正如海洋中的巨浪需要广阔的海域来形成,大模型的算力需求也要求我们拓宽对现有计算资源的认识。接下来的内容将引导我们穿越技术的波涛,探索在人工智能快速发展的今天,算力如何成为推动进步的关键力量。我们将分析FP16与FP32精度选择的权衡,评估算力需求的增长趋势,审视算力供给的现状与挑战,并最终展望算力技术的创新与突破。这不仅是对技术层面的深入研究,也是对人工智能未来发展的一次深思熟虑。

1. 算力精度概念解析
1.1 浮点运算中的精度概念
浮点运算是计算机处理带有小数的数值计算,其精度概念直接关联到数值的表示范围与准确度。在计算机中,浮点数遵循IEEE 754标准,通过特定的位数来表示数值的精度。精度的高低决定了计算机处理数值时的准确度和可靠性。
1.2 FP32与FP16精度比较
FP32和FP16是两种不同的浮点数表示精度,它们在数值计算中扮演着不同角色。FP32提供32位的精度,包括1位符号位、8位指数位和23位尾数位,而FP16则提供16位的精度,包括1位符号位、5位指数位和10位尾数位。
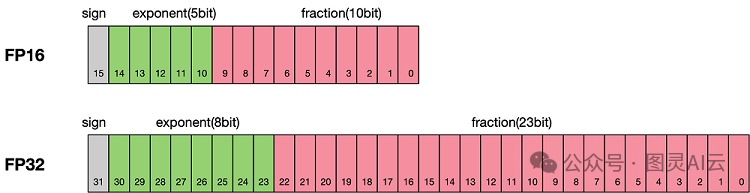

主要比较如下:
-
精度差异:FP32相较于FP16拥有更高的精度,能够表示更细微的数值变化,适用于需要高精度计算的场景。FP16虽然精度较低,但在深度学习等场景中,其精度损失是可以接受的,同时它能够提供更快的计算速度和更低的内存使用量。
-
应用场景:FP32常用于科学计算和工程模拟等对精度要求极高的领域,而FP16则广泛应用于深度学习训练和推理,尤其是在对内存和计算速度有严格要求的场景。
-
性能对比:在相同的硬件条件下,使用FP16进行计算可以显著提高性能,因为它减少了数据传输和存储的需求。然而,FP16的数值范围较窄,可能会导致在某些极端情况下的数值溢出或下溢问题。
2. 大模型中的算力应用
2.1 FP32在大模型中的应用
在大型语言模型的训练中,FP32精度因其高精度特点而被广泛使用。这可以确保模型在训练过程中能够捕捉到细微的数据变化,从而提高模型的准确性和泛化能力。FP32的应用也有助于保持模型训练的稳定性,减少由于数值精度问题导致的训练失败风险。
2.2 FP16在大模型中的应用
尽管FP16的精度低于FP32,但其在大模型训练中的应用正变得越来越普遍。FP16的使用可以显著减少模型训练所需的内存和存储需求,同时加快计算速度。在现代GPU和TPU的支持下,FP16的计算性能得到了极大的提升,使得在保持合理精度损失的前提下,大幅缩短了模型训练的时间。
2.3 混合精度训练
为了结合FP32和FP16的优点,混合精度训练技术被提出。在这种技术中,模型的某些部分使用FP16进行计算以提高性能,而关键部分则使用FP32以保持精度。通过在不同阶段使用不同精度的数据来平衡计算效率和模型精度。
-
技术实现:在模型的前向传播中使用FP16来减少内存占用和加速计算,在反向传播中使用FP32来保证梯度的精度。
-
性能提升:混合精度训练可以在保持模型性能的同时,提高训练速度和减少内存使用。
-
实际效果:研究表明,使用混合精度训练的大模型在各项性能指标上与使用纯FP32训练的模型相当,但训练速度有显著提升。
