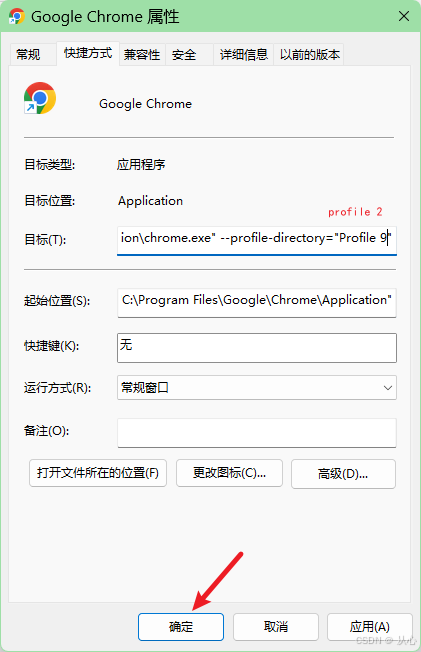
实验记录,在做XX得分预测的实验中,做了一个基于Python的3D聚类图,水平有限,仅供参考。
一、以实现三个类别聚类为例
代码:
import pandas as pd
import numpy as np
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 读取数据
data = pd.read_csv('E:\\shujuji\\Goods\\man.csv')
# 选择用于聚类的列
features = ['Weight', 'BMI', 'Lung Capacity Score', '50m Running Score',
'Standing Long Jump Score', 'Sitting Forward Bend Score',
'1000m Running Score', 'Pulling Up Score', 'Total Score']
X = data[features]
# 处理缺失值
imputer = SimpleImputer(strategy='mean')
X_imputed = imputer.fit_transform(X)
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_imputed)
# 应用PCA降维到3维
pca = PCA(n_components=3)
X_pca = pca.fit_transform(X_scaled)
# 执行K-means聚类
# 假设我们想要3个聚类
kmeans = KMeans(n_clusters=9, random_state=0).fit(X_pca)
labels = kmeans.labels_
# 将聚类标签添加到原始DataFrame中
data['Cluster'] = labels
# 3D可视化聚类结果
fig = plt.figure(1, figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
unique_labels = set(labels)
colors = ['r', 'g', 'b']
for k, c in zip(unique_labels, colors):
class_member_mask = (labels == k)
xy = X_pca[class_member_mask]
ax.scatter(xy[:, 0], xy[:, 1], xy[:, 2], c=c, label=f'Cluster {k}')
ax.set_title('PCA of Fitness Data with K-means Clustering')
ax.set_xlabel('Principal Component 1')
ax.set_ylabel('Principal Component 2')
ax.set_zlabel('Principal Component 3')
plt.legend()
plt.show()
# 打印每个聚类的名称和对应的数据点数量
cluster_centers = kmeans.cluster_centers_
for i in range(3):
cluster_data = data[data['Cluster'] == i]
print(f"Cluster {i}: Count: {len(cluster_data)}")
# 评估聚类效果
from sklearn import metrics
print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X_pca, labels))
实现效果:

二、实现3个聚类以上,以9个类别聚类为例
import pandas as pd
import numpy as np
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 读取数据
data = pd.read_csv('E:\\shujuji\\Goods\\man.csv')
# 选择用于聚类的列
features = ['Weight', 'BMI', 'Lung Capacity Score', '50m Running Score',
'Standing Long Jump Score', 'Sitting Forward Bend Score',
'1000m Running Score', 'Pulling Up Score', 'Total Score']
X = data[features]
# 处理缺失值
imputer = SimpleImputer(strategy='mean')
X_imputed = imputer.fit_transform(X)
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_imputed)
# 应用PCA降维到3维
pca = PCA(n_components=3)
X_pca = pca.fit_transform(X_scaled)
# 执行K-means聚类
# 假设我们想要9个聚类
kmeans = KMeans(n_clusters=9, random_state=0).fit(X_pca)
labels = kmeans.labels_
# 将聚类标签添加到原始DataFrame中
data['Cluster'] = labels
# 3D可视化聚类结果
fig = plt.figure(1, figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
unique_labels = set(labels)
colors = ['r', 'g', 'b', 'c', 'm', 'y', 'k', 'orange', 'purple']
for k, c in zip(unique_labels, colors):
class_member_mask = (labels == k)
xy = X_pca[class_member_mask]
ax.scatter(xy[:, 0], xy[:, 1], xy[:, 2], c=c, label=f'Cluster {k}')
ax.set_title('PCA of Fitness Data with K-means Clustering')
ax.set_xlabel('Principal Component 1')
ax.set_ylabel('Principal Component 2')
ax.set_zlabel('Principal Component 3')
plt.legend()
plt.show()
# 打印每个聚类的名称和对应的数据点数量
cluster_centers = kmeans.cluster_centers_
for i in range(9):
cluster_data = data[data['Cluster'] == i]
print(f"Cluster {i}: Count: {len(cluster_data)}")
# 评估聚类效果
from sklearn import metrics
print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X_pca, labels))
实现效果;