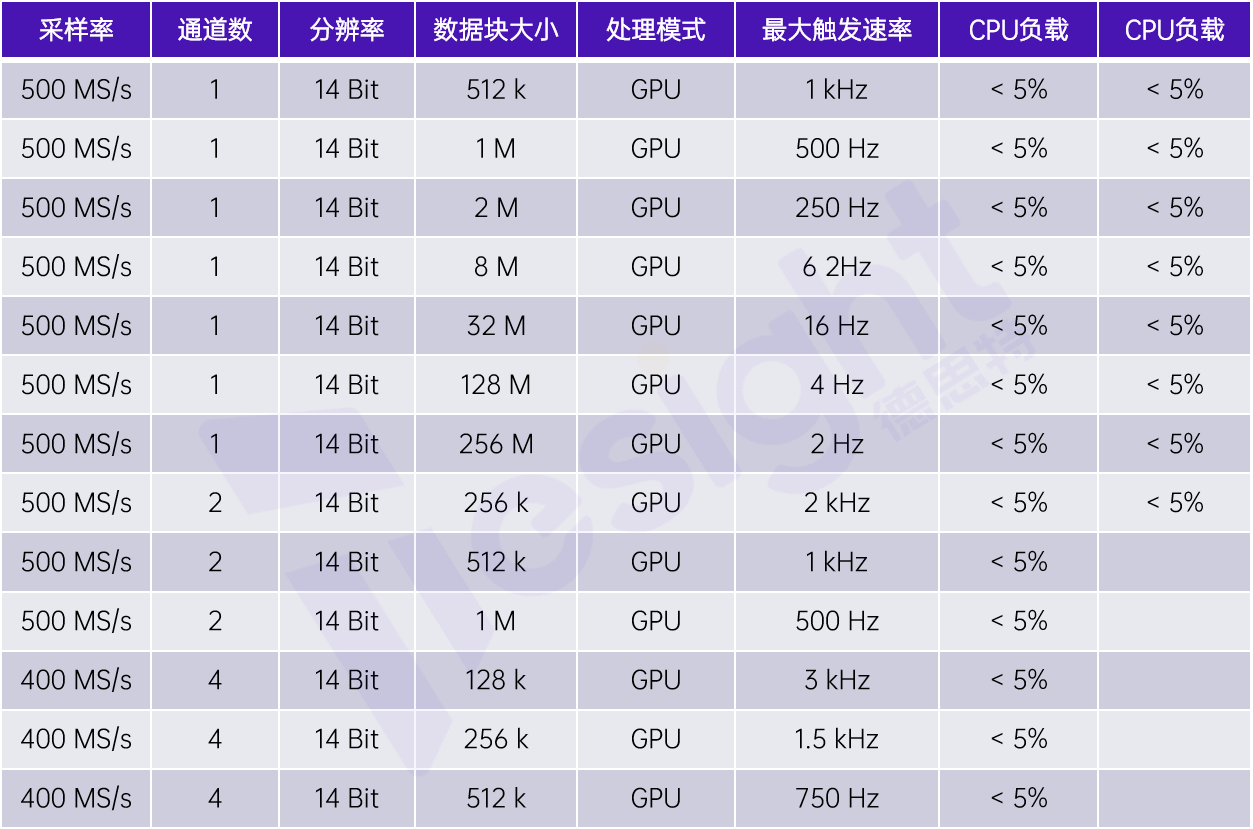
1.整体框架
2.并行模式
1.数据并行DDP

数据切分以后,分开单张卡训练得到参数,然后综合在单卡计算。
要点:前向计算和反向计算两步骤走并汇总。
1.前向计算
需要留一块主卡一定空间用于综合。
2.反向传播
利用前向传播的汇总参数得到各个卡对应数据的损失函数,从而得到梯度的值,分发到每一块卡上,然后每块卡分别做梯度反向推理,然后把梯度结果汇总到gpu1.

2.模型并行
1.层间并行pipeline(梯度切分):
计算每个sample的一层后就推送到下一块卡。

2.层内并行:
层内多头注意力机制参数多卡分开计算。

3.混合并行

服务器之间利用nvlink通信。
优化器状态切分(Optimizer State Partitioning)是一种并行训练的技术,它通常与模型并行(Model Parallelism)和数据并行(Data Parallelism)相结合使用,特别是在 DeepSpeed 的 Zero Stages 中。
Stages 2:梯度分片:pipeline;
Stages 3:参数分片:tensor;
zero-offload:存储移到内存暂存。降低速度。
zero-infinity:无限拓展,存储移动到固态上,NVMe上接的固态。
笔记来源:笔记知识来源