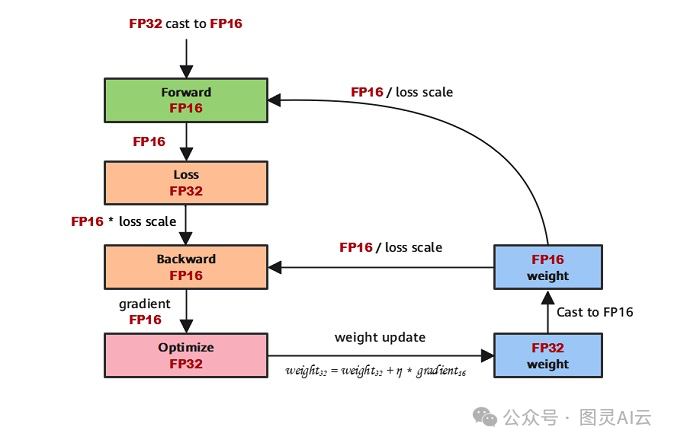
上图描述了混合精度训练的流程,主要使用了32位浮点数(FP32)和16位浮点数(FP16)的数据类型。混合精度训练通过使用较低精度的数据类型来加速计算,同时保持模型的精度。下面是该流程的详细说明:
1、参数以FP32存储;
2、正向计算过程中,遇到FP16算子,需要把算子输入和参数从FP32 cast成FP16进行计算;
3、将Loss层设置为FP32进行计算;
4、反向计算过程中,首先乘以Loss Scale值,避免反向梯度过小而产生下溢;
5、FP16参数参与梯度计算,其结果将被cast回FP32;
6、除以Loss scale值,还原被放大的梯度;
7、判断梯度是否存在溢出,如果溢出则跳过更新,否则优化器以FP32对原始参数进行更新。
整个流程的目的是利用FP16的计算效率和FP32的精度,通过损失缩放来平衡两者,实现快速且准确的模型训练。
2.4 量化技术
除了混合精度训练,量化技术也是提高大模型训练效率的一种方法。量化通过将浮点数转换为整数,进一步减少了模型的存储和计算需求。虽然这会引入额外的精度损失,但在许多情况下,模型的最终性能并未受到显著影响。量化技术尤其适用于部署到资源受限的设备上。
2. 大模型对算力的需求
2.1 大模型规模与算力的关系
大模型因其庞大的参数量对算力有着极高的需求。例如,一个千亿参数级别的模型在训练时可能需要数十甚至上百个GPU的并行计算能力。这种规模的模型对算力的需求不仅体现在浮点运算的次数上,还体现在数据传输和存储上。随着模型规模的增加,所需的算力呈现出非线性增长的趋势。
-
模型规模增长:模型参数量每增加10倍,所需的算力可能增加100倍以上,这主要是由于模型训练中的并行化和通信开销。
-
算力需求:大型模型通常需要PFLOPs(每秒千万亿次浮点运算)级别的算力,这通常只有通过大规模GPU集群才能实现。
2.2 FP16在大模型训练中的应用
FP16,即16位浮点数,由于其较低的内存占用和较高的计算吞吐量,在大模型训练中得到了广泛应用。
-
内存效率:FP16相比于FP32(32位浮点数),每个参数的内存占用减半,这对于参数量巨大的模型来说,可以显著减少内存占用,使得更大的模型能够在有限的硬件资源上进行训练。
-
计算速度:在支持FP16的硬件上,如NVIDIA的V100或A100 GPU,使用FP16进行计算可以提供更高的吞吐量,因为一次可以处理更多的数据。
-
混合精度训练:为了平衡FP16带来的数值稳定性问题,通常会采用混合精度训练,即在模型的某些部分使用FP16,而在需要高精度的部分使用FP32,以此来提高训练效率同时保证模型质量。
-
数值稳定性:尽管FP16提供了内存和速度上的优势,但其较低的精度可能会导致数值稳定性问题,特别是在模型的深层和优化器的更新过程中。
2.3 FP32在大模型训练中的必要性
尽管FP16在大模型训练中具有明显的优势,但FP32仍然因其高精度而在某些情况下不可或缺。
-
精度保证:FP32提供更高的数值精度,这对于避免训练过程中的数值不稳定和梯度下溢/溢出至关重要。
-
模型稳定性:在模型的某些关键部分,如优化器的状态更新,使用FP32可以保证模型训练的稳定性和收敛性。
