 Python 的原生内容,调试就更费劲。
这些麻烦还是题外的,也能克服一下。关键问题在于,Pandas 就不是为结构化数据设计的,会有许多不能如你所愿而且非常费解的东西.
我们通过例子来看一下,比如这样的表格:
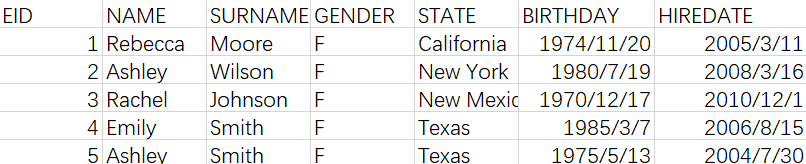
除第一行外的每行数据称为一条记录,对应了一件事、一个人、一张订单……,第一行是标题,说明记录由哪些属性构成,这些记录都有相同的属性,整个表就是这样一些记录的集合。
Pandas 中主要用一个叫 DataFrame 的东西来处理这类表格数据,上面的表格读入 DataFrame 后是这样的:
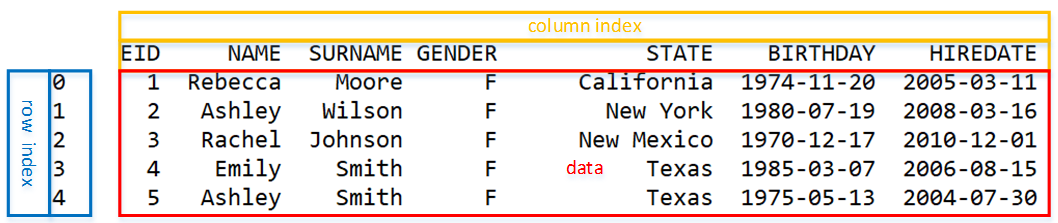
看起来和 Excel 差不多,只是行号是从 0 开始的。
先试试汇总各部门的人数:
import pandas as pd
data = pd.read_csv('Employee.csv')
group = data.groupby("DEPT")
dept_num = group.count()
print(dept_num)
import pandas as pd data = pd.read_csv('Employee.csv') group = data.groupby("DEPT") dept_num = group.count() print(dept_num)
分组后再计数,这是常规思路,但结果有点尴尬:
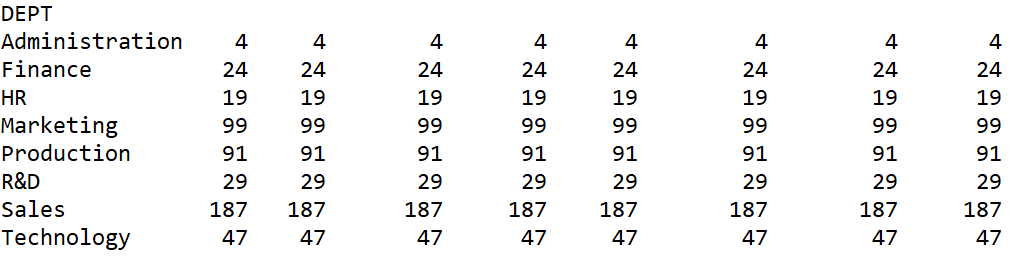
部门人数,也就是每个分组的成员数量,只要有一列就行了,为什么出来这么多列,它像是对每一列都做了同样的动作,好奇怪。
这是因为 DataFrame 本质上是个矩阵,而不是记录的集合,Python 也没有记录这样的概念。count 作用在矩阵上,就会对每一列计数,有点意想不到吧。
简单的过滤运算,比如取出研发部员工,我们想像中的结果应该是人员表的子集,但实际上是整个人员表(矩阵)和一些被选择的行位置(称为行索引),可以理解为子矩阵。这时候输出结果可能也看不出啥,但想进一步操作,比如给研发部员工涨 5% 工资,你就会再次发现“意想不到”了。
用 DataFrame 处理结构化数据时,要绕到矩阵的思路上去,这会非常挑战初学者的理解力。
怎样才能正确输出部门人数呢?要用 size 函数,它才是用来查看各组的成员数。
import pandas as pd
data = pd.read_csv('Employee.csv')
group = data.groupby("DEPT")
dept_num = group.size()
print(dept_num)
这个结果就正常了:
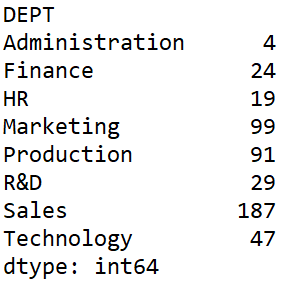
不过,这个结果不再是二维的 DataFrame 了,而是个一维的 Series,它不能再继续应用 DataFrame 的方法了,又是“意想不到”。
明明分组汇总结果也是个有行有列的结构化数据表,继续用 DataFrame 不好吗?为什么要再搞一种东西?让人费解。
Python 并没有止步于这两个。比如,分组运算的本质就是把大集合拆成小集合,结果应该是个集合的集合。那我们看看 DataFrame 分组后是什么样子呢?把上面代码中分组结果打印出来看。
import pandas as pd
data = pd.read_csv('Employee.csv')
group = data.groupby("DEPT")
print(group)
结果出来:
"pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001ADBC9CE0F0"
这是个啥东东?这是集合的集合吗?
上网搜一下,原来这叫做可迭代对象,它的每个成员都是以 DataFrame+ 分组索引构成的,也有方法再拆开看。这个被称为什么对象的东西,本质上是大矩阵的子矩阵构成的集合,勉强也能算是集合的集合了,但它并不能像普通集合那样直接用序号取某个成员(比如 group[0])。
估计到这里不少人已经晕了,完全搞不清我都在胡说八道些什么。嗯,这就对了,这才是职场人员的正常状态。
Python 有 N 多“对象”来描述同样数据,各有各的适应场景和运算规则,如 DataFrame 可以用 query 函数过滤,而 Series 不可以,分组后这个对象更是完全不同。这些东西之间转换还很“丝滑”,稍不留神就变成另一种不认识的东西。结果,编程基本靠搜,即使跑对了也还是搞不懂记不住,下次还得搜。
再进一步,将各部门员工按照入职时间从早到晚进行排序。这只要分组后将子集按照入职时间排序即可,写出来是这样的:
import pandas as pd