-
硬件支持:虽然FP32的计算速度可能不如FP16,但几乎所有现代计算硬件都原生支持FP32,这使得FP32在兼容性和普及性上具有优势。
在实际应用中,FP16和FP32的使用往往需要根据模型的规模、训练的稳定性要求以及硬件的可用性来综合考虑。随着硬件技术的发展,未来可能会有新的计算精度格式出现,以更好地满足大模型训练的需求。
3. FP16与FP32的性能对比
3.1 FP16的性能优势与局限性
在大模型训练和推理中,FP16(16位浮点数)相较于FP32(32位浮点数)具有显著的性能优势,同时也存在一些局限性。
-
性能优势:
-
计算速度:FP16由于数据宽度减半,可以在现代GPU上实现更高的吞吐量,其计算速度通常是FP32的两倍。
-
内存使用量:FP16需要的内存带宽减半,有效降低了内存使用量,对于资源受限的设备尤为重要。
-
能效比:FP16在执行计算时,由于数据量减少,通常具有更高的能效比。
-
-
局限性:
-
数值表示范围:FP16的数值范围较FP32小,可能导致在表示非常大或非常小的数值时出现溢出或下溢。
-
精度损失:由于表示精度降低,FP16在某些情况下可能会引入累积的舍入误差,影响模型的最终性能。
-
数值稳定性问题:在深度学习训练中,FP16可能会遇到梯度溢出或不足的问题,导致优化器计算不精确。
-
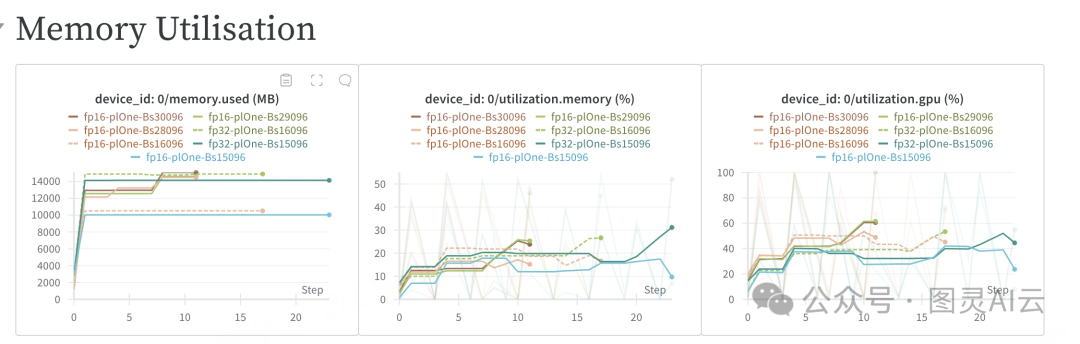
上图是在不同精度FP16和FP32设置下训练卷积神经网络(CNN)时GPU内存使用情况的图表。图像中列出了不同的批量大小,例如Bs16096、Bs15096等,每个批次处理的样本数量不一样。根据图像中的数据,我们可以看到FP16精度设置在训练CNN时通常比FP32使用更少的内存,这有助于在资源有限的情况下进行更大规模的训练。
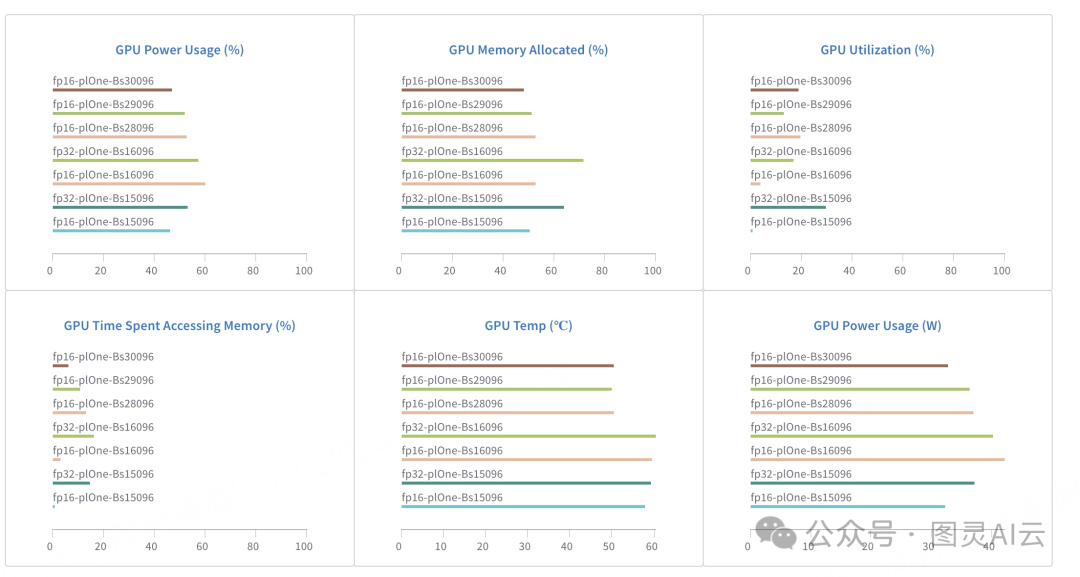
从上图中,我们可以看到几个关键的GPU性能指标,这些指标是在不同精度设置(FP16和FP32)和不同批量大小(Batch Size,Bs)下训练时的测量结果。具体指标包括:
-
GPU Power Usage (%): 表示GPU在运行时的功耗百分比。
-
GPU Memory Allocated (%): 表示GPU分配的内存百分比。
-
GPU Utilization (%): 表示GPU的利用率。
-
GPU Time Spent Accessing Memory (%): GPU花费在访问内存上的时间百分比。
-
GPU Temp (°C): GPU的温度。
图像中列出了多个配置,每个配置重复三次。配置包括FP16和FP32精度以及不同的批量大小,如Bs30096、Bs29096、Bs28096、Bs16096和Bs15096。
从图像中的数据,我们可以得出以下结论:
-
在FP16设置下,GPU的功耗百分比、内存分配百分比和利用率普遍较低,这表明FP16在训练中更为节能,并且对内存的需求较低。
-
FP32设置下,GPU的功耗百分比和利用率较高,这意味着FP32在训练中需要更多的能量和内存资源。
-
对于GPU Time Spent Accessing Memory,FP16的值普遍较低,这意味着FP16在内存访问上更为高效。
3.2 FP32在确保模型稳定性中的作用
尽管FP16提供了性能上的优化,但FP32在确保模型稳定性方面发挥着关键作用。
-
数值精度:FP32提供更高的数值精度,有助于减少训练过程中的舍入误差,特别是在涉及复杂数学运算的深度学习模型中。
-
稳定性:FP32由于具有更大的数值范围和精度,可以更好地处理深度学习中的梯度更新,减少数值稳定性问题。
-
兼容性:某些深度学习框架和库可能对FP32有更好的支持,使用FP32可以避免一些FP16特有的兼容性问题。
-
混合精度训练:在混合精度训练中,FP32通常用于存储模型参数,而FP16用于计算,这样可以在保持模型精度的同时提高训练速度。
-
超参数调整:在FP32训练中,可以通过调整学习率和其他超参数来更好地控制模型训练的稳定性,例如使用较小的学习率来减少梯度的幅度,降低数值不稳定性。
4. 混合精度训练的实践
4.1 混合精度训练的技术实现
混合精度训练技术通过结合FP16和FP32的数据类型,实现了深度学习模型训练的加速与内存使用减少。在具体实现上,主要涉及以下几个方面:
-
精度转换:在模型的前向传播中使用FP16精度,而在反向传播和权重更新时使用FP32精度,以保持数值稳定性。
-
性能提升:利用FP16的紧凑性,可以在GPU上并行处理更多的数据,同时减少内存带宽的需求,从而提升计算性能。
-
硬件支持:现代GPU如NVIDIA的Volta和Turing架构提供了专门的Tensor Core,这些核心专为FP16的矩阵运算而设计,大幅提升了混合精度训练的效率。
-
库与框架支持:深度学习框架如PyTorch和TensorFlow提供了混合精度训练的API,简化了实现过程。例如,PyTorch中的
torch.cuda.amp模块。
4.2 混合精度训练对大模型性能的影响
混合精度训练对大模型性能的影响是多方面的,具体包括:
-
训练速度:使用FP16可以显著减少模型参数和中间数据的存储需求,加速训练过程。研究表明,混合精度训练可以提升训练速度达2倍。
-
内存使用:FP16相比于FP32,内存占用减少一半,使得在有限的硬件资源下可以训练更大的模型。
-
数值稳定性:虽然FP16的数值范围较小,但在适当的技术处理下,如梯度缩放,可以避免数值下溢和上溢的问题。
-
模型精度:大多数研究表明,混合精度训练不会对模型的最终精度产生负面影响。在某些情况下,由于数值噪声的引入,甚至可能有助于提高模型的泛化能力。
-
硬件兼容性:并非所有硬件都支持FP16运算,因此在选择混合精度训练前需要考虑硬件的兼容性和支持程度。
-
实现复杂度:混合精度训练需要对现有的训练代码进行一定程度的修改,以适应精度转换和数值稳定性的处理,这可能会增加实现的复杂度。
总之,大模型的发展推动了对算力技术的需求和创新。从FP16和FP32的精度选择,到算力需求与供给的分析,再到应用场景下的算力考量,以及算力技术的创新与突破,我们可以看到,算力作为AI发展的基石,正面临着前所未有的挑战和机遇。未来,随着技术的不断进步和创新,算力的提供和管理将更加智能化、高效化,为大模型乃至整个人工智能领域的发展提供坚实的支撑。