employee = pd.read_csv("Employee.csv")
employee['HIREDATE']=pd.to_datetime(employee['HIREDATE'])
dept_g = employee.groupby('DEPT',as_index=False)
dept_list = []
for index,group in dept_g:
group = group.sort_values('HIREDATE')
dept_list.append(group)
employee_new = pd.concat(dept_list,ignore_index=True)
print(employee_new)
看起来有点啰嗦,要写个 for 循环一点点做,这似乎体现不出集合化数据处理的优势了,毕竟结构化数据都是批量集合式的,都写这么啰嗦, 那么和 VBA 什么的区别也不大了。
嗯,其实 Python 也有不用 for 循环的写法:
import pandas as pd
employee = pd.read_csv("Employee.csv")
employee['HIREDATE']=pd.to_datetime(employee['HIREDATE'])
employee_new = employee.groupby('DEPT',as_index=False).apply(lambda x:x.sort_values('HIREDATE')).reset_index(drop=True)
print(employee_new)
但是,这里最关键的倒数第二句,有个 apply 和 lambda 的那句,能看明白吗?
这是所谓的“函数语言”概念,写法复杂度和理解难度都超出了大多数非专业人员的能力范畴,具体啥意思,这里也懒得解释了,自己去搜搜看能不能搞懂。
简单总结一下:
DataFrame 本质是矩阵,不是记录的集合,编程要按矩阵的方法来思考,经常会有点绕,结果也会有“意想不到”。
更麻烦的是,Python 有太多相似的数据类型,比如 Series,DataFrame,分组对象都可以表示某种集合,但各有各的规则,计算方法更是难以捉摸。想理解这些原理后正确运用,其难度和繁度都不是非专业人员能够和应该做的。
还有 apply+lambda 这种东西,不用呢,批量数据处理的代码太啰嗦,想用却很难搞懂。
事实上,Python 是个段位很高的东西。对于非专业人员来讲,Python 的强大和方便,只存在于培训班。你很少见到周围有职场人员在用 Python 倒腾 Excel,Python 真正的使用者都是重度专业人员,主要是搞人工智能的那群人。
面向非专业人员,esProc SPL 就简单多了。
SPL 只有一种集合,结构化数据表就是记录的集合,分组结果就是集合的集合。这些集合上可以执行同样一套运算。
来看刚才的例子,分组汇总简单 count 就可以得到正常的结果
| A | |
| 1 | =file("Employee.csv").import@tc() |
| 2 | =A1.groups(DEPT;count(~):cnt) |
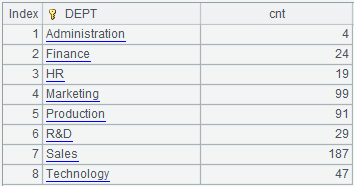
分组的结果就是集合的集合,很好理解:
| A | |
| 1 | =file("Employee.csv").import@tc() |
| 2 | =A1.group(DEPT) |
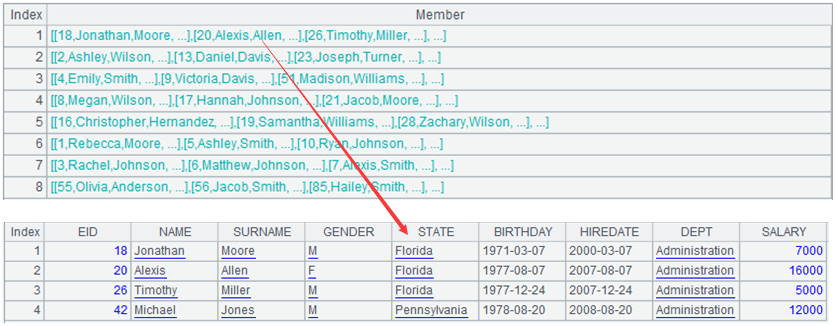
分组子集再排序不用难懂的 lambda 也依然简洁,SPL 把函数语言已经化于无形
| A | |
| 1 | =file("Employee.csv").import@tc() |
| 2 | =A1.group(DEPT) |
| 3 | =A2.conj(~.sort(HIREDATE)) |
esProc SPL 才是非专业人员真正有可能学得会用得起来的程序语言。
SPL开源地址








![[星瞳科技]OpenMV是否属于单片机?](https://img-blog.csdnimg.cn/img_convert/960856f3b2d564ef0608e5e12317b303.png)




![[PHP]-Laravel中Group By引发的问题思考](https://i-blog.csdnimg.cn/direct/d8107743337647cc921a47e61a59f07d.jpeg#pic_center)


![ansible[自动配置]](https://i-blog.csdnimg.cn/direct/78092fd4c82f453da48e01622582da09.png)
